Elasticsearch là một trong những công cụ mạnh mẽ nhất hiện nay trong việc tìm kiếm và phân tích dữ liệu. Tuy nhiên, ít ai biết được đằng sau sức mạnh đó Elasticsearch hoạt động như thế nào khi nhận và xử lý các truy vấn tìm kiếm từ phía người dùng. Bài viết này chúng ta cùng đi sâu vào khám phá cách Elasticsearch thực sự vận hành khi nhận và xử lý truy vấn dữ liệu với hiệu suất ấn tượng trong cluster.
 Để đảm bảo tính sẵn sàng cao của dữ liệu chúng ra thêm một node vào cluster, đồng thời cấu hình thêm 1 bản replica từ bản gốc replica=1 => Dữ liệu giờ đây sẽ gồm P1, P2, P3, R1, R2, R3
Để đảm bảo tính sẵn sàng cao của dữ liệu chúng ra thêm một node vào cluster, đồng thời cấu hình thêm 1 bản replica từ bản gốc replica=1 => Dữ liệu giờ đây sẽ gồm P1, P2, P3, R1, R2, R3
 Để tăng tốc độ truy vấn và tận dụng khả năng truy vấn song song, chúng ta sẽ thêm một node mới vào cluster. Các shard sẽ được tự động phân phối lại.
Để tăng tốc độ truy vấn và tận dụng khả năng truy vấn song song, chúng ta sẽ thêm một node mới vào cluster. Các shard sẽ được tự động phân phối lại.
 Tùy vào từng yêu cầu có thể tăng hoặc giảm số lượng shard và replica
=> Lưu ý: số lượng shard chỉ có thể được cấu hình trước khi tạo index, không thể thay đổi sau khi index đã được tạo. Nếu như bạn cần cấu hình lại số lượng shard có thể cân nhắc sử dụng reindex
Tùy vào từng yêu cầu có thể tăng hoặc giảm số lượng shard và replica
=> Lưu ý: số lượng shard chỉ có thể được cấu hình trước khi tạo index, không thể thay đổi sau khi index đã được tạo. Nếu như bạn cần cấu hình lại số lượng shard có thể cân nhắc sử dụng reindex
 Coordinate node lấy 20 giá trị từ 981-1000, và loại bỏ phần còn lại.
Sau khi nhận yêu cầu, shard sẽ tải thông tin tài liệu dựa trên các tham số và trả về dữ liệu cho coordinate node.
Một khi tất cả các shard trả lại kết quả, coordinate node trả lại kết quả cho client.
Tài liệu tham khảo
How does Elasticsearch process a query? - Elastic Stack / Elasticsearch - Discuss the Elastic Stack
Distributed Search Execution | Elasticsearch: The Definitive Guide [2.x] | Elastic
Node roles | Elasticsearch Guide [8.17] | Elastic
Coordinate node lấy 20 giá trị từ 981-1000, và loại bỏ phần còn lại.
Sau khi nhận yêu cầu, shard sẽ tải thông tin tài liệu dựa trên các tham số và trả về dữ liệu cho coordinate node.
Một khi tất cả các shard trả lại kết quả, coordinate node trả lại kết quả cho client.
Tài liệu tham khảo
How does Elasticsearch process a query? - Elastic Stack / Elasticsearch - Discuss the Elastic Stack
Distributed Search Execution | Elasticsearch: The Definitive Guide [2.x] | Elastic
Node roles | Elasticsearch Guide [8.17] | Elastic
1. Các khái niệm cơ bản
1.1 Cluster
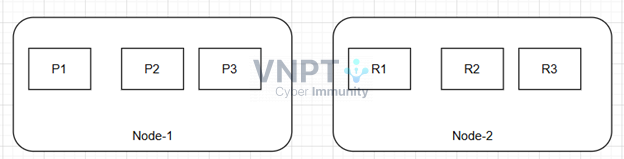
Đại diện cho một tập hợp của một hoặc nhiều node (máy chủ Elasticsearch), mỗi node trong đó có thể đảm nhận một hoặc nhiều vai trò. Cùng hoạt động như một hệ thống thống nhất để lưu trữ, tìm kiếm và phân tích dữ liệu. Cluster chịu trách nhiệm xử lý các yêu cầu từ người dùng, lưu trữ dữ liệu và đảm bảo độ tin cậy, phân tán và khả năng mở rộng của hệ thống.1.2 Shards
Shard là đơn vị lưu trữ dữ liệu. Khi tạo một index, Elasticsearch có thể chia nhỏ dữ liệu thành nhiều shard và phân phối chúng đến các node khác nhau. Shard giúp tăng tốc độ xử lý truy vấn nhờ truy vấn song song. Shard được chia thành hai loại:- Primary shard: Shard gốc – nơi dữ liệu được ghi lần đầu. Mỗi document sẽ được ghi vào một shard primary duy nhất.
- Replica shard: Bản sao của primary shard, có thể tồn tại nhiều bản. Dùng để tăng tính sẵn sàng và khả năng xử lý song song truy vấn.
Để đảm bảo tính sẵn sàng cao của dữ liệu chúng ra thêm một node vào cluster, đồng thời cấu hình thêm 1 bản replica từ bản gốc replica=1 => Dữ liệu giờ đây sẽ gồm P1, P2, P3, R1, R2, R3
Để tăng tốc độ truy vấn và tận dụng khả năng truy vấn song song, chúng ta sẽ thêm một node mới vào cluster. Các shard sẽ được tự động phân phối lại.
Tùy vào từng yêu cầu có thể tăng hoặc giảm số lượng shard và replica
=> Lưu ý: số lượng shard chỉ có thể được cấu hình trước khi tạo index, không thể thay đổi sau khi index đã được tạo. Nếu như bạn cần cấu hình lại số lượng shard có thể cân nhắc sử dụng reindex
2. Các vai trò (role) trong Elasticsearch cluster
2.1 Master node
Có thể nói master node là bổ não của c, kiểm soát toàn bộ metadata của cluster. Chỉ master node mới có thể chỉnh sửa thông tin trạng thái và metadata, như thêm và xóa index, phân bổ định tuyến shard. Master node không chiếm dụng nhiều CPU và bộ nhớ.2.2 Data node
Là nơi lưu trữ dữ liệu, hiệu suất của Elasticsearch cluster có thể phụ thuộc vào số lượng node Khi bạn gửi truy vấn, chính data node sẽ truy vấn để tìm kiếm kết quả Khi có dữ liệu mới, data node sẽ ghi dữ liệu đó vào từng shard tương ứng Data node nên được cấp nhiều tài nguyên về CPU và bộ nhớ2.3 Coordinating node
Chuyên tiếp nhận các yêu cầu tìm kiếm từ ứng dụng, nhưng không chịu trách nhiệm lưu trữ dữ liệu. Truy vấn sẽ được chia làm 2 giai đoạn:- Query phase: Chuyển tiếp yêu cầu dữ liệu đến data node có dữ liệu liên quan. Data node thực thi yêu cầu và trả lại kết quả (Ở phase này dữ liệu trả về sẽ chỉ chứa document ID và _score)
- Fetch phase: coordination node tổng hợp lại kết quả từ mỗi data node vào 1 tập kết quả duy nhất
2.4 Ingest node
Có thể được coi là node tiền xử lý (pre-process) dữ liệu. Gần tường tự với logstash Xử lý dữ liệu trước khi lập index.3. Cách Elasticsearch thực sự hoạt động khi truy vấn dữ liệu trong cluster
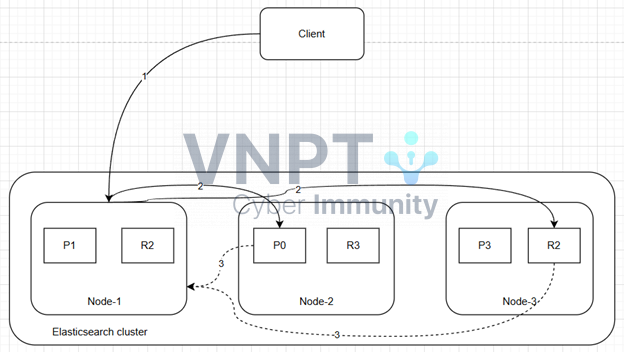
Khi người dùng gửi một truy vấn đến Elasticsearch cluster, quá trình xử lý không chỉ đơn giản là “đi tìm rồi trả về”. Để có thể hiểu rõ hơn thì chúng ta sẽ đi qua một ví dụ. Giả sử ta có 1 cluster được cấu hình shard=3, replica=1, và thực hiện truy vấn như sau:GET /test/_search { "from": 980, "size": 20 }
3.1 Query phase
- Khởi tạo một yêu cầu truy vấn và node-1 chấp nhận yêu cầu trở thành coordinate node, tạo ra hàng đợi ưu tiên có độ dài 1000(from + side)
- Coordinate node phân phối yêu cầu đến các primary shard hoặc replica shard, mỗi shard sẽ tạo ra hàng đợi ưu tiên có cùng kích thước (from + size), nhằm lưu trữ kết quả truy vấn của phân đoạn
- Mỗi shard trả về các phần tử của hàng đợi ưu tiên của riêng nó cho coordinate node, chỉ chứa ID và giá trị sắp xếp của tài liệu và coordinate node sẽ hợp nhất tất cả các phần tử vào hàng đợi ưu tiên của riêng nó, hoàn thành hành động sắp xếp và cuối cùng trả lại kết quả theo giá trị from và size
- Node nào nhận được yêu cầu từ client sẽ trở thành coordinate node
- Khi coordinate node chuyển tiếp một yêu cầu, yêu cầu đó sẽ được gán cho primary shard hoặc replica shard của cùng một shard theo thuật toán cân bằng tải
3.2 Fetch phase
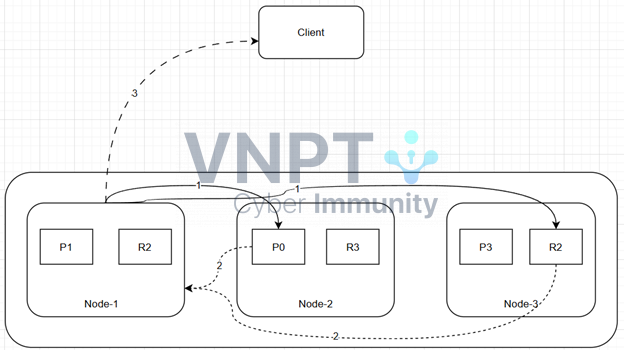
Sau khi hoàn thành truy vấn coordinate node đã thu được danh sách truy vấn, nhưng trong danh sách này chỉ có thông tin document ID và _score và không có nội dung _source.
Coordinate node lấy 20 giá trị từ 981-1000, và loại bỏ phần còn lại.
Sau khi nhận yêu cầu, shard sẽ tải thông tin tài liệu dựa trên các tham số và trả về dữ liệu cho coordinate node.
Một khi tất cả các shard trả lại kết quả, coordinate node trả lại kết quả cho client.
Tài liệu tham khảo
How does Elasticsearch process a query? - Elastic Stack / Elasticsearch - Discuss the Elastic Stack
Distributed Search Execution | Elasticsearch: The Definitive Guide [2.x] | Elastic
Node roles | Elasticsearch Guide [8.17] | Elastic
2181 lượt xem