Trong thời đại dữ liệu lớn và ứng dụng thời gian thực, nhu cầu về hệ thống lưu trữ key-value hiệu suất cao ngày càng cấp thiết. Từ đó, RocksDB ra đời năm 2012 tại Facebook (nay là Meta), như là 1 fork của LevelDB từ Google, nhằm khắc phục hạn chế xử lý workload lớn trên SSD, tối ưu độ trễ thấp và nén dữ liệu. Sau hơn 1 thập kỷ, nó trở thành nền tảng cho MyRocks, Kafka Streams và nhiều hệ thống phân tán khác. Bài viết hôm nay sẽ khám phá kiến trúc, ưu nhược điểm cùng ứng dụng thực tế của RocksDB.
RocksDB: Công cụ lưu trữ siêu tốc và ứng dụng trong an ninh thông tin
RocksDB là một công cụ lưu trữ nhúng hiệu suất cao phát triển bởi Facebook. RocksDB ra đời dưới dạng 1 nhánh của LevelDB, một công cụ lưu trữ được Google phát triển và nhúng trong Google’s Big Table. Nó tối ưu hóa cho các phần cứng lưu trữ flash và SSD, dựa trên cấu trúc “Log Structured Merge Trees” - LSM Trees. Và RocksDB có 3 điểm mạnh chính: Embeddable (nhúng được), Tùy chỉnh được (Customizable) và Hiệu suất cao (Performant).
Công cụ lưu trữ nhúng
RocksDB không phải là cơ sở dữ liệu đầy đủ như MySQL hay PostgreSQL, mà là một công cụ lưu trữ key-value nhúng, nghĩa là nó chạy trực tiếp bên trong process của ứng dụng, dễ dàng tích hợp vào ứng dụng hoặc cơ sở dữ liệu khác. Bằng cách nhúng trực tiếp vào máy chủ ứng dụng, RocksDB loại bỏ độ trễ mạng, đơn giản hóa kiến trúc, và tối ưu lưu trữ cục bộ cho thiết bị hạn chế tài nguyên.
Độ trễ thấp: Truy cập dữ liệu nhanh hơn nhờ bỏ qua giao tiếp mạng, phụ thuộc chủ yếu vào tốc độ I/O.
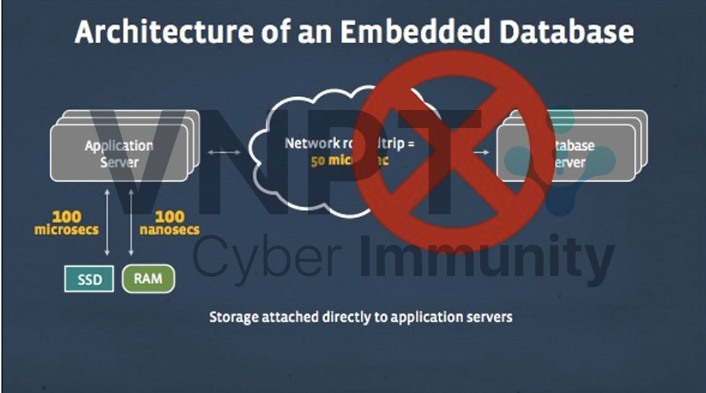
Kiến trúc đơn giản: Thúc đẩy thiết kế monolith, giảm phức tạp so với microservices.
Dữ liệu cục bộ: Hiệu quả cho thiết bị biên với băng thông hạn chế.
Meta có một bài nói chuyện tuyệt vời trên YouTube về cách thiết kế RocksDB, giải thích lý do đằng sau việc làm cho dự án này trở nên nhúng được.
Tùy chỉnh đến từng chi tiết
RocksDB nổi bật với khả năng tùy chỉnh linh hoạt, cho phép thay thế mọi thành phần như Memtable, SSTable, hay thuật toán nén. Bạn có thể điều chỉnh cách dữ liệu chuyển từ bộ nhớ sang đĩa, tối ưu hóa nén dữ liệu, và giảm độ khuếch đại đọc/ghi. Tính linh hoạt này khiến RocksDB phù hợp cho nhiều ứng dụng, từ lưu trữ đơn giản đến xử lý luồng thời gian thực.
Ứng dụng đa dạng: Được sử dụng trong Kafka Streams, Apache Flink, và các cơ sở dữ liệu như MyRocks (Meta) hay TiKV.
Hiệu suất cao
RocksDB, dựa trên LSM Trees, mang lại tốc độ cao, đặc biệt khi sử dụng trên ổ SSD và flash. Kiến trúc LSM Trees được tối ưu cho các tác vụ đọc/ghi lớn, lý tưởng cho ứng dụng cần xử lý dữ liệu nhanh. So với LevelDB, RocksDB cải tiến với các tính năng nâng cao hiệu suất.
Ví dụ, RocksDB sử dụng Bloom filters, một cấu trúc dữ liệu xác suất giúp nhanh chóng xác định liệu một khóa có thể tồn tại trong một tệp (SSTable) trước khi thực hiện tìm kiếm trên tệp đó, giúp giảm các thao tác I/O không cần thiết cho các khóa không tồn tại. Một ví dụ khác là việc tận dụng tính đồng thời. RocksDB tận dụng CPU đa lõi để thực hiện các thao tác đọc và ghi đồng thời mà không bị chậm trễ nhiều, mang lại lợi thế lớn so với các cơ sở dữ liệu dựa trên LSM Trees trước đây như LevelDB, vốn chỉ hoạt động trên một luồng.
Kiến trúc RocksDB
Bây giờ, chúng ta sẽ đi sâu hơn vào cách RocksDB hoạt động bên trong và giải thích một số khái niệm về LSM Trees, cấu trúc dữ liệu nền tảng của RocksDB. Sau đó, chúng ta sẽ trình bày một số điểm khác biệt mà RocksDB thực hiện và cách nó cải tiến so với LevelDB.
LevelDB Core
RocksDB kế thừa nhiều từ LevelDB, một công cụ lưu trữ của Google ra mắt năm 2011, được thiết kế dựa trên BigTable và sử dụng LSM Trees làm nền tảng. Dù là nền tảng cho các hệ thống LSM nhanh như RocksDB, LevelDB bị hạn chế bởi thiếu hỗ trợ xử lý song song và độ khuếch đại ghi cao do cách lưu trữ dữ liệu. RocksDB đã cải tiến những vấn đề này, mang lại hiệu suất vượt trội, như sẽ được trình bày chi tiết trong các phần sau.
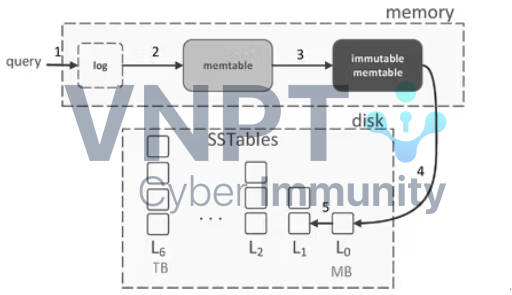
Giới thiệu ngắn về LSM Trees
Các cơ sở dữ liệu quan hệ truyền thống sử dụng B-trees (hoặc B+ trees) để lưu trữ và lập chỉ mục dữ liệu, phù hợp cho đọc nhưng gây tốn kém khi ghi do cách cân bằng và cập nhật cây. Với ứng dụng ghi nhiều, LSM Trees (Cây Hợp nhất Có Cấu trúc Nhật ký) là lựa chọn tối ưu, mang lại độ trễ ghi thấp và thông lượng cao.
LSM Trees tổ chức dữ liệu bằng cách ghi cập nhật vào Memtable trong bộ nhớ, sau đó chuyển sang đĩa dưới dạng các tệp SSTable bất biến, sắp xếp tuần tự giống nhật ký ghi trước (WAL), giảm I/O và tăng hiệu suất ghi. Dữ liệu không được sửa trực tiếp; thay vào đó, cập nhật hoặc xóa được ghi dưới dạng mục mới. Các SSTable cũ được hợp nhất và nén định kỳ để loại bỏ dữ liệu lỗi thời, tối ưu không gian và hiệu quả. Dưới đây là một ví dụ về LSM Tree từ một video tuyệt vời của bytebytego về chủ đề này.
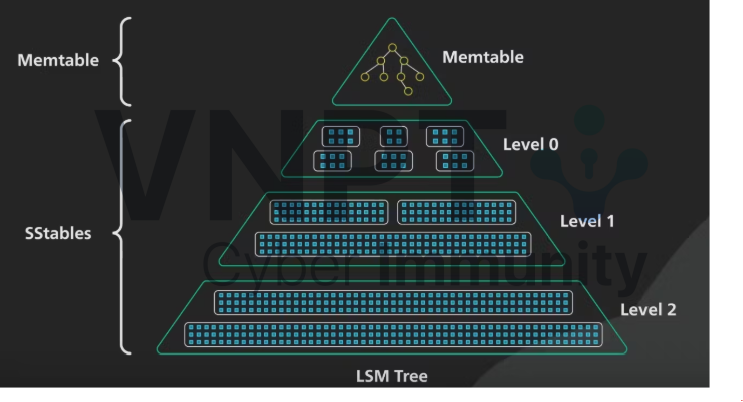
Ba thành phần cốt lõi của LSM Trees:
Memtables: Cấu trúc dữ liệu trong bộ nhớ, hoạt động như bộ đệm, cho phép ghi và đọc nhanh. Mọi truy vấn đến RocksDB đều kiểm tra Memtable trước. Dữ liệu được giữ trong bộ nhớ đến khi đạt ngưỡng (4MB trong LevelDB), rồi chuyển thành SSTable trên đĩa.
SSTable: Các tệp bất biến, được sắp xếp trên đĩa, tương tự nhật ký ghi trước, xuất hiện trong BigTable và HBase. Ghi thường xuyên tạo ra nhiều SSTable, một số chứa dữ liệu lỗi thời, cần được xử lý qua nén.
Nén (Compaction): Quá trình hợp nhất các SSTable, loại bỏ dữ liệu lỗi thời và sắp xếp lại để tối ưu không gian và hiệu suất. RocksDB mặc định dùng nén theo tầng (Tiered Compaction), trong khi LevelDB sử dụng nén theo cấp (Levelled Compaction).
Nén trong RocksDB
RocksDB sử dụng LSM Trees làm nền tảng, thực hiện nén định kỳ với cách tiếp cận dựa trên cấp độ, khác với nén theo tầng đơn giản. Thay vì chuyển dữ liệu từ Memtable trực tiếp thành SSTable trên đĩa, RocksDB tổ chức dữ liệu theo các cấp có thứ tự (Cấp 0, Cấp 1, Cấp 2,...). Dữ liệu từ Memtable được ghi vào Cấp 0, và khi đạt ngưỡng kích thước, nó được hợp nhất vào Cấp 1 với ngưỡng lớn hơn, tối ưu hóa không gian và hiệu suất, như minh họa trong wiki RocksDB.
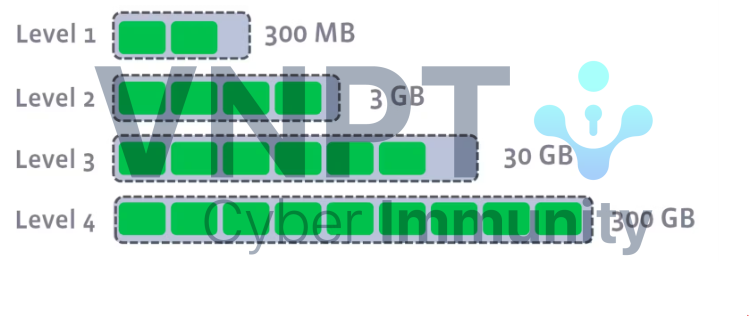
Một cải tiến quan trọng của RocksDB là khả năng thực hiện nén song song, tăng tốc quá trình trên các hệ thống có CPU đa lõi; số lượng công việc nén đồng thời cũng có thể được điều chỉnh trong cấu hình RocksDB.
Không giống như LSM Trees tiêu chuẩn, nơi nén bắt đầu khi SSTable đạt đến một kích thước nhất định, RocksDB cho phép cách tiếp cận linh hoạt hơn để kích hoạt nén. Nó có thể sử dụng giới hạn kích thước tiêu chuẩn làm yếu tố kích hoạt hoặc theo dõi các số liệu khác. Ví dụ, nếu nhận thấy độ khuếch đại ghi trở nên quá cao, có thể là lúc cần kích hoạt nén để giảm dữ liệu trên đĩa. RocksDB cho phép người dùng cấu hình các cài đặt này để kiểm soát tốt hơn khi nào nén xảy ra. Wiki RocksDB có một mục sâu sắc về nén, bạn có thể đọc nếu muốn hiểu cách hoạt động của quá trình hợp nhất trong công cụ lưu trữ này.
Độ khuếch đại đọc và ghi trong RocksDB
RocksDB tối ưu hóa hiệu suất thông qua việc giảm độ khuếch đại đọc, ghi và không gian. Dưới đây là định nghĩa ngắn gọn:
Độ khuếch đại đọc (Read Amplification): Độ khuếch đại đọc đề cập đến lượng dữ liệu cần được đọc từ bộ nhớ để đáp ứng một yêu cầu đọc đơn lẻ. Nói đơn giản, đó là tỷ lệ giữa lượng dữ liệu đọc từ thiết bị lưu trữ và lượng dữ liệu thực sự được yêu cầu bởi người dùng. Ví dụ, nếu bạn cần đọc 1 KB dữ liệu, nhưng hệ thống cơ sở dữ liệu phải đọc 10 KB từ đĩa để tìm và lấy 1 KB đó, độ khuếch đại đọc là 10x.
Độ khuếch đại ghi (Write Amplification): Tương tự như độ khuếch đại đọc, độ khuếch đại ghi đề cập đến lượng dữ liệu cần được ghi vào đĩa khi thực hiện một thao tác ghi trong cơ sở dữ liệu. Ví dụ, nếu chúng ta ghi 1 KB dữ liệu vào cơ sở dữ liệu và điều này dẫn đến 8 KB được ghi vào đĩa do việc di chuyển và ghi lại dữ liệu, độ khuếch đại ghi là 8x.
Độ khuếch đại không gian (Space Amplification): Độ khuếch đại không gian đề cập đến lượng chi phí lưu trữ bổ sung cần thiết ngoài kích thước thô của dữ liệu. Chi phí này có thể đến từ các chỉ mục, siêu dữ liệu và dữ liệu lỗi thời.
Thông thường, chỉ có thể tối ưu hóa hai trong ba yếu tố trên. Và trong bài viết này, ta sẽ tập trung hơn vào độ khuếch đại đọc và ghi.
Tuổi thọ của các SSD hiện đại bị giới hạn bởi một số chu kỳ ghi nhất định, vì vậy độ khuếch đại ghi cao đồng nghĩa với nhiều chu kỳ ghi hơn, điều này trực tiếp làm giảm tuổi thọ của SSD. Đây là một vấn đề quan trọng trong các hệ thống lưu trữ và nhiều nhà nghiên cứu đang nghiên cứu vấn đề này. Lý do đằng sau sự hao mòn này liên quan đến cách các cổng NAND, một phần quan trọng của SSD, thực hiện ghi. Chi tiết kỹ thuật về cách xảy ra sự hao mòn này nằm ngoài phạm vi của bài viết, nhưng đây là một bài giải thích tuyệt vời từ Jim Handy, một chuyên gia về SSD.
Các cơ sở dữ liệu và công nghệ lưu trữ cung cấp độ khuếch đại ghi thấp luôn được ưu tiên, đặc biệt trong các hệ thống sử dụng bộ nhớ flash hoặc SSD làm lưu trữ chính.
RocksDB giảm độ khuếch đại đọc và ghi như thế nào
RocksDB tối ưu hóa hiệu suất bằng cách giảm độ khuếch đại đọc (RA) và ghi (WA):
Giảm độ khuếch đại ghi: RocksDB sử dụng nén phổ quát (universal compaction), giảm WA gấp 7 lần so với LevelDB, nhờ tổ chức dữ liệu hiệu quả hơn. Kỹ thuật này, lấy cảm hứng từ Apache HBase, được cải tiến thêm trong các phiên bản mới để tối ưu hóa ghi.
Giảm độ khuếch đại đọc: Bộ lọc Bloom giúp nhanh chóng xác định khóa có trong tệp SSTable hay không, giảm số lần đọc đĩa không cần thiết. Ngoài ra, nén theo cấp độ giảm số lượng tệp trên đĩa, giúp truy cập dữ liệu nhanh hơn.
Một số tính năng khác
RocksDB không chỉ mạnh mẽ và linh hoạt mà còn cung cấp các tính năng hữu ích, hỗ trợ tối ưu cho ứng dụng bảo mật:
Column Families: Cho phép nhóm dữ liệu thành các tập hợp riêng biệt, mỗi tập có cấu hình riêng như chiến lược nén hay bộ lọc Bloom. Ví dụ, tách dữ liệu truy cập thường xuyên và không thường xuyên để tối ưu hiệu suất.
Compaction Filters: Người dùng có thể tự viết thuật toán để xóa dữ liệu lỗi thời trong quá trình nén, tiết kiệm không gian và thời gian mà không cần dọn dẹp riêng.
Snapshots: Cung cấp bản sao lưu tại một thời điểm, đảm bảo đọc dữ liệu nhất quán dù LSM Trees thay đổi liên tục do nén. Snapshots cũng hỗ trợ trên nhiều phiên bản RocksDB.
Demo thực tế: Tải và tra cứu 1GB+ mã băm MD5
Cách build: Sử dụng Windows 11 và Visual Studio 2022
Trong phần này, ta sẽ xây dựng 1 chương trình C++ tải tệp final.md5 (>1GB+, chứa ~41.7 triệu mã băm MD5) vào cơ sở dữ liệu RocksDB, tổ chức dữ liệu trong một column family hashes, và hỗ trợ tra cứu tương tác với tốc độ dưới mili-giây.
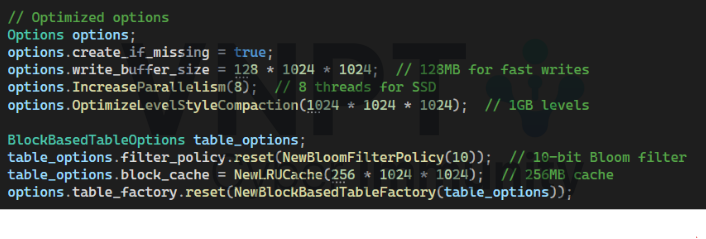
Tối ưu hiệu suất ghi: Bộ đệm ghi 128MB giảm thiểu số lần ghi xuống đĩa, sử dụng 8 luồng song song tận dụng CPU đa nhânnhận, nén theo cấp độđố với ngưỡng 1GB giúp tổ chức dữ liệu trên đĩa thành các cấp, giảm write amplification.
Tăng tốc độ tra cứu với bộ lọc Bloom: Bộ lọc Bloom 10-bit giảm read amplification bằng cách kiểm tra nhanh xem một mã băm có trong SSTable hay không, tránh I/O không cần thiết. Điều này giúp tra cứu các mã không tồn tại (MISS) nhanh hơn đáng kể (~0.02ms). Bộ đệm khối 256MB lưu trữ dữ liệu thường xuyên truy cập trong bộ nhớ, tăng tốc tra cứu HIT (~0.1-2.9ms).

Gọi CompactRange trên column family hashes hợp nhất các SSTable, loại bỏ dữ liệu dư thừa, và tổ chức dữ liệu thành các cấp, giảm kích thước cơ sở dữ liệu (~2.37GB sau nén). Quá trình nén hoàn tất trong ~20.12 giây, thể hiện hiệu quả của nén theo cấp độ.
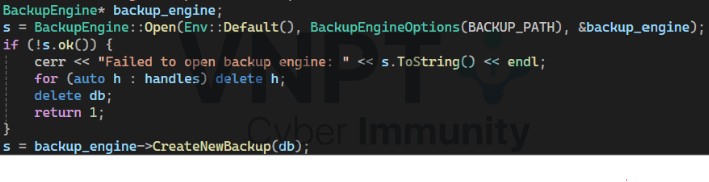
Tính năng sao lưu (CreateNewBackup) tạo snapshot của cơ sở dữ liệu tại C:\Windows\TEMP\rocksdb_ioc_backup, đảm bảo toàn vẹn dữ liệu cho các ứng dụng bảo mật quan trọng, nơi mất dữ liệu IOC có thể gây rủi ro lớn.
Kết quả:
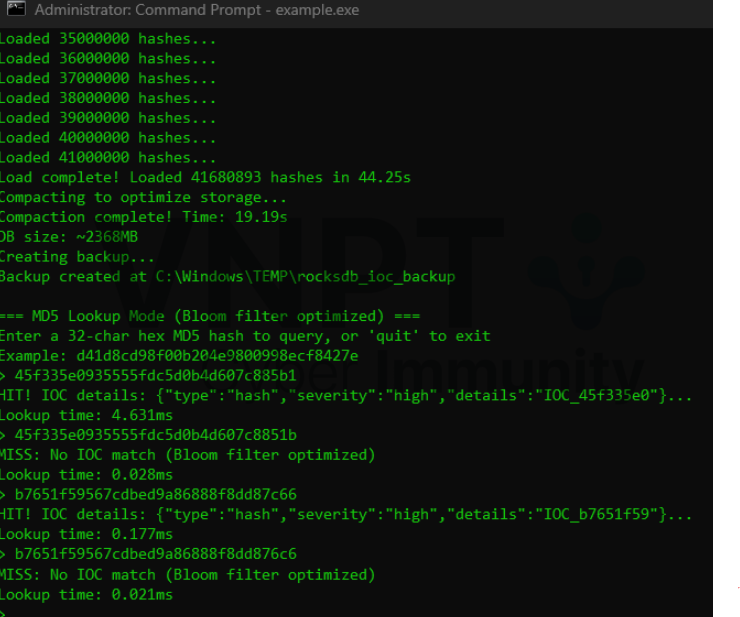
Kết quả cho thấy thời gian tra cứu trung bình ~0.1-0.2ms cho HIT và ~0.02ms cho MISS, với trường hợp HIT chậm nhất (2.920ms) có thể do tải bộ đệm hoặc truy cập đĩa ban đầu.
Với xác suất lỗi dương tính giảgiả dương ~0.84%, trong số ~41.7 triệu mã băm, khi tra cứu một mã không tồn tại, bộ lọc Bloom gần như luôn xác định đúng rằng khóa không có trong SSTable, tránh truy cập đĩa. Điều này giải thích tại sao thời gian tra cứu MISS (~0.02ms) nhanh hơn đáng kể so với HIT (~0.1–2.9ms), vì HIT yêu cầu đọc dữ liệu thực tế từ đĩa hoặc bộ đệm.
Trong kết quả, các tra cứu MISS (ví dụ:45f335e0935555fdc5d0b4d607c8851b, 0.028ms; b7651f59567cdbed9a86888f8dd876c6, 0.021ms) cho thấy bộ lọc Bloom hoạt động hiệu quả, giảm thiểu I/O không cần thiết.
Với ~41.7 triệu khóa, mỗi khóa sử dụng 10 bit, tổng dung lượng bộ lọc Bloom là:

Dung lượng này nhỏ so với bộ đệm khối 256MB, cho phép lưu trữ bộ lọc Bloom trong bộ nhớ, đảm bảo tra cứu nhanh.
Ứng dụng của RocksDB trong an ninh thông tin
RocksDB không chỉ là công cụ lưu trữ hiệu suất cao mà còn đóng vai trò quan trọng trong lĩnh vực an ninh thông tin (cybersecurity), nơi tốc độ tra cứu và độ tin cậy dữ liệu là yếu tố quyết định. Dưới đây là một số ứng dụng thực tiễn nổi bật:
Lưu trữ và tra cứu Indicators of Compromise (IOCs): Như demo trên, RocksDB cho phép lưu trữ hàng triệu mã băm (MD5/SHA) hoặc địa chỉ IP đáng ngờ với thời gian tra cứu dưới mili-giây. Điều này hỗ trợ các công cụ phát hiện malware thời gian thực, giúp hệ thống EDR (Endpoint Detection and Response) nhanh chóng kiểm tra file hoặc kết nối mạng.
Hệ thống SIEM và Log Analysis: Tích hợp với Kafka Streams hoặc Apache Flink, RocksDB xử lý luồng log bảo mật lớn, lưu trữ sự kiện thời gian thực và tra cứu nhanh để phát hiện anomaly. Ví dụ, trong Splunk hoặc ELK Stack, nó giảm độ trễ khi phân tích hàng tỷ sự kiện log hàng ngày.
Threat Intelligence Platforms: Sử dụng column families để phân loại dữ liệu threat feeds (như URL độc hại, signatures), RocksDB hỗ trợ cập nhật động và tra cứu song song. Các nền tảng như MISP hoặc AlienVault OTX tận dụng để lưu trữ dữ liệu tình báo mối đe dọa, tối ưu cho môi trường phân tán.
Edge Computing cho IoT Security: Trên thiết bị biên (như router, sensor), RocksDB nhúng lưu trữ dữ liệu cục bộ để phát hiện xâm nhập mà không cần kết nối đám mây, giảm rủi ro độ trễ mạng và tiết kiệm băng thông.
Backup và Recovery cho Dữ liệu Bảo mật: Tính năng snapshots và compaction filters đảm bảo sao lưu nhất quán, hữu ích trong các hệ thống như antivirus hoặc firewall, nơi mất dữ liệu có thể dẫn đến lỗ hổng lớn.
Với khả năng tùy chỉnh cao và hiệu suất vượt trội trên SSD, RocksDB đang trở thành lựa chọn hàng đầu cho các giải pháp an ninh thông tin hiện đại, giúp tổ chức đối phó nhanh chóng với các mối đe dọa cyber.
Nhược điểm của RocksDB
Mặc dù mạnh mẽ, RocksDB vẫn tồn tại một số hạn chế lưu ý:
Độ phức tạp cấu hình: Với khả năng tùy chỉnh cao, việc tối ưu cho workload cụ thể đòi hỏi kinh nghiệm, dễ dẫn đến hiệu suất kém nếu cấu hình sai.
Hiệu suất đọc ngẫu nhiên hạn chế: Do dựa trên LSM Trees, đọc ngẫu nhiên có thể chậm hơn so với các hệ thống B-tree, đặc biệt với workload đọc nhiều.
Tiêu tốn bộ nhớ: Memtables và Bloom filters có thể chiếm nhiều RAM, không lý tưởng cho thiết bị tài nguyên hạn chế nếu không điều chỉnh.
Bài viết đến đây có lẽ đã dài, rất cảm ơn mọi người đã theo dõi!!!