8 - FlareAuthenticator
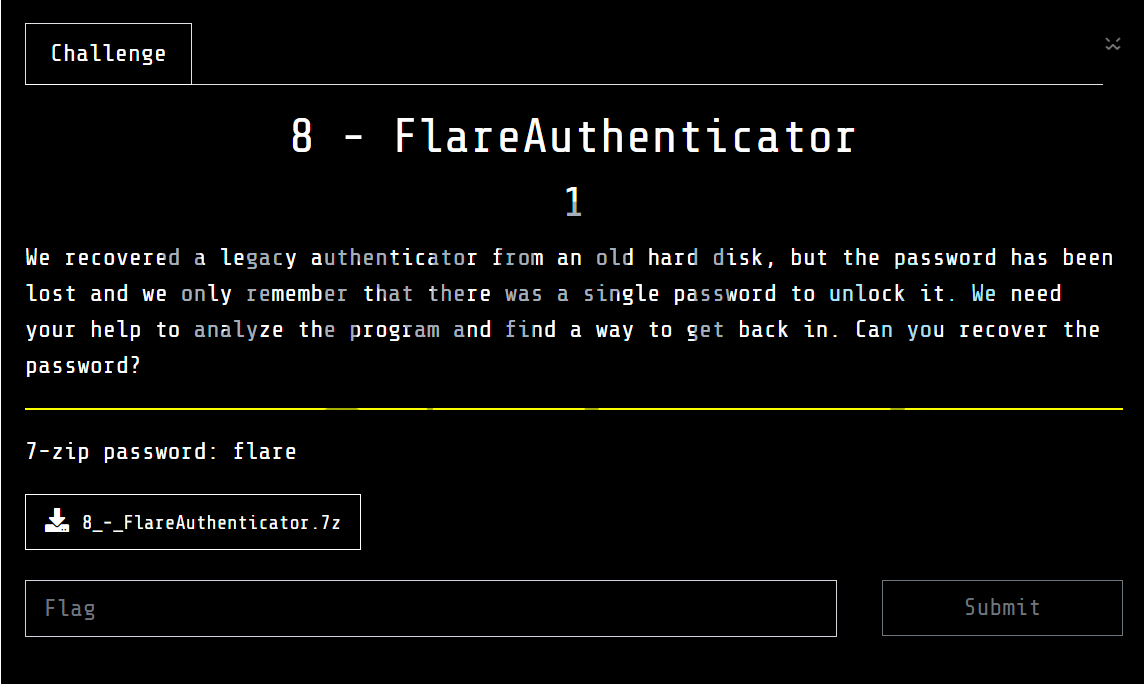
The challenge provides a password checker binary plus several Qt GUI/runtime DLLs:
There is also a .bat file that sets the environment variable QT_QPA_PLATFORM_PLUGIN_PATH to the program’s running directory: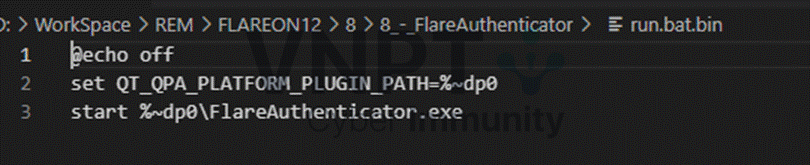
The program detects that environment at runtime and forces you to run the .bat instead of launching the EXE directly. This is trivial to bypass in IDA 9+:
Or you can simply add the environment variable system-wide and run the program directly.
Now, about the program flow. The binary is obfuscated using indirect call and indirect jmp:
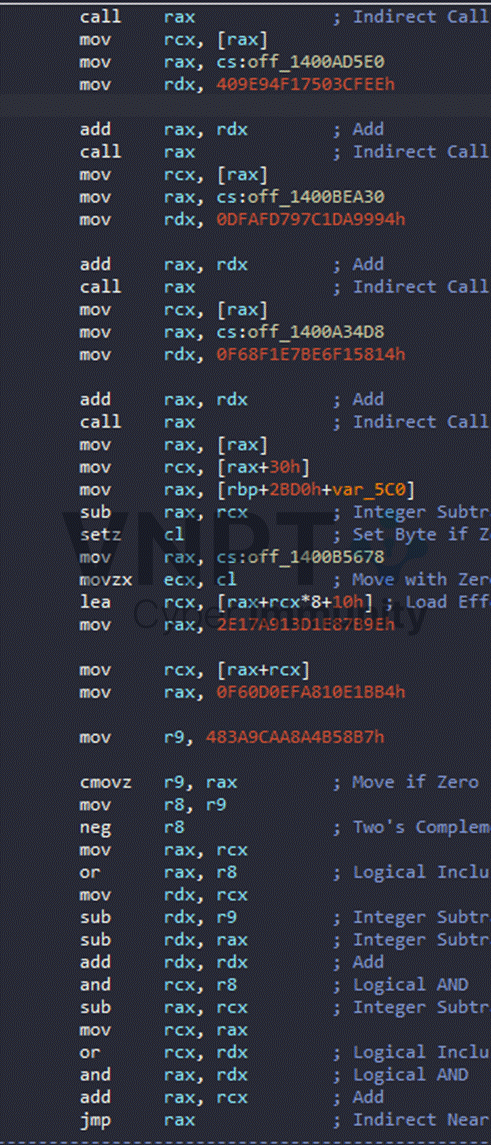
After some probing I observed the obfuscation patterns:
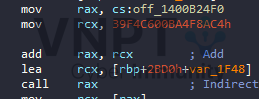
+ For indirect calls, the sequence usually begins with a mov reg64, global_var:
+ For indirect jumps, it often begins with a setz reg8_low followed by mov reg64, global_var:
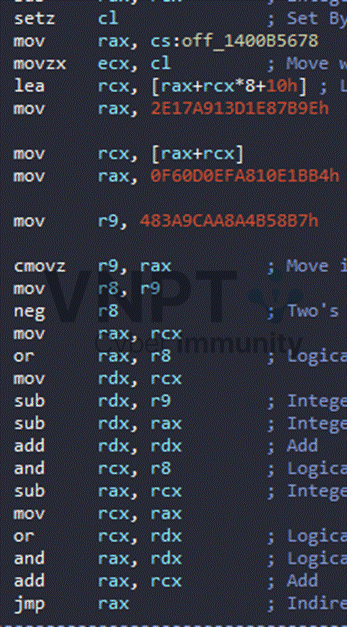
But during debugging, I noticed those jump stubs typically just fall through to the next instruction. So my deobfuscation approach was:
- Match mov reg64, global_var as a start pattern. Walk forward from that start until the nearest call reg64 or jmp reg64. If all instructions in that scanned region use only a set of expected registers (see script), assume the region is obfuscation and deobfuscate it:
![]()
- For indirect jumps: simply NOP the entire region including the leading setz reg8low:
- For indirect calls: take the global_var used in mov reg64, global_var as the initial value, emulate the region with Unicorn, then patch the region into a relative call instruction. If a calling-convention setup (e.g. lea rcx, [mem]) is present, preserve that lea so the patched call keeps the same parameter setup.
Using those heuristics I wrote a somewhat rough IDA/Python script to deobfuscate. The script uses Capstone + Unicorn to emulate and patch:
from capstone import *
from capstone.x86_const import *
import idautils, ida_funcs, idc
import pefile
from unicorn import *
from unicorn.x86_const import *
############### UTILS
def mov_rip_relative(rel32, reg_const, store=False):
REG_MAP = {
X86_REG_RAX: 0, X86_REG_RCX: 1, X86_REG_RDX: 2, X86_REG_RBX: 3,
X86_REG_RSP: 4, X86_REG_RBP: 5, X86_REG_RSI: 6, X86_REG_RDI: 7,
X86_REG_R8: 8, X86_REG_R9: 9, X86_REG_R10: 10, X86_REG_R11: 11,
X86_REG_R12: 12, X86_REG_R13: 13, X86_REG_R14: 14, X86_REG_R15: 15,
}
if reg_const not in REG_MAP:
raise ValueError(f"Unsupported register constant: {reg_const}")
reg = REG_MAP[reg_const]
# REX prefix
rex = 0x48
if reg >= 8:
rex |= 0x04 # set REX.R for extended register (r8–r15)
opcode = 0x89 if store else 0x8B
# ModRM: r/m=101 (RIP-relative), reg=reg & 7
modrm = ((reg & 7) << 3) | 0x05
# Displacement (rel32)
disp = (rel32 & 0xFFFFFFFF).to_bytes(4, "little", signed=False)
return bytes([rex, opcode, modrm]) + disp
def is_mem_base_plus_index(op):
"""Return True if operand is [reg1 + reg2] only (no scale, no disp)."""
return (
op.type == X86_OP_MEM
and op.mem.base in regs
and op.mem.index in regs
and op.mem.scale == 1
and op.mem.disp == 0
)
def is_mov_mem_base_index_reg(insn):
"""Match: mov [reg1 + reg2], reg3"""
if insn.mnemonic != "mov" or len(insn.operands) != 2:
return False
op1, op2 = insn.operands
return is_mem_base_plus_index(op1) and op2.type == X86_OP_REG and op2.reg in regs
def is_mov_reg_mem_base_index(insn):
"""Match: mov reg3, [reg1 + reg2]"""
if insn.mnemonic != "mov" or len(insn.operands) != 2:
return False
op1, op2 = insn.operands
return op1.type == X86_OP_REG and op1.reg in regs and is_mem_base_plus_index(op2)
def mov_reg_rip_rel_uc(uc_reg, disp):
# Map Unicorn register constant → 3-bit reg id (0–15)
reg_map = {
UC_X86_REG_RAX: 0, UC_X86_REG_RCX: 1, UC_X86_REG_RDX: 2, UC_X86_REG_RBX: 3,
UC_X86_REG_RSP: 4, UC_X86_REG_RBP: 5, UC_X86_REG_RSI: 6, UC_X86_REG_RDI: 7,
UC_X86_REG_R8: 8, UC_X86_REG_R9: 9, UC_X86_REG_R10: 10, UC_X86_REG_R11: 11,
UC_X86_REG_R12: 12, UC_X86_REG_R13: 13, UC_X86_REG_R14: 14, UC_X86_REG_R15: 15,
}
reg_id = reg_map[uc_reg]
# REX prefix: REX.W=1, REX.R = bit3(reg_id)
rex = 0x48 | ((reg_id >> 3) & 1)
# opcode
opcode = 0x8B # mov r64, r/m64
# ModRM: mod=00, reg=(reg_id&7), r/m=101b (RIP-relative)
modrm = ((reg_id & 7) << 3) | 0x05
disp_bytes = disp.to_bytes(4, "little", signed=True)
return bytes([rex, opcode, modrm]) + disp_bytes
def calcCallSpacedBytes(startaddr, endaddr, calladdr):
# Compute relative call displacement for an E8 call instruction placed at endaddr
# Note: original logic adjusted by (endaddr - startaddr) etc. Keep same structure,
# but use correct variable names (calladdr).
if calladdr >= startaddr:
relative_addr = calladdr - endaddr
new_relative_addr = relative_addr + (endaddr - startaddr) - 5
return new_relative_addr
elif calladdr <= startaddr:
relative_addr = endaddr - calladdr
new_relative_addr = -relative_addr + (endaddr - startaddr) - 5
return new_relative_addr
return 0
def patch(patchbytes, start_address):
patchbytes = [i for i in patchbytes]
for i in range(len(patchbytes)):
idc.patch_byte(start_address + i, patchbytes[i])
###############
pe = pefile.PE(r"D:\WorkSpace\REM\FLAREON12\8\8_-_FlareAuthenticator\FlareAuthenticator.exe")
text_RVA = 0x1000
DisEngine = Cs(CS_ARCH_X86, CS_MODE_64)
DisEngine.detail = True
EmuEngine = Uc(UC_ARCH_X86, UC_MODE_64)
STACK_ADDR = 0x10000
STACK_SIZE = 0x200000
stacktop = int((STACK_ADDR + STACK_SIZE) / 2)
text_sec = 0
image_base = pe.OPTIONAL_HEADER.ImageBase
for s in pe.sections:
s_va = image_base + s.VirtualAddress
size = max(s.Misc_VirtualSize, s.SizeOfRawData)
# align size to page (0x1000)
map_size = (size + 0xFFF) & ~0xFFF
EmuEngine.mem_map(s_va, max(map_size, 0x1000))
data = s.get_data()
EmuEngine.mem_write(s_va, data)
###############
regs = [
UC_X86_REG_RAX, UC_X86_REG_RBX, UC_X86_REG_RCX, UC_X86_REG_RDX,
UC_X86_REG_RSI, UC_X86_REG_RDI,
UC_X86_REG_RSP, UC_X86_REG_RBP,
UC_X86_REG_R8, UC_X86_REG_R9,
UC_X86_REG_R10, UC_X86_REG_R11, UC_X86_REG_R12, UC_X86_REG_R13,
UC_X86_REG_R14, UC_X86_REG_R15
]
capstone_to_unicorn = {
X86_REG_RAX: UC_X86_REG_RAX,
X86_REG_RBX: UC_X86_REG_RBX,
X86_REG_RCX: UC_X86_REG_RCX,
X86_REG_RDX: UC_X86_REG_RDX,
X86_REG_RSP: UC_X86_REG_RSP,
X86_REG_RBP: UC_X86_REG_RBP,
X86_REG_RSI: UC_X86_REG_RSI,
X86_REG_RDI: UC_X86_REG_RDI,
X86_REG_R8: UC_X86_REG_R8,
X86_REG_R9: UC_X86_REG_R9,
X86_REG_R10: UC_X86_REG_R10,
X86_REG_R11: UC_X86_REG_R11,
X86_REG_R12: UC_X86_REG_R12,
X86_REG_R13: UC_X86_REG_R13,
X86_REG_R14: UC_X86_REG_R14,
X86_REG_R15: UC_X86_REG_R15,
}
REG = ["rax", "rbx", "rcx", "rdx", "rsp", "rbp", "r8", "r9", "r10", "r11", "r12", "r13", "r14", "r15",
"eax", "ebx", "ecx", "edx", "esp", "ebp"]
for section in pe.sections:
name = section.Name.decode(errors="ignore").strip("\x00")
if name == ".text":
text_sec = section.get_data()
EmuEngine.mem_map(STACK_ADDR, STACK_SIZE)
EmuEngine.reg_write(UC_X86_REG_RSP, stacktop)
EmuEngine.reg_write(UC_X86_REG_RBP, stacktop)
dis = DisEngine.disasm(text_sec, image_base + text_RVA)
IS_EMU = False
PATTERN1_MOVZX = False
PATTERN2_LEA = False
PATTERN3_LEA_CALLINGCONV = False
PATTERN4_MBA_JUNK = False
PATTERN_INLING = False
PATTERN5_ASSIGN_REG_MEM = False
PATTERN6_ASSIGN_MEMCALC = False
pattern3addr = 0
nopaddr = 0
rax_init_value = 0
junk = 0
mba_junk = 0
init_reg = ""
pat6_mode = 0
with open("LOG.txt", "w") as f:
for insn in dis:
if insn.bytes == b"\xEB\x00":
to_patch = b"\x90\x90"
patch(to_patch, insn.address)
continue
if insn.mnemonic == "mov":
if insn.op_str.startswith("rax,") or insn.op_str.startswith("rcx,"):
# Check if second operand is an immediate (global address) or RIP-relative memory
if len(insn.operands) == 2:
op2 = insn.operands[1]
if op2.type == CS_OP_MEM and op2.mem.base == X86_REG_RIP:
if insn.op_str.startswith("rax,"):
init_reg = "rax"
else:
init_reg = "rcx"
disp = op2.mem.disp
target = insn.address + insn.size + disp
IS_EMU = True
nopaddr = insn.address
rax_init_value = target
f.write(f"{insn.address:016X}: {insn.mnemonic} {insn.op_str} ; RIP+disp -> {hex(target)}\n")
if IS_EMU:
if any(reg in insn.op_str for reg in REG):
if insn.mnemonic == "lea":
op0 = insn.operands[0]
op1 = insn.operands[1]
if insn.op_str.startswith("rcx, [rax + rcx +"):
PATTERN2_LEA = True
# Protect calling convention
elif op0.type == CS_OP_REG and op1.type == CS_OP_MEM:
if op0.reg == X86_REG_RCX:
if op1.mem.base == X86_REG_RSP or op1.mem.base == X86_REG_RBP:
PATTERN3_LEA_CALLINGCONV = True
pattern3addr = insn.address
elif insn.mnemonic == "mov":
op0 = insn.operands[0]
op1 = insn.operands[1]
if "+" not in insn.op_str:
if op0.type == CS_OP_REG and op1.type == CS_OP_MEM:
if op0.reg in regs and op1.mem.base in regs:
PATTERN5_ASSIGN_REG_MEM = True
elif op1.type == CS_OP_REG and op0.type == CS_OP_MEM:
if op1.reg in regs and op0.mem.base in regs:
PATTERN5_ASSIGN_REG_MEM = True
else:
if PATTERN6_ASSIGN_MEMCALC:
try:
based_value = idc.get_bytes(rax_init_value, 8)
based_value = int.from_bytes(based_value, "little")
child_value = idc.get_bytes(insn.address - 8, 8)
child_value = int.from_bytes(child_value, "little")
summary = (child_value + based_value) & 0xFFFFFFFFFFFFFFFF
rel_val = summary - nopaddr - 7
to_patch = b""
if pat6_mode == 0:
to_patch = mov_rip_relative(rel_val, op1.reg, True)
elif pat6_mode == 1:
to_patch = mov_rip_relative(rel_val, op0.reg, False)
to_patch += b"\x90" * (insn.address - nopaddr - 7)
patch(to_patch, nopaddr)
IS_EMU = False
PATTERN6_ASSIGN_MEMCALC = False
continue
except Exception:
IS_EMU = False
PATTERN6_ASSIGN_MEMCALC = False
continue
if PATTERN5_ASSIGN_REG_MEM:
try:
rax_set = idc.get_bytes(rax_init_value, 8)
rax_set = int.from_bytes(rax_set, "little")
for r in regs:
EmuEngine.reg_write(r, 0)
if init_reg == "rax":
EmuEngine.reg_write(UC_X86_REG_RAX, rax_set)
elif init_reg == "rcx":
EmuEngine.reg_write(UC_X86_REG_RCX, rax_set)
start_addr = nopaddr + 7 # SKIP 7 bytes insn dau
EmuEngine.emu_start(start_addr, insn.address)
regget = 0
to_patch = b""
# create a small disasm for traceback (3 bytes)
traceback_bytes = idc.get_bytes(insn.address - 3, 3)
traceback_ins = DisEngine.disasm(traceback_bytes, insn.address - 3)
for di in traceback_ins:
diop0 = di.operands[0]
regget = EmuEngine.reg_read(capstone_to_unicorn[diop0.reg])
regget = regget - nopaddr - 7
to_patch = mov_reg_rip_rel_uc(diop0.reg, regget)
to_patch += b"\x90" * (insn.address - nopaddr - 7)
patch(to_patch, nopaddr)
IS_EMU = False
PATTERN5_ASSIGN_REG_MEM = False
init_reg = ""
except Exception:
IS_EMU = False
PATTERN5_ASSIGN_REG_MEM = False
init_reg = ""
continue
else:
if insn.mnemonic == "movzx":
PATTERN1_MOVZX = True
IS_EMU = False
if PATTERN1_MOVZX:
IS_EMU = True
PATTERN1_MOVZX = False
junk = 3
if PATTERN2_LEA:
PATTERN2_LEA = False
junk = 3
if insn.mnemonic == "call" or insn.mnemonic == "jmp":
if insn.op_str == "rax":
if insn.mnemonic == "jmp":
patched = b"\x90" * (insn.address + len(insn.bytes) + junk - nopaddr)
patch(patched, nopaddr - junk)
f.write(f"{insn.address:08X} JMP PATCHED from {nopaddr:08X}\n")
else:
rax_set = idc.get_bytes(rax_init_value, 8)
rax_set = int.from_bytes(rax_set, "little")
for r in regs:
EmuEngine.reg_write(r, 0)
if init_reg == "rax":
EmuEngine.reg_write(UC_X86_REG_RAX, rax_set)
elif init_reg == "rcx":
EmuEngine.reg_write(UC_X86_REG_RCX, rax_set)
start_addr = nopaddr + 7 # SKIP 7 bytes insn dau
EmuEngine.emu_start(start_addr, insn.address)
call_rax = EmuEngine.reg_read(UC_X86_REG_RAX)
funccheck = idc.get_bytes(call_rax, 3)
final_rax = calcCallSpacedBytes(nopaddr, insn.address, call_rax)
patched = b"\xe8" + final_rax.to_bytes(4, byteorder="little", signed=True) + b"\x90" * (insn.address + len(insn.bytes) - nopaddr - 5)
if funccheck == b"\x48\x89\xC8":
if idc.get_bytes(call_rax + 3, 1) == b"\xC3":
PATTERN_INLING = True
patched = b"\x48\x89\xC8" + b"\x90" * (insn.address + len(insn.bytes) - nopaddr - 3)
elif idc.get_bytes(call_rax + 7, 1) == b"\xC3":
if idc.get_bytes(call_rax + 3, 3) == b"\x48\x83\xc0":
PATTERN_INLING = True
patched = b"\x48\x89\xC8" + idc.get_bytes(call_rax + 3, 4) + b"\x90" * (insn.address + len(insn.bytes) - nopaddr - 7)
if PATTERN3_LEA_CALLINGCONV:
callconv = idc.get_bytes(pattern3addr, insn.address - pattern3addr)
if PATTERN_INLING:
patched = callconv + patched[:-len(callconv)]
else:
final_rax -= len(callconv)
patched = callconv + b"\xe8" + final_rax.to_bytes(4, byteorder="little", signed=True) + b"\x90" * (insn.address + len(insn.bytes) - nopaddr - 5 - len(callconv))
PATTERN3_LEA_CALLINGCONV = False
PATTERN_INLING = False
patch(patched, nopaddr)
f.write(f"{insn.address:08X} : {insn.mnemonic} {EmuEngine.reg_read(UC_X86_REG_RAX):08X} - SPACING {final_rax:08X}\n")
IS_EMU = False
junk = 0
init_reg = ""
## LAYER 2
dis2 = DisEngine.disasm(text_sec, image_base + text_RVA)
for insn in dis2:
checkb = idc.get_bytes(insn.address, len(insn.bytes))
if checkb == b"\x90" * len(insn.bytes):
continue
if insn.mnemonic == "mov":
if insn.op_str.startswith("rax,") or insn.op_str.startswith("rcx,"):
if len(insn.operands) == 2:
op2 = insn.operands[1]
if op2.type == CS_OP_MEM and op2.mem.base == X86_REG_RIP:
disp = op2.mem.disp
target = insn.address + insn.size + disp
IS_EMU = True
nopaddr = insn.address
rax_init_value = target
if is_mov_mem_base_index_reg(insn):
print(f"PAT6 {insn.address:08X} : [mem(reg+reg),reg] match: {insn.mnemonic} {insn.op_str}")
pat6_mode = 0
PATTERN6_ASSIGN_MEMCALC = True
elif is_mov_reg_mem_base_index(insn):
print(f"PAT6 {insn.address:08X} : [mem(reg+reg),reg] match: {insn.mnemonic} {insn.op_str}")
pat6_mode = 1
PATTERN6_ASSIGN_MEMCALC = True
if IS_EMU:
if any(reg in insn.op_str for reg in REG):
if insn.mnemonic == "mov":
op0 = insn.operands[0]
op1 = insn.operands[1]
if PATTERN6_ASSIGN_MEMCALC:
try:
based_value = idc.get_bytes(rax_init_value, 8)
based_value = int.from_bytes(based_value, "little")
child_value = idc.get_bytes(insn.address - 8, 8)
child_value = int.from_bytes(child_value, "little")
print(f"{based_value:08X}, {child_value:08X}")
summary = (child_value + based_value) & 0xFFFFFFFFFFFFFFFF
rel_val = summary - nopaddr - 7
to_patch = b""
if pat6_mode == 0:
to_patch = mov_rip_relative(rel_val, op1.reg, True)
elif pat6_mode == 1:
to_patch = mov_rip_relative(rel_val, op0.reg, False)
to_patch += b"\x90" * (insn.address - nopaddr - 7)
patch(to_patch, nopaddr)
IS_EMU = False
PATTERN6_ASSIGN_MEMCALC = False
continue
except Exception:
IS_EMU = False
PATTERN6_ASSIGN_MEMCALC = False
continue
print("[+] Done")Even after running the deobfuscator, a lot of MBA-style obfuscation remained, so I combined heuristic guessing with the pseudocode I could recover after deobfuscation :D.
After deobfuscation we can clearly see Qt API calls and other functions: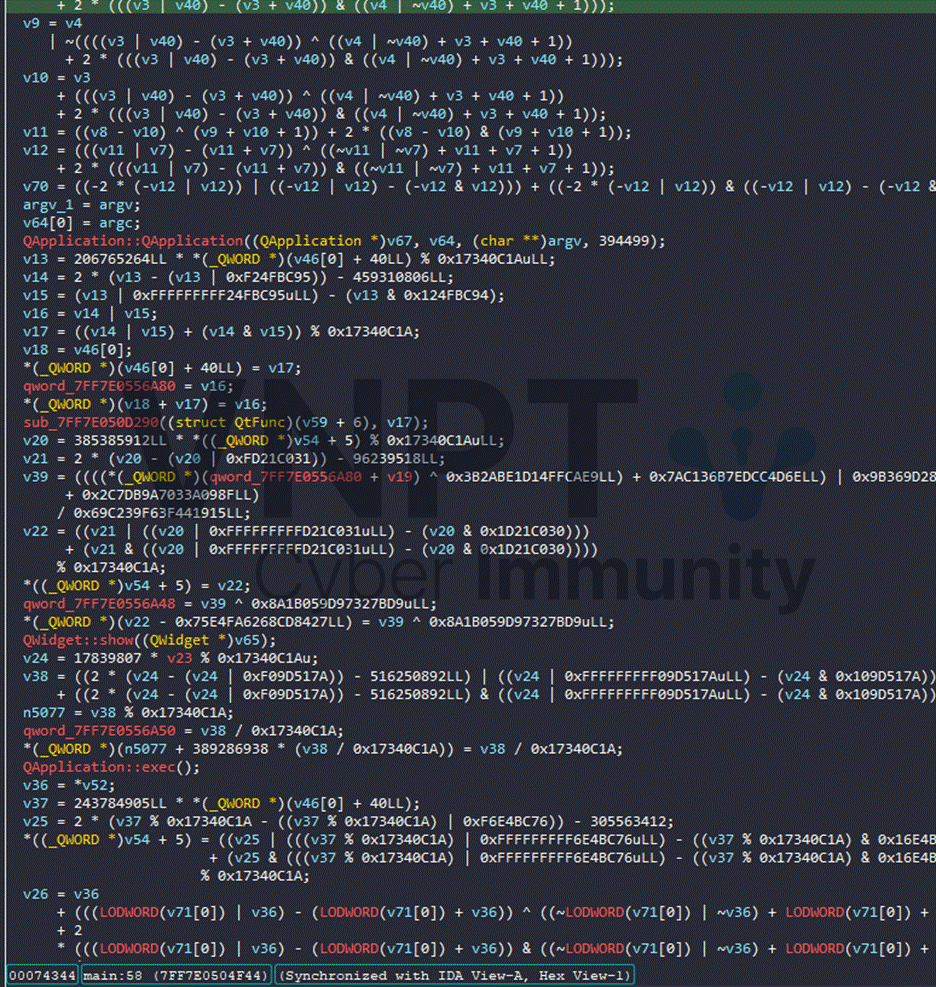
My original plan was to do pure static analysis: read Qt docs, examine imports to identify APIs that accept user input, and then follow xrefs into relevant flows. That turned out to be messy, so I switched to debugging ☹
I set a breakpoint in main after the program had read the input (i.e., after the input-read routine completes), then searched memory for the input string — and surprisingly I found it :v. To be certain, I set a hardware breakpoint at that memory address. After some stepping, we found the exact location that receives input:

When hitting the hardware breakpoint on the input, I observed the program calling a transformation function that mutates the current index and the input byte:
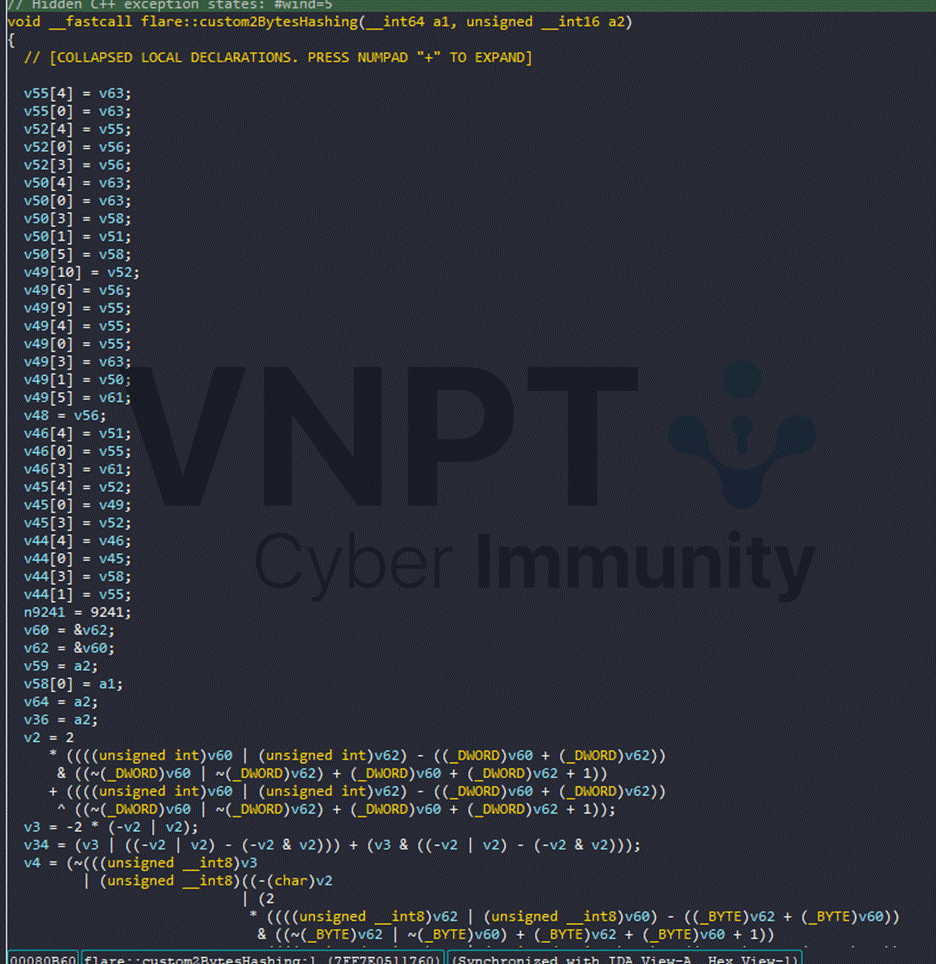
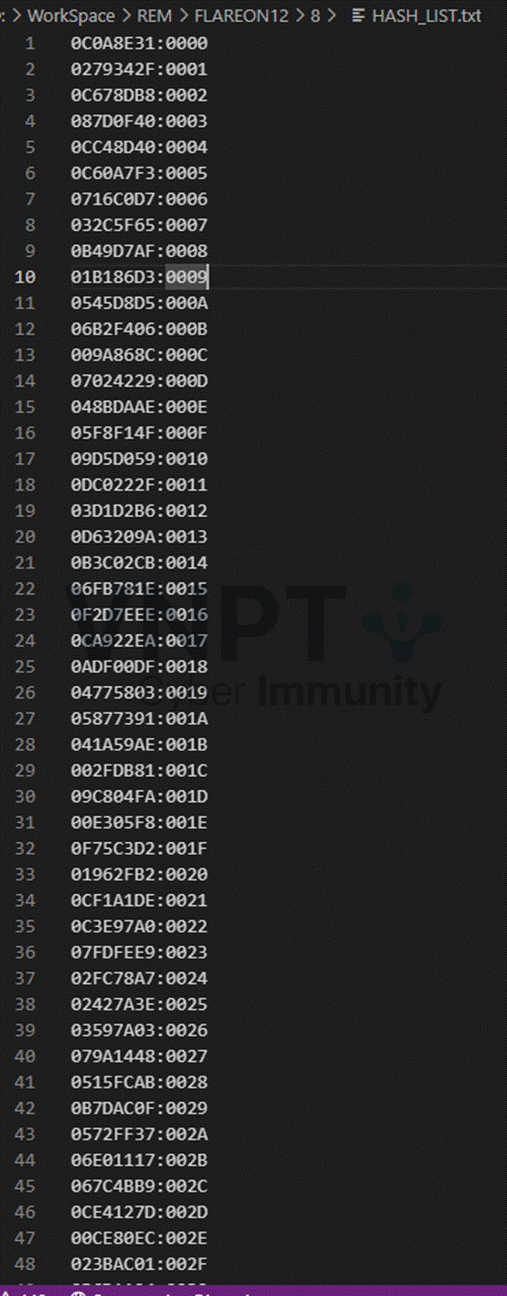
I didn’t want to reverse that helper too deeply, so I used Appcall at the call context to enumerate the mapping. The function accepts two bytes: a password index and the concatenation hex(index) + hex(ascii_char). Practically, we therefore need to know the transformed values for indices/input chars in the range 0x0..0x1939. Running Appcall produced a list of mapped values:
From debugging, inputs are then combined by a sliding sum of products over positions, roughly:
Check = (cusFunc(Input[i]) * cusFunc(i)) + (cusFunc(Input[i + 1]) * cusFunc(i + 1)) + (cusFunc(Input[I + 2]…….This computed Check is compared against the constant 0x0BC42D5779FEC401: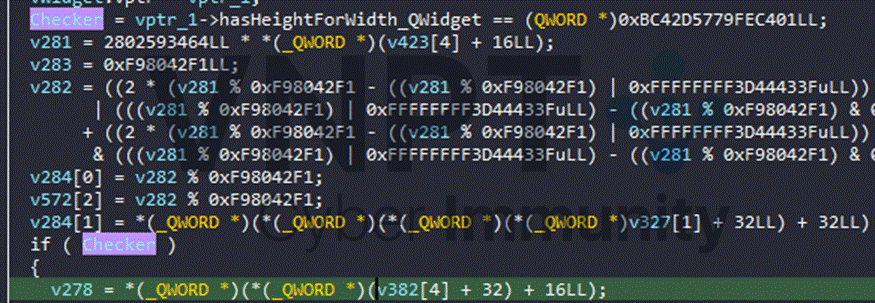
If the check fails, execution branches to show an error message box:
If the check matches, execution proceeds to accept the input password and uses it as the RC4 key:
![]()
The RC4 routine itself was CFF-obfuscated, but it was straightforward to deobfuscate using Hrtng’s plugin:
Once deobfuscated, the password is used as the RC4 key to decrypt a hardcoded byte sequence — that decrypted blob is the flag. The program then shows the flag in an Information message box: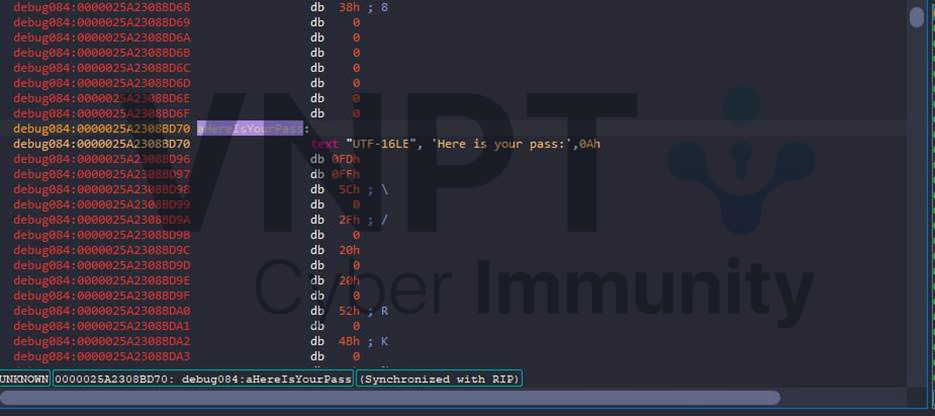

So the remaining task is finding the password. Because we have the 25 positions and the linear combination structure described above, the problem is an excellent fit for Z3. I wrote a quick Z3 script:
# z3_bruteforce_inverted_map.py
# pip install z3-solver
from z3 import BitVec, BitVecVal, Solver, If, Or, sat
from collections import defaultdict
N = 25
MAX_SOLUTIONS = 100
KNOWN_TESTSUM = 0x0BC42D5779FEC401
HASHLIST_PATH = "HASH_LIST.txt"
def normalize_hex(s):
"""Strip whitespace and 0x prefix, return uppercase hex string."""
s = s.strip()
if s.lower().startswith("0x"):
s = s[2:]
return s.upper()
# Read hash list and build mappings
hash_to_plain = {}
plain_to_hashes = defaultdict(list)
with open(HASHLIST_PATH, "r") as f:
for line in f:
line = line.strip()
if not line or ':' not in line:
continue
key, val = line.split(":", 1)
key = normalize_hex(key)
val = normalize_hex(val)
hash_to_plain[key] = val
plain_to_hashes[val].append(key)
# Select first hash for each plaintext
plain_to_hash = {plain: hashes[0] for plain, hashes in plain_to_hashes.items()}
def find_hash_by_plain(need_plain):
"""Find hash by exact or suffix match of plaintext."""
need = need_plain.upper()
if need in plain_to_hash:
return plain_to_hash[need]
for plain, hash_val in plain_to_hash.items():
if plain.endswith(need):
return hash_val
raise KeyError(f"No hash found for plaintext: {need_plain}")
mask64 = (1 << 64) - 1
# Build val_idx: hash values for position indices (1..N)
val_idx = [int(find_hash_by_plain(f"{i+1:04X}"), 16) for i in range(N)]
# Build val_prod_map: precompute (hash * val_idx) for each digit at each position
val_prod_map = []
for i in range(N):
idx = i + 1
per_pos = {}
for digit in range(10):
ascii_code = ord(str(digit))
cvt_str = f"{(idx << 8) + ascii_code:04X}"
hash_hex = find_hash_by_plain(cvt_str)
val_str = int(hash_hex, 16)
prod = (val_str * val_idx[i]) & mask64
per_pos[ascii_code] = prod
val_prod_map.append(per_pos)
# Z3 setup: N bytes constrained to digits '0'..'9'
xs = [BitVec(f"b{i}", 8) for i in range(N)]
s = Solver()
for b in xs:
s.add(b >= ord("0"), b <= ord("9"))
def product_choice_expr(pos_index, bv):
"""Return Z3 expression for product based on digit value at position."""
expr = BitVecVal(0, 64)
for digit in range(10):
ascii_code = ord(str(digit))
const_prod = BitVecVal(val_prod_map[pos_index][ascii_code], 64)
expr = If(bv == ascii_code, const_prod, expr)
return expr
# Constrain sum of products to match known test sum
total = sum((product_choice_expr(i, xs[i]) for i in range(N)), BitVecVal(0, 64))
s.add(total == BitVecVal(KNOWN_TESTSUM & mask64, 64))
# Enumerate solutions
found = 0
while found < MAX_SOLUTIONS and s.check() == sat:
m = s.model()
sol_bytes = [m.eval(b).as_long() for b in xs]
sol_str = "".join(chr(b) for b in sol_bytes)
print(f"Solution #{found+1}: {sol_str}")
s.add(Or([xs[i] != sol_bytes[i] for i in range(N)]))
found += 1
if found == 0:
print("No solutions found.")
else:
print(f"Enumerated {found} solution(s) (max: {MAX_SOLUTIONS}).")Result:
![]()
Enter the password and we got the flag:
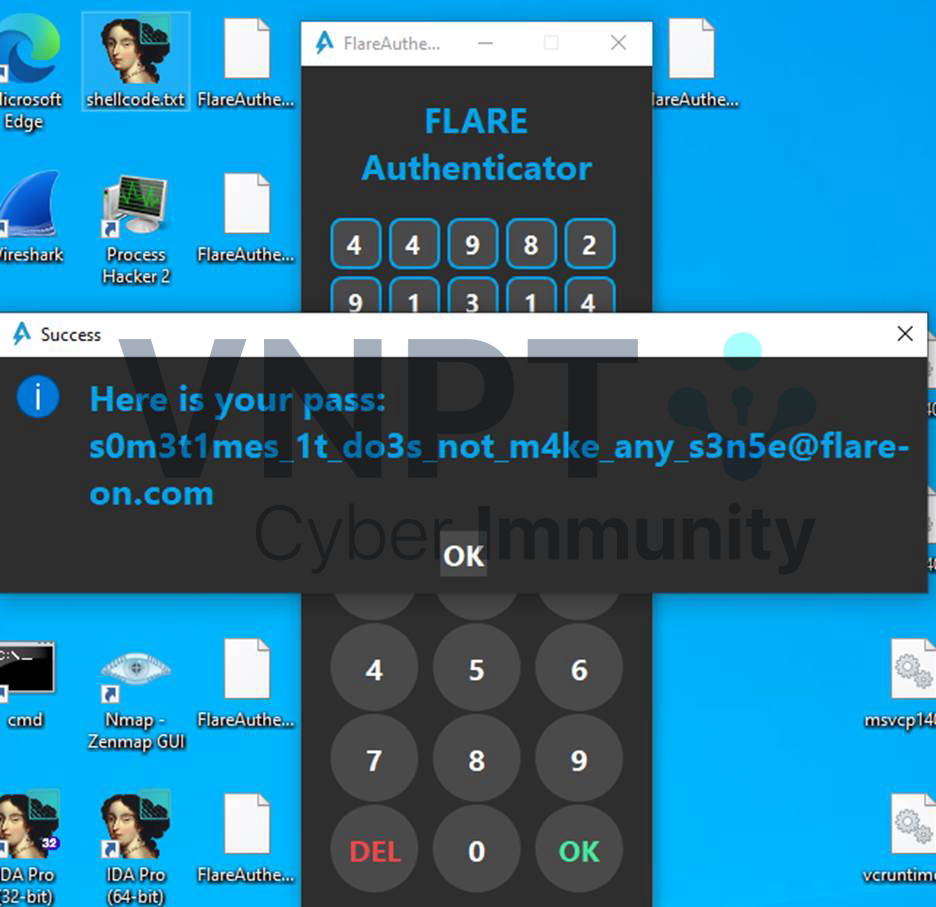
Flag:s0m3t1mes_1t_do3s_not_m4ke_any_s3n5e@flare-on.com
9 - 10000
This challenge gives us a very large executable (1.07 GB) named 10000.exe
![]()
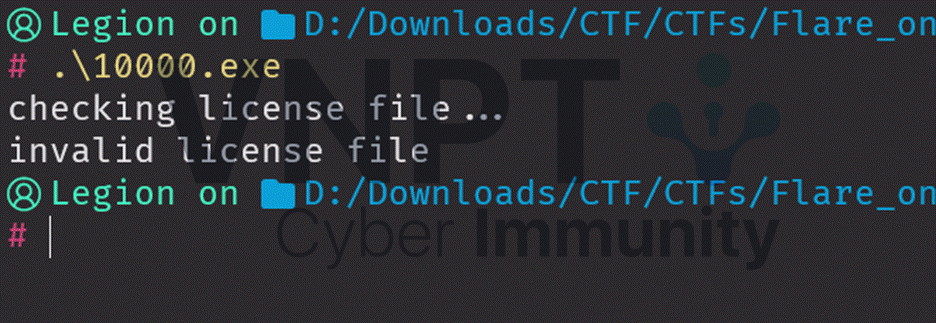
When run, the program requires a license.bin file.
Let's analyze the file in Binary Ninja
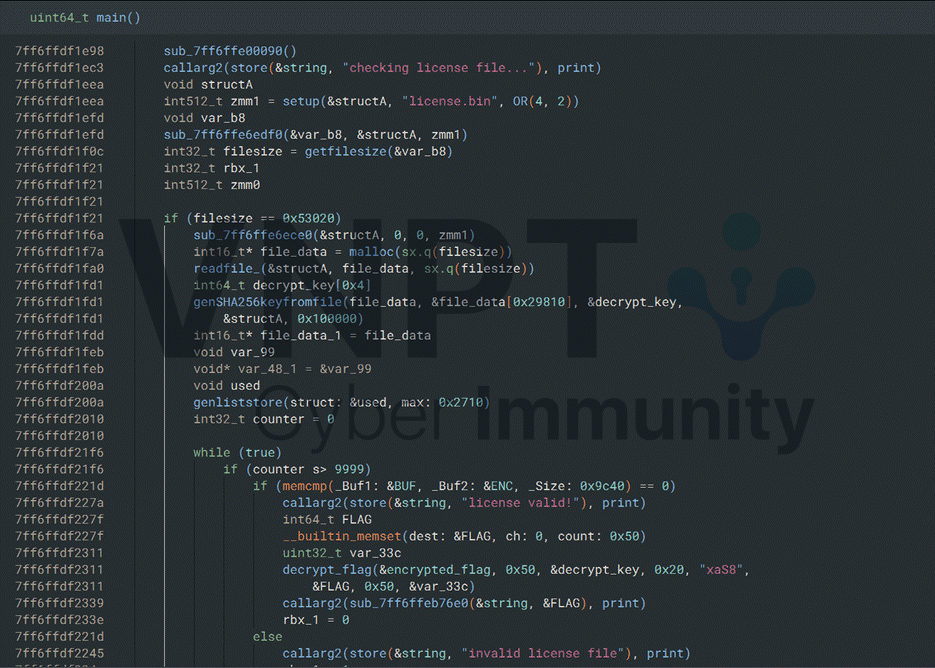
The execution flow is simple:
1/ Check if the size of licence.bin equals 0x53020
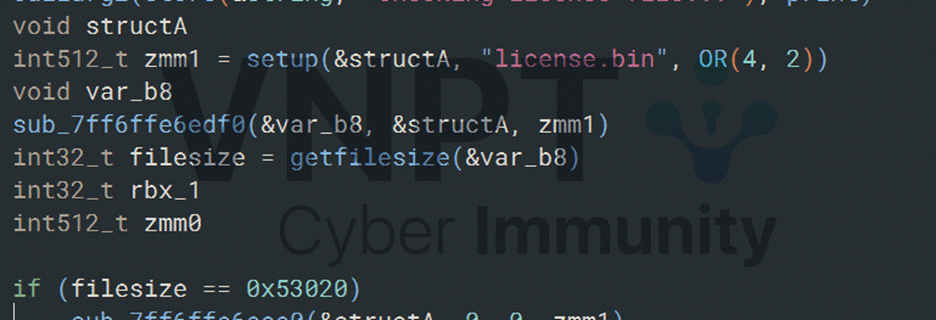
2/ A loop runs with a counter from 0 to 10000. If the counter reaches 10000, the program compares two arrays, each contain 10000 32-bit numbers. If they match, the program computes the SHA256 of the license file and uses it as the AES key to decrypt the flag.
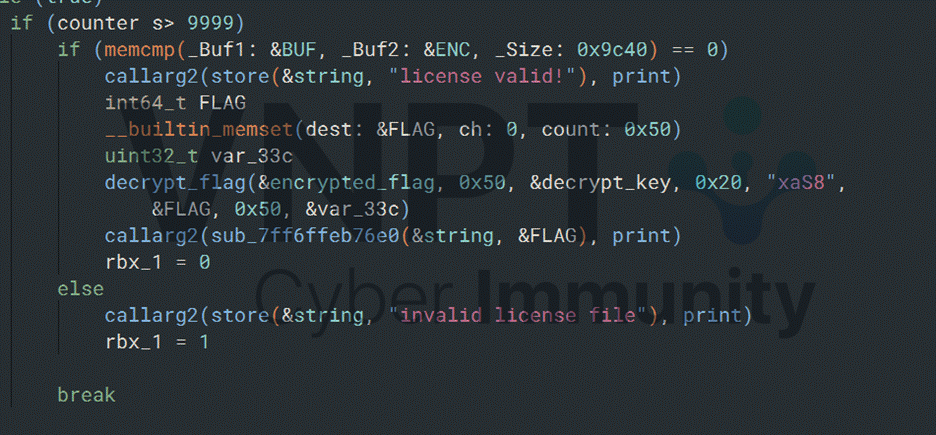
3/ While the counter is still below 10000, the program reads 34-bytes blocks from the license.bin. The first 2 bytes of each block are the dll number, the remaining 32bytes are the argument passed to a check function exported from the dll.
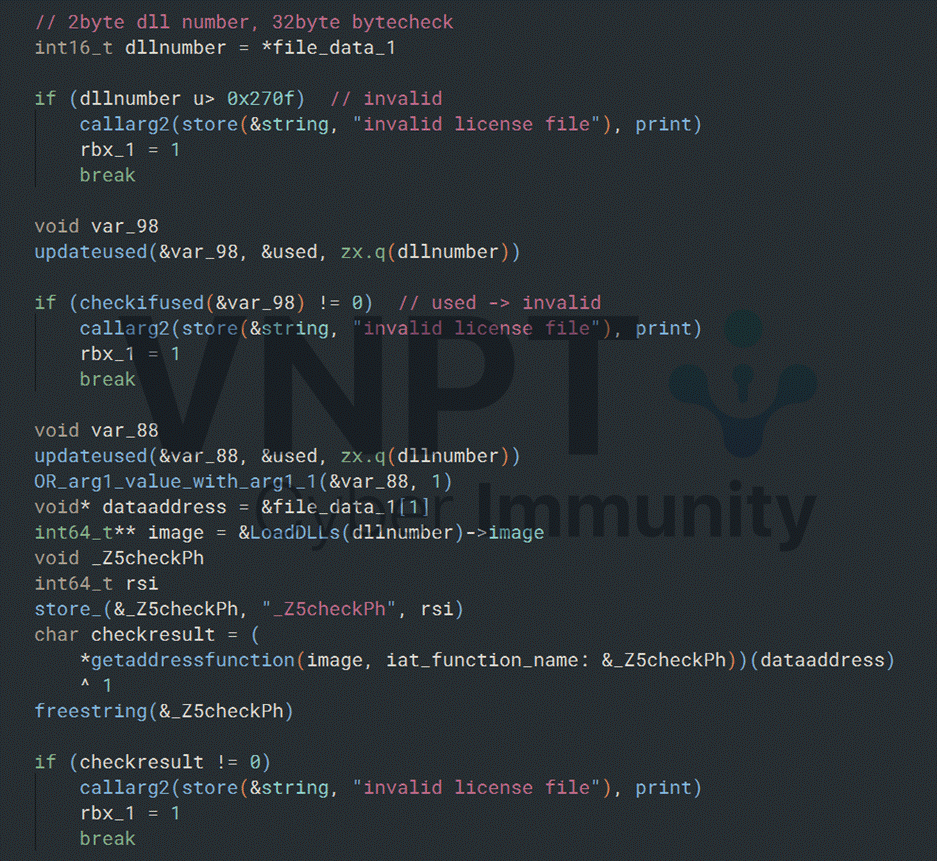
4/ The program keeps a list of used dll numbers, so the same dll number can't appear twice.
5/ Before invoking any check, the program builds an increment list containing the numbers of all dlls imported by the current dll (including the current dll itself).
6/ If the check function returns 1 for the 32-byte argument (meaning the check passed), each dll number from the increment list is used as an index into the BUF array and has the current counter added to BUF[index].
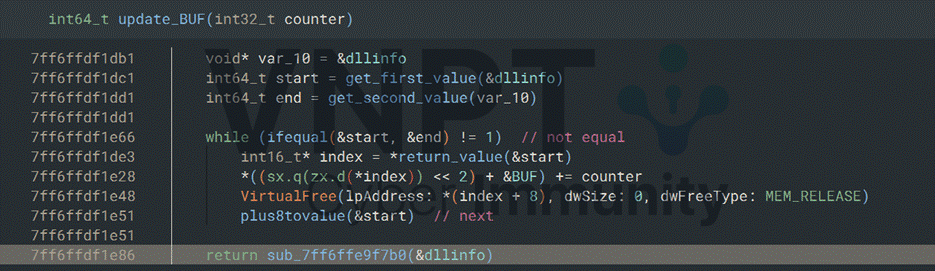
To simplify, the program behavior can be represented as:
BUF = [0] * 10000
order = [1,6,3,8,...] # the dll order
mylist = [
[0,1,6,8,...], # imported dlls of 0000.dll
[1,4,24,...], # imported dlls of 0001.dll
...
] # 10000 arrays
Used = []
for counter in range(10000):
current = order[counter]
if current in Used:
print("Invalid")
break
else:
Used.append(current)
if pass the 32-bytes check of the current dll:
for index in mylist[current]:
BUF[index] += counter
assert BUF == ENC
# If BUF == ENC then decrypt the flag using SHA256(license.bin)
Extracting dlls from resources
All 10000 dlls are compressed and stored as resources inside 10000.exe.
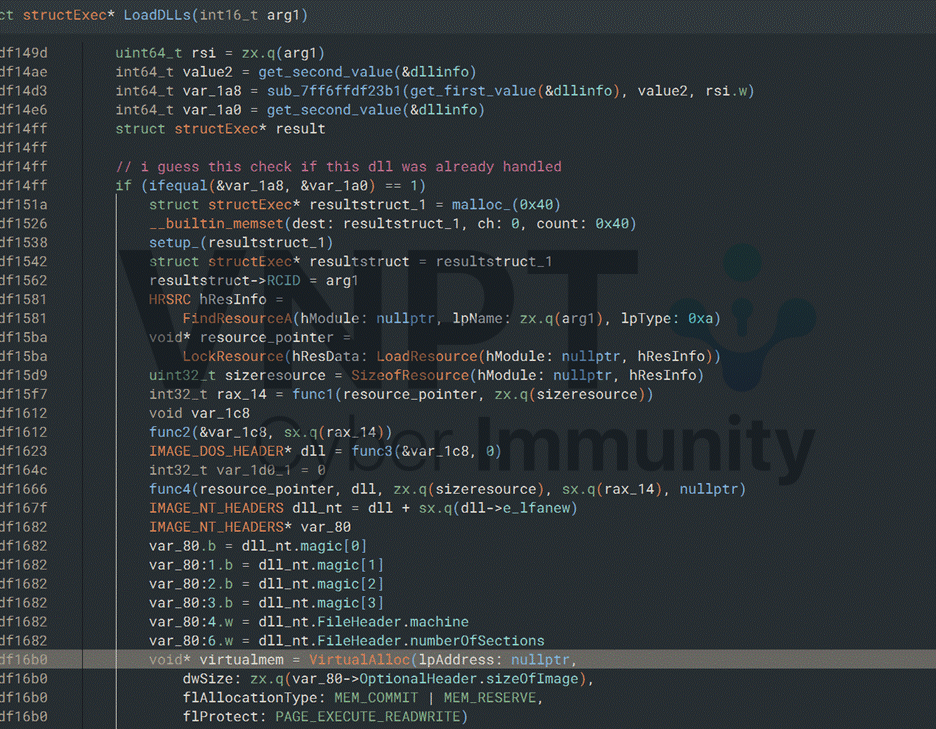
There are 4 core functions in this decompression process, which I named func1, func2, func3 and func4.
I didn't find any info about this type of compression. So I decided to reimplement the entire decompression logic by using LibPeConv from hasherezade.
// Main extraction function
int extract_all_dlls(BYTE* loaded_pe, FunctionAddresses& funcs, int start_id, int end_id, DWORD resource_type) {
int success_count = 0;
std::cout << "[+] Starting extraction of " << (end_id - start_id + 1) << " DLLs..." << std::endl;
std::cout << "[+] Resource IDs: " << start_id << " to " << end_id << std::endl;
for (int resource_id = start_id; resource_id <= end_id; resource_id++) {
int index = resource_id - start_id;
// Progress indicator
if (index % 100 == 0) {
std::cout << "[+] Processing: " << index << "/" << (end_id - start_id + 1) << std::endl;
}
try {
// Step 1: Load resource from PE
size_t resource_size = 0;
BYTE* resource_data = extract_resource((HMODULE)loaded_pe, resource_id, resource_type, resource_size);
if (!resource_data) {
std::cerr << "[-] Resource " << resource_id << " not found, skipping..." << std::endl;
continue;
}
BYTE* processed_data = resource_data;
size_t processed_size = resource_size;
std::cout << "[!] Processing resource " << resource_id << "..." << std::endl;
// Call func1: Takes resource data and size, returns int64_t handle
std::cout << "[!] Calling func1..." << std::endl;
typedef int64_t(*Func1)(BYTE*, size_t);
Func1 func1 = (Func1)(loaded_pe + 0x2690);
int64_t res_func1 = func1(resource_data, resource_size);
if (res_func1 == 0) {
std::cerr << "[-] func1 failed for resource " << resource_id << std::endl;
free(resource_data);
continue;
}
std::cout << "[+] func1 returned: 0x" << std::hex << res_func1 << std::dec << std::endl;
// Call func2: Takes pointer to result buffer and func1 result
std::cout << "[!] Calling func2..." << std::endl;
typedef int64_t(*Func2)(int64_t*, int64_t);
Func2 func2 = (Func2)(loaded_pe + 0xc0c30);
int64_t res_func2 = 0; // Initialize to 0
int64_t func2_result = func2(&res_func2, res_func1);
if (func2_result == 0 && res_func2 == 0) {
std::cerr << "[-] func2 failed for resource " << resource_id << std::endl;
free(resource_data);
continue;
}
std::cout << "[+] func2 returned: 0x" << std::hex << func2_result
<< ", res_func2: 0x" << res_func2 << std::dec << std::endl;
// Call func3: Takes pointer from func2 and 0, returns pointer
std::cout << "[!] Calling func3..." << std::endl;
typedef BYTE* (*Func3)(int64_t*, int64_t);
Func3 func3 = (Func3)(loaded_pe + 0x297d0);
BYTE* res_func3 = func3(&res_func2, 0);
if (res_func3 == nullptr) {
std::cerr << "[-] func3 failed for resource " << resource_id << std::endl;
free(resource_data);
continue;
}
std::cout << "[+] func3 returned: " << (void*)res_func3 << std::endl;
// Call func4: Final function that returns the DLL buffer
std::cout << "[!] Calling func4..." << std::endl;
typedef int64_t* (*Func4)(BYTE*, BYTE*, size_t, int64_t, int64_t);
Func4 func4 = (Func4)(loaded_pe + 0x35e8);
int64_t* res_func4 = func4(resource_data, res_func3, resource_size, res_func1, 0);
if (res_func4 == nullptr) {
std::cerr << "[-] func4 failed for resource " << resource_id << std::endl;
free(resource_data);
continue;
}
std::cout << "[+] func4 returned: " << (void*)res_func4 << std::endl;
// Step 3: Save to file
std::string filename = generate_filename(index);
if (save_to_file(filename.c_str(), res_func3, res_func1)) {
success_count++;
if (index < 10 || index % 500 == 0) {
std::cout << "[+] Saved: " << filename << " (" << res_func1 << " bytes)" << std::endl;
}
}
else {
std::cerr << "[-] Failed to save: " << filename << std::endl;
}
// Cleanup
free(resource_data);
}
catch (...) {
std::cerr << "[-] Exception while processing resource " << resource_id << std::endl;
}
}
return success_count;
}
Finding the correct dll order
First, we need each DLL’s imported-dll list. I used two Python scripts (with pefile and sqlite3) to extract imports and build a dependency database.
____________________________________________________________________________________
import os
import sqlite3
import pefile
DB_PATH = "dlls.db"
DIRECTORY_PATH = r"..."
_global_conn = None
def init_db(db_path=DB_PATH):
global _global_conn
if _global_conn:
try:
_global_conn.close()
except:
pass
conn = sqlite3.connect(db_path, timeout=30)
_global_conn = conn
with conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS dlls (
key INTEGER,
dll_id INTEGER
)
""")
conn.execute("CREATE INDEX IF NOT EXISTS idx_key ON dlls(key)")
return conn
def get_imported_dlls(file_path):
try:
pe = pefile.PE(file_path)
if not hasattr(pe, 'DIRECTORY_ENTRY_IMPORT'):
return []
dll_ids = []
for entry in pe.DIRECTORY_ENTRY_IMPORT:
dll_name = entry.dll.decode('utf-8') if isinstance(entry.dll, bytes) else entry.dll
try:
num = int(dll_name[:4])
dll_ids.append(num)
except ValueError:
pass
pe.close()
return dll_ids
except Exception:
return []
def scan_directory(directory_path, conn):
if not os.path.isdir(directory_path):
print(f"Error: Path '{directory_path}' is not a valid directory.")
return 0
key_counter = 0
for item in os.listdir(directory_path):
full_path = os.path.join(directory_path, item)
if os.path.isfile(full_path) and full_path.endswith(".dll"):
dll_ids = get_imported_dlls(full_path)
with conn:
for dll_id in dll_ids:
conn.execute("INSERT INTO dlls (key, dll_id) VALUES (?, ?)", (key_counter, dll_id))
key_counter += 1
print(f"[+] Saved {key_counter} key in database.")
return key_counter
if __name__ == "__main__":
conn = init_db()
scan_directory(DIRECTORY_PATH, conn)
conn.close()
_global_conn = None
import sqlite3
import json
DB_PATH = "dlls.db"
def open_db(db_path=DB_PATH):
conn = sqlite3.connect(db_path, timeout=30)
return conn
def recursive_fetch(key, conn, visited_set):
cursor = conn.cursor()
cursor.execute("SELECT dll_id FROM dlls WHERE key = ?", (key,))
rows = cursor.fetchall()
for (dll_id,) in rows:
if dll_id not in visited_set:
visited_set.add(dll_id)
recursive_fetch(dll_id, conn, visited_set)
if __name__ == "__main__":
conn = open_db()
all_results = {}
for start_key in range(10000):
visited_ids = set()
visited_ids.add(start_key)
recursive_fetch(start_key, conn, visited_ids)
all_results[str(start_key)] = list(visited_ids)
output_filename = "dll_dependencies1.json"
with open(output_filename, 'w') as f:
json.dump(all_results, f, cls=OneLineListEncoder, indent=4)
conn.close()
___________________________________________________________________________________
After collecting the imported lists, we need to recover the order array from the ENC values.
This is a permutation-recovery problem: each DLL appears exactly once in order, and when loaded at position counter, it adds counter to the buffer positions of all its imported DLLs.
Translating to Math
In mathematical terms:
- Variables: pos[dll_id] = position where dll_id is loaded
- Constraints: For each DLL i, we know: ENC[i] = sum of positions of all DLLs that import dll_i
Example:
If DLLs {2, 7, 9} all import DLL #5:
ENC[5] = pos[2] + pos[7] + pos[9]
The Solution: Hybrid Recovery Algorithm
We uses a two-phase approach to efficiently recover the correct DLL loading order:
Phase 1: Peeling
Some DLLs are only imported by one other DLL. We can immediately determine when that importing DLL must be loaded.
Example
Given:
DLL #42 is imported by: {DLL #7, DLL #15, DLL #23}
ENC[42] = 150
This means: pos[7] + pos[15] + pos[23] = 150
If we discover that pos[7] = 80 and pos[15] = 30 (from previous peeling):
80 + 30 + pos[23] = 150
pos[23] = 40 ✓ Solved!
Now DLL #23 is at position 40, and we can use this to solve other equations.
The Algorithm
# Find DLLs with only one unknown importer
deg1_queue = deque()
for dll in range(N):
if len(row_to_cols[dll]) == 1: # Only one importer left
deg1_queue.append(dll)
while deg1_queue:
dll = deg1_queue.popleft()
# Get the single unknown importer
importer = next(iter(row_to_cols[dll]))
position = current_buf[dll] # This is where importer must be
# Assign position
pos[importer] = position
# Update all DLLs that this importer imports
for other_dll in range(N):
if importer in row_to_cols[other_dll]:
current_buf[other_dll] -= position # Subtract contribution
row_to_cols[other_dll].discard(importer) # Remove from unknowns
if len(row_to_cols[other_dll]) == 1:
deg1_queue.append(other_dll) # New solvable DLL!
Phase 2: Gaussian elimination + assignment
When peeling gets stuck, we have a core of DLLs with complex interdependencies. These DLLs all import each other in complicated ways, so we can't solve them one-by-one.
Step 1: Build Linear System
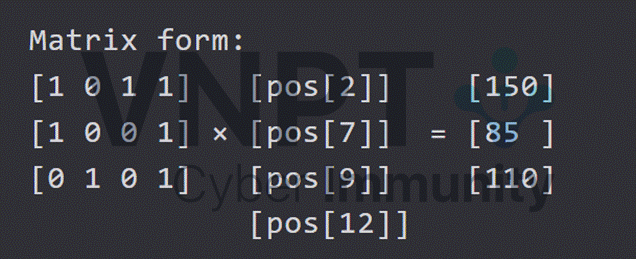
Create a matrix equation A × x = b:
Example with 3 remaining DLLs:
DLL #5 is imported by: {DLL #2, DLL #7, DLL #9} → ENC[5] = 150
DLL #8 is imported by: {DLL #2, DLL #9} → ENC[8] = 85
DLL #12 is imported by: {DLL #7, DLL #9} → ENC[12] = 110
Step 2: Solve with LSQR
Use LSQR (Least Squares solver) to find positions:
from scipy.sparse.linalg import lsqr
x, istop, itn, r1norm = lsqr(A, b, atol=1e-8, btol=1e-8)This gives fractional solutions like: pos[2] = 7.3, pos[7] = 12.8, pos[9] = 15.1
Step 3: Hungarian Algorithm
The LP solution is fractional, but we need integer positions. Hungarian algorithm assigns fractional values to the closest available integers:
from scipy.optimize import linear_sum_assignment
# Build cost matrix: how far is each fractional value from each available position?
cost[i, j] = abs(x_lp[i] - available_positions[j])
# Find optimal assignment (minimizes total distance)
row_ind, col_ind = linear_sum_assignment(cost)This hybrid approach produced a valid DLL load order.
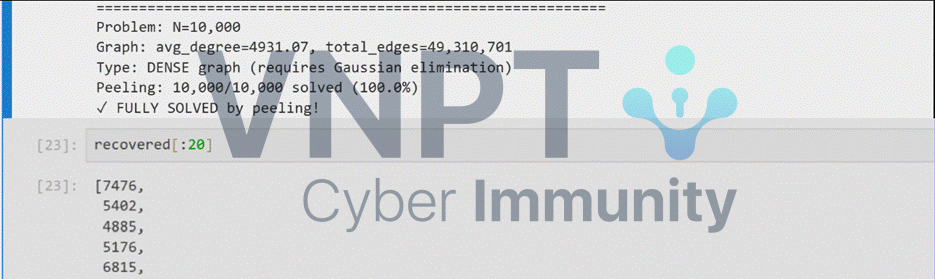
Auto-solving the 32-byte checks for all dlls
At the start of each dll's check function, the 32-byte input undergoes several transforms.
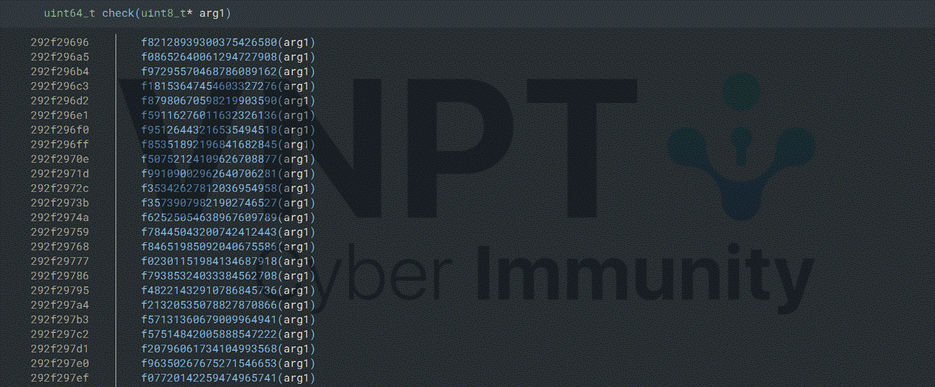
We can classify them into 3 types:
- Permutation
- Substitution
- Strange transform
An important note is that at the start of these functions, the first DWORD of the 32-byte input is XORed with BUF[offset], the offset is the number extracted from the dll name that include that check function.
These 3 types can be reversed easily to find the original input.
def invert_ftypeHard(result: bytearray, var_68: bytearray, offset: int) -> bytearray:
"""Invert Hard type function"""
rax_7 = result[0] & 1
var_88 = bytearray(result)
var_88[0] ^= (rax_7 ^ 1)
MOD = 1 << 256
PHI = 1 << 255
E = int.from_bytes(var_68, "little")
if E % 2 == 0:
raise ValueError("Exponent E is even -> not invertible mod 2^256")
d = pow(E, -1, PHI)
y = int.from_bytes(var_88, "little")
B_int = pow(y, d, MOD)
B = B_int.to_bytes(32, "little")
sus = SUS[offset]
low4 = int.from_bytes(B[0:4], "little") ^ sus ^ rax_7 ^ 1
A = bytearray(B)
A[0:4] = low4.to_bytes(4, "little")
return A
def invert_ftypeSoft(arg1_output: bytearray, PERM_MAP: bytearray, offset: int) -> bytearray:
"""Invert Soft type function"""
reverse_map = [0] * 32
for i in range(32):
j = PERM_MAP[i]
if j >= 32:
raise ValueError("Permutation map contains an index out of bounds (>= 32).")
reverse_map[j] = i
arg1_pre_xor = [0] * 32
for j in range(32):
source_index = reverse_map[j]
arg1_pre_xor[j] = arg1_output[source_index]
v_in_pre_xor = int.from_bytes(bytes(arg1_pre_xor[0:4]), "little")
v_true_initial = v_in_pre_xor ^ SUS[offset]
xor_result_bytes = v_true_initial.to_bytes(4, "little")
arg1_pre_xor[0:4] = list(xor_result_bytes)
arg1_pre_xor = bytearray(arg1_pre_xor)
return arg1_pre_xor
def invert_ftypeEasy(arg1: bytearray, inv_s_box: bytearray, offset: int) -> bytearray:
"""Invert Easy type function"""
if len(arg1) != 32:
raise ValueError("Input 'arg1' must be a list of 32 bytes (integers 0-255).")
arg1_reverted_subst = [inv_s_box[b] for b in arg1]
arg1[:] = arg1_reverted_subst
v_out = int.from_bytes(bytes(arg1[0:4]), "little")
v_in = v_out ^ SUS[offset]
v_in_bytes = v_in.to_bytes(4, "little")
for i in range(4):
arg1[i] = v_in_bytes[i]
return arg1
After being transformed by these functions, the input array is used as an XORed key for a hardcode matrix A.
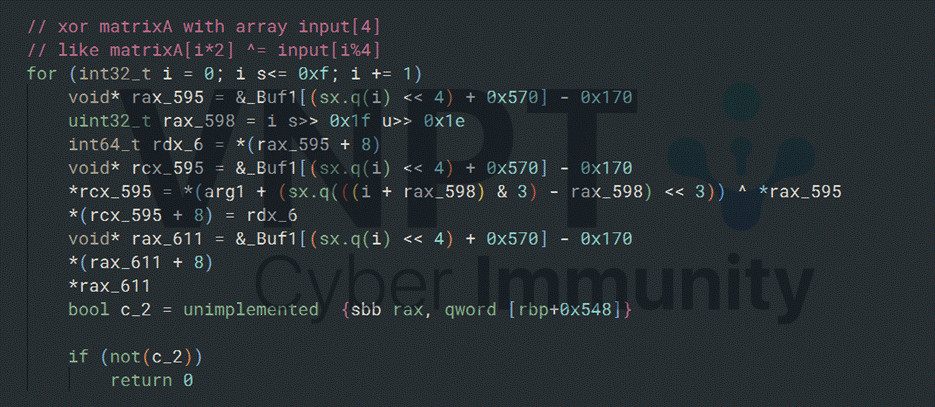
Matrix A is then used for the final check based on this equation
A ^ exponent mod p = E
These values are all defined after the calling-function block.
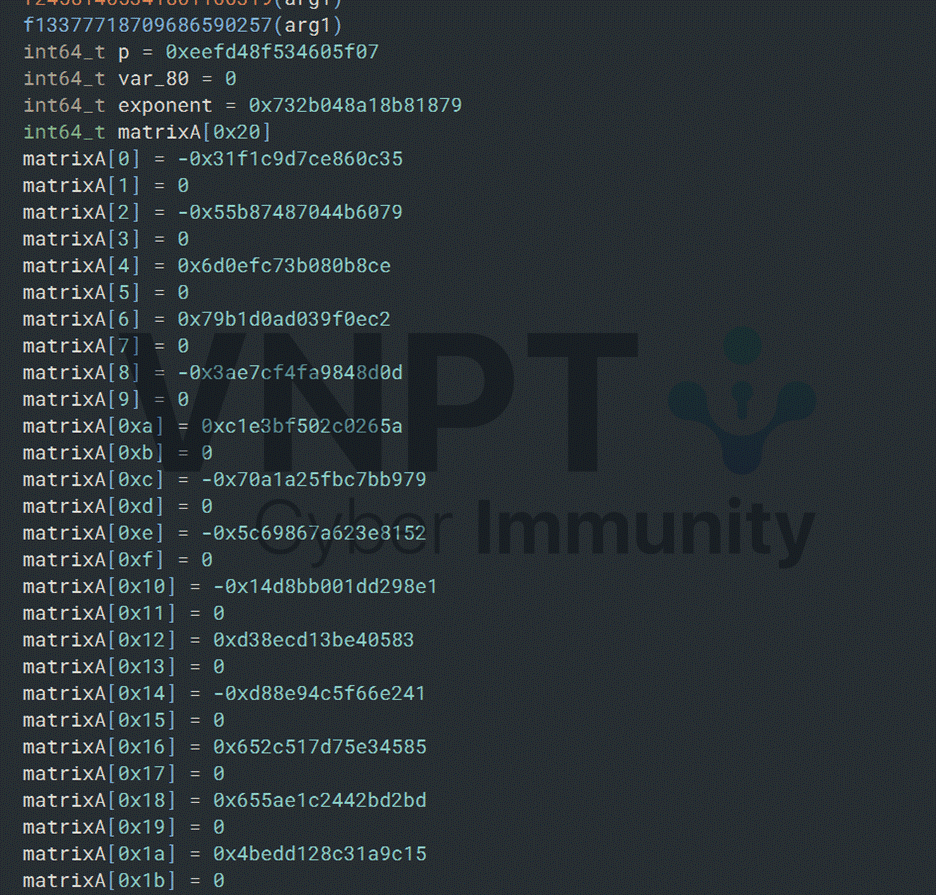
Except the matrix E is near the end of the check function.
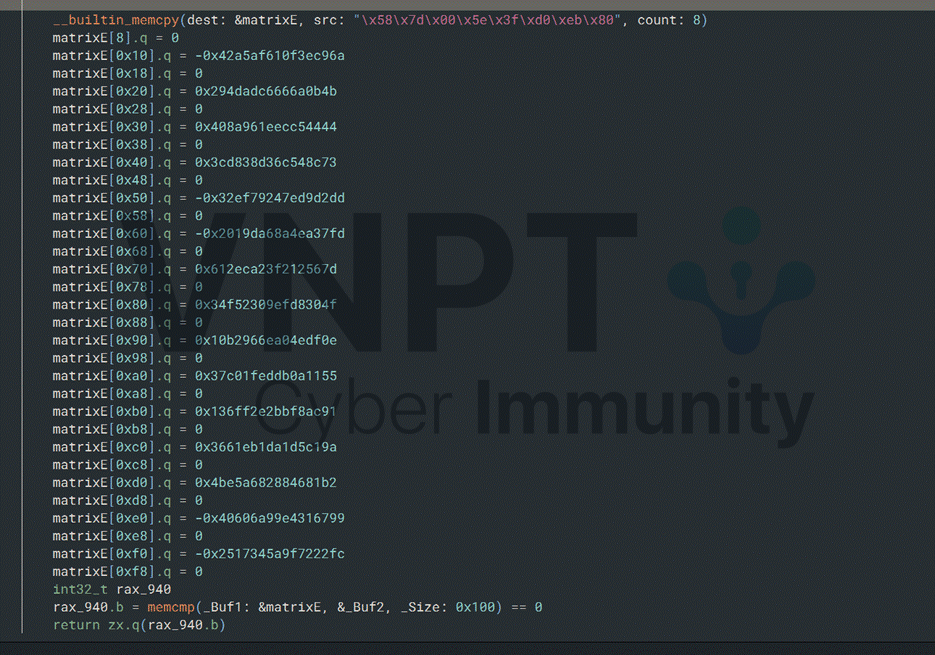
Once we extract E, exponent, and p, we can compute A as follows:
def matrixsolve(M, exp, E, xor_matrix):
"""Solve matrix equation for decryption"""
def matmul(A, B, mod):
R = [[0]*4 for _ in range(4)]
for i in range(4):
for j in range(4):
s = 0
for k in range(4):
s = (s + A[i][k]*B[k][j]) % mod
R[i][j] = s
return R
def matpow(A, e, mod):
R = [[1 if i==j else 0 for j in range(4)] for i in range(4)]
base = [row[:] for row in A]
while e > 0:
if e & 1:
R = matmul(R, base, mod)
base = matmul(base, base, mod)
e >>= 1
return R
phi = (M**4 - 1) * (M**4 - M) * (M**4 - M**2) * (M**4 - M**3)
d = pow(exp, -1, phi)
A = matpow(E, d, M)
E_recalc = matpow(A, exp, M)
assert all((E_recalc[i][j] - E[i][j]) % M == 0 for i in range(4) for j in range(4))
Plain = [[(A[i][j] ^ xor_matrix[i][j]) for j in range(4)] for i in range(4)]
assert Plain[0] == Plain[1] == Plain[2] == Plain[3]
return b''.join(long_to_bytes(w, 8)[::-1] for w in Plain[0])
To automate extraction, we used Capstone to disassemble each DLL and recorded movabs (immediate constants) and the call traces that identify which imported DLLs are being referenced. The parser focuses on movabs rax, 0x… patterns to collect MODULO, EXPONENT, XOR matrix values and the ENC matrix values.
for insn in md.disasm(data, exp_va):
if insn.mnemonic == 'mov' and TraceCall:
old = insn
continue
if insn.mnemonic != 'call' and (insn.mnemonic != 'movabs' or 'rax, 0x' not in insn.op_str):
continue
if insn.mnemonic == 'movabs':
TraceCall = False
if count >= 2 and count < 18:
XOR.append(int(insn.op_str.split()[-1], 16))
elif count == 0:
MODULO = int(insn.op_str.split()[-1], 16)
elif count == 1:
EXPONENT = int(insn.op_str.split()[-1], 16)
else:
ENC.append(int(insn.op_str.split()[-1], 16))
count += 1
if TraceCall:
if insn.mnemonic == 'call':
if 'rax' in insn.op_str:
find = insn.address + int(old.op_str.split()[-1][:-1], 16)
CALL.append(get_imported_dll_by_va(pe, find))
else:
CALL.append((None, int(insn.op_str, 16)))
The same approach is used to extract constants and tables from the three transform-function types.
Generate the license.bin
Finally, put the pieces together to generate license.bin. The main script:
- Loads the cached DLL analysis (to avoid re-parsing each DLL repeatedly).
- Loads dll_dependencies1.json.
- Uses the recovered order.
- For each DLL in order, calls
HandleStartDLL(dll_id)to generate the 32-byte block that passes the check, writes dll_id (2 bytes little-endian) and the 32-byte bytecheck into the file, and updates BUF counters.
def main():
"""Main entry point"""
script_start = time.time()
print("\n" + "="*70)
print("DLL PROCESSOR - Using Pre-loaded Cache")
print("="*70)
# Load cache once at startup
load_function_cache("dll_cache.pkl")
# Load dependencies
with open('dll_dependencies1.json', 'r', encoding='utf-8') as f:
mylist = json.loads(f.read())
mylist = {int(k): v for k, v in mylist.items()}
order = [...]
with open("license.bin", "wb") as f:
total = 0
for i, dll_id in enumerate(order):
lists = mylist.get(dll_id)
if lists is None:
print(f"Skipping {dll_id:04d}.dll (no data)")
continue
bytecheck = HandleStartDLL(dll_id)
print(f"Writing {dll_id:04d}.dll at {total:05X} ({bytecheck.hex()} bytes)")
f.write(dll_id.to_bytes(2, "little"))
f.write(bytecheck)
total += 2 + len(bytecheck)
for num in lists:
BUF[num] += i
if (i + 1) % 20 == 0:
elapsed = time.time() - script_start
rate = (i + 1) / elapsed
remaining = (len(order) - i - 1) / rate if rate > 0 else 0
print(f"-----[!]Progress: {i+1}/{len(order)} ({(i+1)*100//len(order)}%) - {rate:.2f} DLLs/sec - ETA: {remaining/60:.1f}min")
if total < 0x53020:
f.write(b"\x00" * (0x53020 - total))
print(f"\nlicense.bin written, total {total} bytes.")
script_time = time.time() - script_start
print(f"\n{'='*70}")
print(f"SCRIPT COMPLETED IN {script_time/60:.2f} MINUTES")
print(f"{'='*70}\n")
The script takes roughly ~40 minutes to generate license.bin (depending on CPU and I/O). Running 10000.exe directly with a freshly created license.bin would also take a long time, so it's faster to compute the final decryption directly.
In that case, you can just reimplement the decryption logic which use SHA256 and AES.
from Crypto.Cipher import AES
import hashlib
def sha256_file(file_path, chunk_size=8192):
"""Compute SHA-256 of a large file efficiently."""
sha256 = hashlib.sha256()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(chunk_size), b""):
sha256.update(chunk)
return sha256.digest()
KEY = sha256_file(b'license.bin')
IV = bytes.fromhex('78615338bcb1f180d34ed1fa47a41d3d')
enc = bytes.fromhex('A1A610483EBD825CE1E00D722DF68DCFF70CAC1E64A4FCA7440B5ABC617259CE66F7E0717B5751A3BF5F6C9DEE1C17BC881C2C17A0D8032F369A00BA3209C4F569D2CD4729B6B4BABB6B35F0D504F25D')
cipher = AES.new(KEY, AES.MODE_CBC, IV)
dec = cipher.decrypt(enc)
print(dec.decode())
That yields the plaintext flag.
![]()
Flag:Its_l1ke_10000_spooO0o0O0oOo0o0O0O0OoOoOOO00o0o0Ooons@flare-on.com
Read more:
Part 1: Flareon 12 Writeup Part 1
Part 2: Flareon 12 Writeup Part 2