Xin chào các bạn!
Trong thời đại mà dữ liệu ngày càng trở nên khổng lồ và phức tạp, việc tìm kiếm nhanh chóng và hiệu quả đóng vai trò vô cùng quan trọng trong nhiều hệ thống công nghệ thông tin và an toàn thông tin. Một trong những thách thức lớn là làm thế nào để kiểm tra sự tồn tại của một phần tử trong tập dữ liệu lớn một cách hiệu quả, mà vẫn tối ưu hóa bộ nhớ và thời gian xử lý. Đây chính là lúc thuật toán Bloom filter phát huy tác dụng. Trong bài viết này, mình sẽ giải thích chi tiết về thuật toán Bloom filter, cách thức hoạt động, và những lợi ích mà nó mang lại.

 Với:
Với:
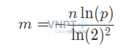 Và k là:
Và k là:
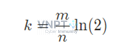 Từ trên, ta có thể dễ dàng tính toán ra được bảng sau:
Từ trên, ta có thể dễ dàng tính toán ra được bảng sau:

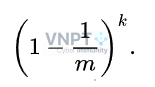
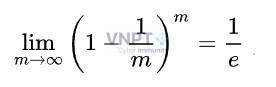 Từ đó, ta tính được:
Từ đó, ta tính được:
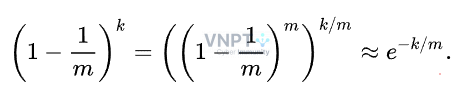
 Từ đó, ta sẽ tính được xác suất để bit đó là 1:
Từ đó, ta sẽ tính được xác suất để bit đó là 1:
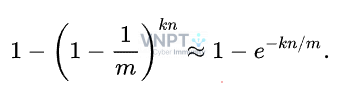
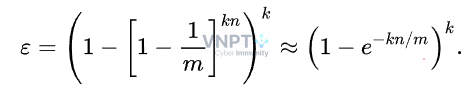
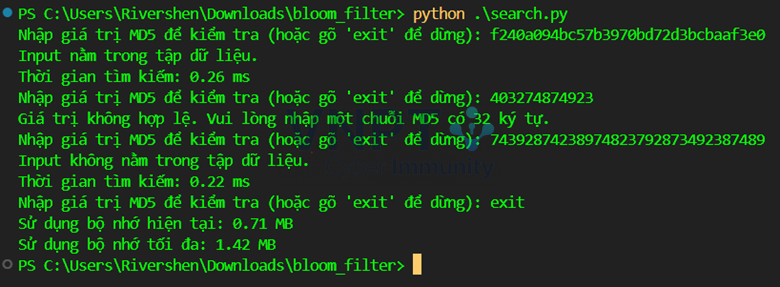 Tất cả đều đạt các tiêu chí đề ra, lượng memory sử dụng là dưới 10MB, thời gian tìm kiếm dưới 10ms với tỉ lệ false positive là 0,1%.
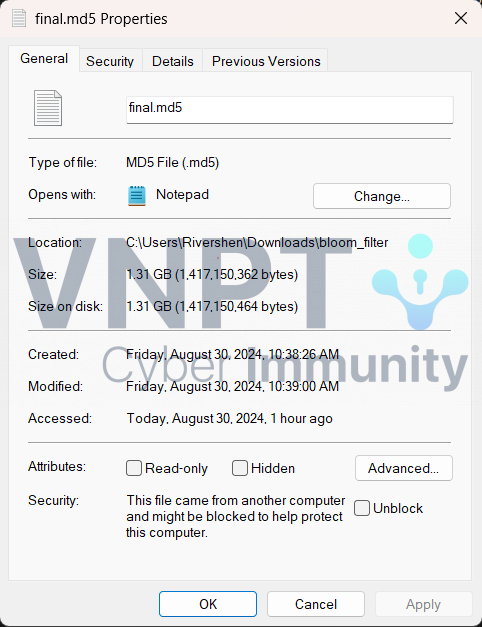
Người viết cũng đã thử test với tập dữ liệu lớn hơn: final.md5 (~1,3GB và chứa ~42 triệu dòng). Kết quả thu được cũng ngoài mong đợi:
Tất cả đều đạt các tiêu chí đề ra, lượng memory sử dụng là dưới 10MB, thời gian tìm kiếm dưới 10ms với tỉ lệ false positive là 0,1%.
Người viết cũng đã thử test với tập dữ liệu lớn hơn: final.md5 (~1,3GB và chứa ~42 triệu dòng). Kết quả thu được cũng ngoài mong đợi:
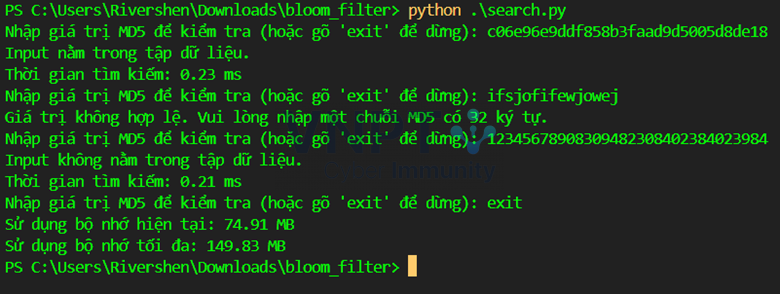 Với tập dữ liệu lớn, kết quả tìm kiếm vẫn cho rất nhanh, tuy nhiên để giữ được tỉ lệ false positive là 0,1%, ta sẽ phải đánh đổi bằng lượng memory sử dụng khá cao.
Với tập dữ liệu lớn, kết quả tìm kiếm vẫn cho rất nhanh, tuy nhiên để giữ được tỉ lệ false positive là 0,1%, ta sẽ phải đánh đổi bằng lượng memory sử dụng khá cao.
1. Bloom filter (BF) là gì?
Bloom filter là một cấu trúc dữ liệu xác suất, dùng để kiểm tra xem một giá trị nào đó có nằm trong tập hợp không. Nếu kết quả trả về là không, thì CHẮC CHẮN giá trị đó không nằm trong tập hợp. Nhưng nếu trả về có, thì CHƯA CHẮC phần tử đó đã nằm trong tập hợp (false positive). Đến với bài toán, Google Chrome có một file chứa các URL độc hại và muốn kiểm tra xem URL người dùng nhập vào có nằm trong tập dữ liệu và trả về cảnh báo. Đối với bài toán này, ta có một số hướng xử lý:- Linear search: độ phức tạp O(n), chậm
- Binary Search: Cần yêu cầu dữ liệu có độ dài ký tự đều nhau và cần sắp xếp tập dữ liệu trước.
2. Nguyên lý hoạt động
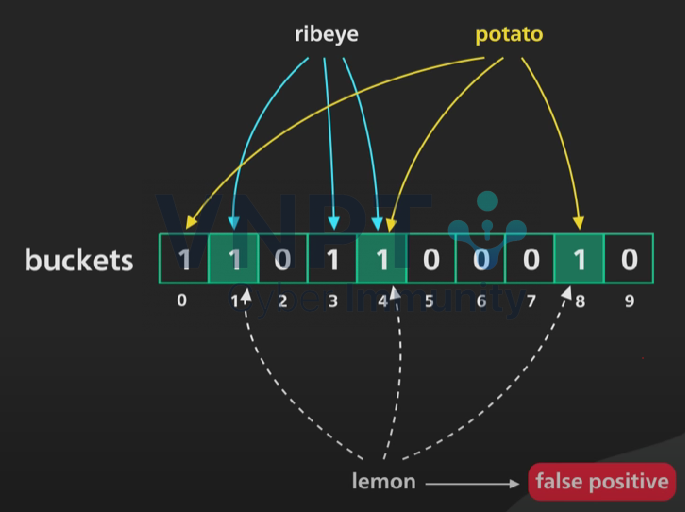
Ta sử dụng 1 mảng bit gồm M phần tử 0, gọi là buckets
Minh hoạ M = 10
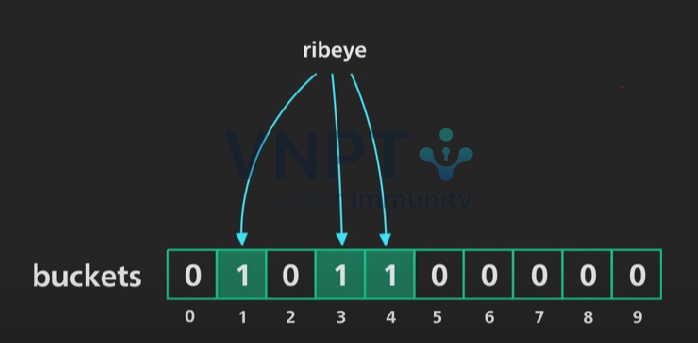
Khi một phần tử mới được thêm vào tập S, ta sẽ hash nó lại và đánh dấu bit ở vị trí tương ứng thành 1:
Hash “ribeye” vào 3 vị trí 1,3,4
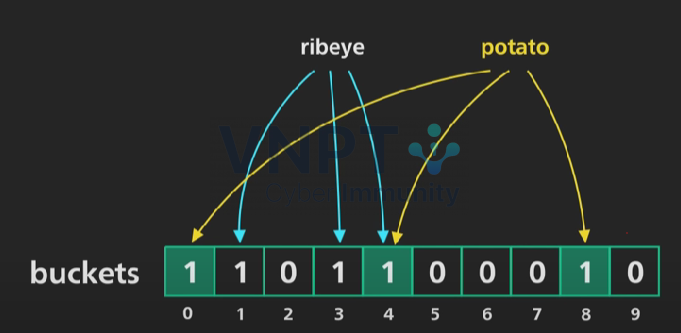
Hash “potato” vào 3 vị trí 0,4,8
Ở trên ví dụ trên, ta sử dụng 3 hàm hash, và số lượng hàm hash function được gọi là k. Các hàm hash function sử dụng trong bloom filter nên là những hàm hash có tính độc lập và kết quả là một tập hợp được phân bố một cách đồng đều. Các hàm hash này cũng nên có thời gian xử lý nhanh và tốn ít tài nguyên (vì lí do này các hàm hash mang tính mật mã như sha1 thường ít được sử dụng). Các hàm hash thường được sử dụng có thể kể đến murmur, fnv,… Để kiểm tra giá trị input có thuộc tập dữ liệu không, ta thực hiện hash nó và kiểm tra bit tương ứng:
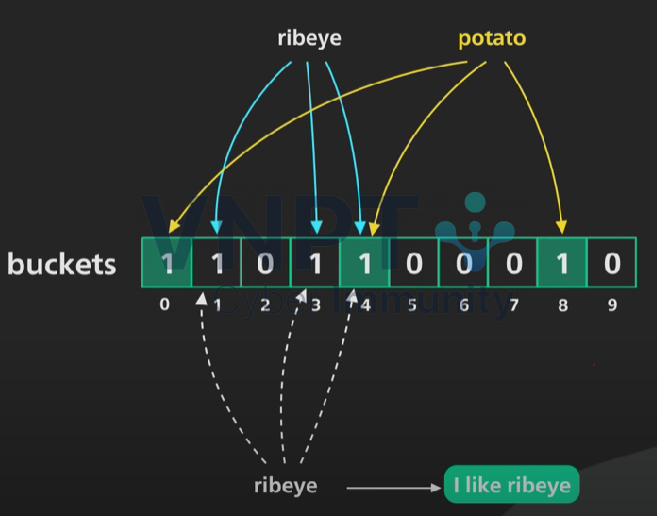
Thực hiện kiểm tra với “ribeye”
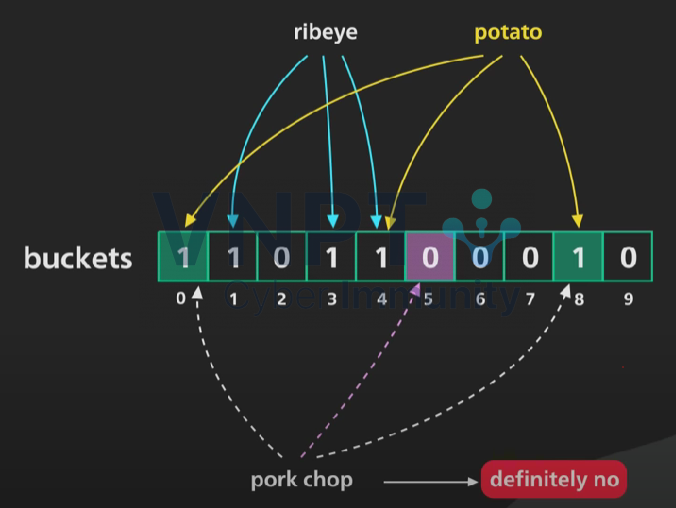
Thực hiện kiểm tra với “pork chop” => definitely no
Trường hợp “lemon” sẽ cho ra false positive, nghĩa là lemon không có trong tập dữ liệu
Vậy:- Trong trường hợp có ít nhất 1 giá trị hash mà tại đó bit = 0, vậy tức là input không thuộc tập dữ liệu (chắc chắn 100%)
- Nếu tất cả đều thỏa mãn bit = 1 -> input có thể thuộc tập dữ liệu, tuy nhiên vẫn cần kiểm tra tiếp để chắc chắn (nếu thực sự x không nằm trong tập dữ liệu thì đây chính là trường hợp rơi vào xác suất dương tính giả — false positive)
- Độ phức tạp của thuật toán là O(k), tức là hằng số không phụ thuộc vào N
3. Xác suất False Positive của Bloom Filter:
Ta có thể lựa chọn được độ chính xác và hy sinh bằng tốc độ và bộ nhớ. Mình sẽ đưa ra luôn kết quả của xác suất false positive:
Với:
- p: xác suất dương tính giả (false positive)
- n: số phần tử trong tập dữ liệu
- m: kích thước bộ lọc (tính theo bit)
- k: số hàm băm
Và k là:
Từ trên, ta có thể dễ dàng tính toán ra được bảng sau:
| Tỉ lệ False Positive p | Số phần tử trong tập dữ liệu n | Kích thước bộ lọc m (MB) | Số hàm băm k |
| 1% | 50000000 | 57,131 | 6,64 |
| 0,1% | 50000000 | 85,697 | 9,96 |
| 0,01% | 50000000 | 114,262 | 13,28 |
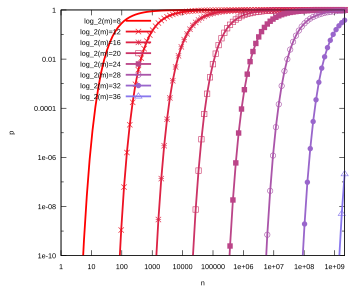
Xác suất dương tính giả 𝑝 là hàm của số phần tử 𝑛 trong bộ lọc và kích thước bộ lọc 𝑚 . Số lượnghàm băm tối ưu 𝑘 = ( 𝑚 / 𝑛 ) ln(2) đã được giả định.
CHỨNG MINH:
Ai không quan tâm tới toán học lắm thì có thể bỏ qua phần này, nhưng ai thắc mắc về công thức tính False Positive và tò mò giống mình thì có thể tham khảo phần chứng minh bên dưới.- Giả sử hàm băm chọn mỗi trị trí trong mảng là như nhau => nếu m là kích thước bộ lọc, thì xác suất để một bit bất kì không được gán là 1 bởi hàm băm là:
- Nếu k là số lượng hàm băm và các hàm này không có sự tương quan đáng kể với nhau, thì xác suất bit đó không bị thiết lập thành 1 bởi bất kỳ hàm băm nào là:
- Xấp xỉ giới hạn, ta có:
Từ đó, ta tính được:
- Nếu thêm n phần tử vào, xác suất để bit nhất định đó vẫn là 0 là:
Từ đó, ta sẽ tính được xác suất để bit đó là 1:
- Vậy, khi kiểm tra sự tồn tại của một phần tử không thuộc tập dữ liệu, mỗi một vị trí trong k vị trí được tính bởi k hàm băm là 1 sẽ có xác suất như trên
⇒ Xác suất để tất cả các vị trí đó đều là 1 là:
4. Cài đặt và Triển khai
4.1 Đề bài
Tuần trước, người viết có tham gia một cuộc thi tối ưu thuật toán tại phòng và đã áp dụng Bloom filter vào việc tối ưu. Mô tả sơ qua đề bài, cho tập file dữ liệu chứa MD5 mã độc, ta cần tổ chức thuật toán kiểm tra và tìm kiếm MD5 input đầu vào để đạt 2 tiêu chí: kích thước bộ nhớ RAM cần dùng là nhỏ nhất và dưới 10MB, thời gian tìm kiếm 1 MD5 nhỏ nhất và dưới 10ms.
Kích thước file là khoảng 13MB
4.2 Tổ chức thuật toán
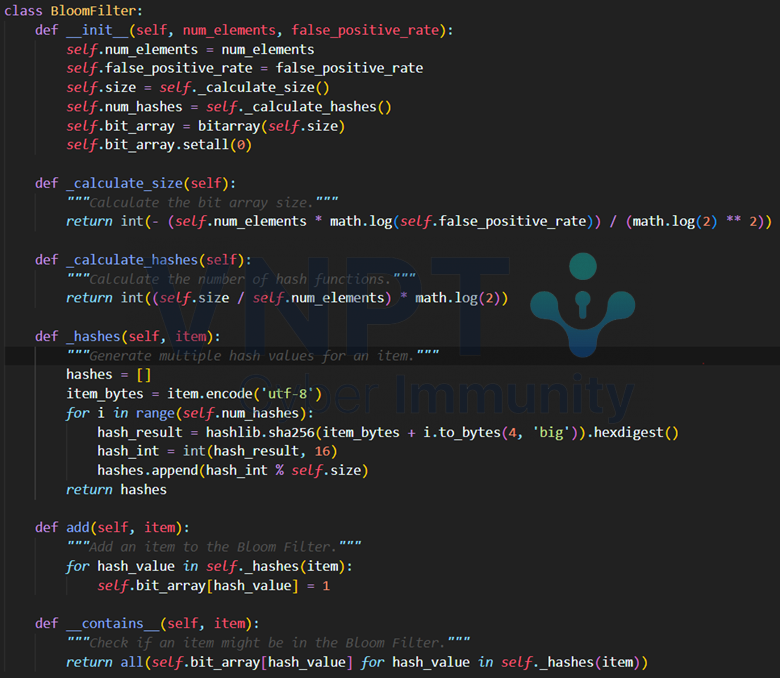
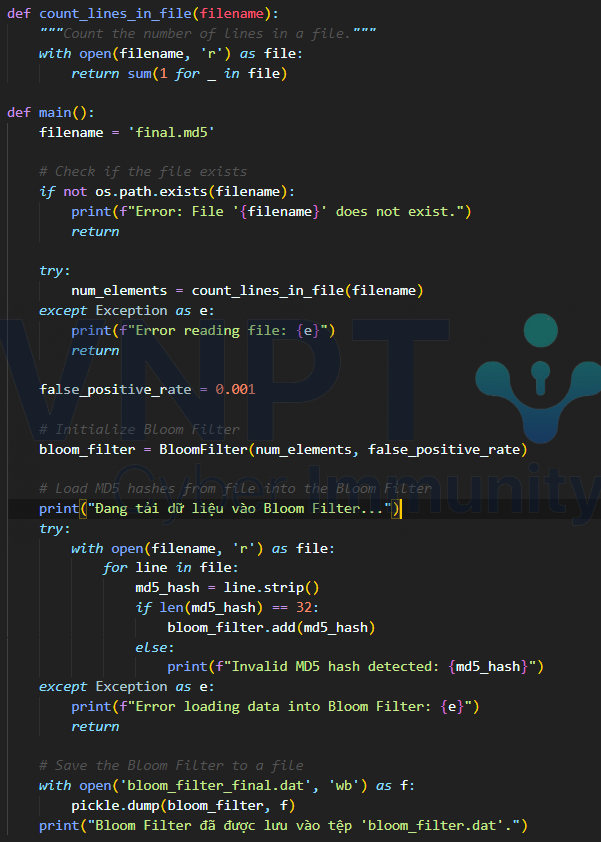
- Bloom_filter_class.py
Khai báo cài đặt cấu trúc Bloom_filter với các hàm cần dùng để xử lý
- data_processing.py
Đọc vào từng dòng từ file dữ liệu, tiền xử lý dữ liệu và lưu ra file .dat
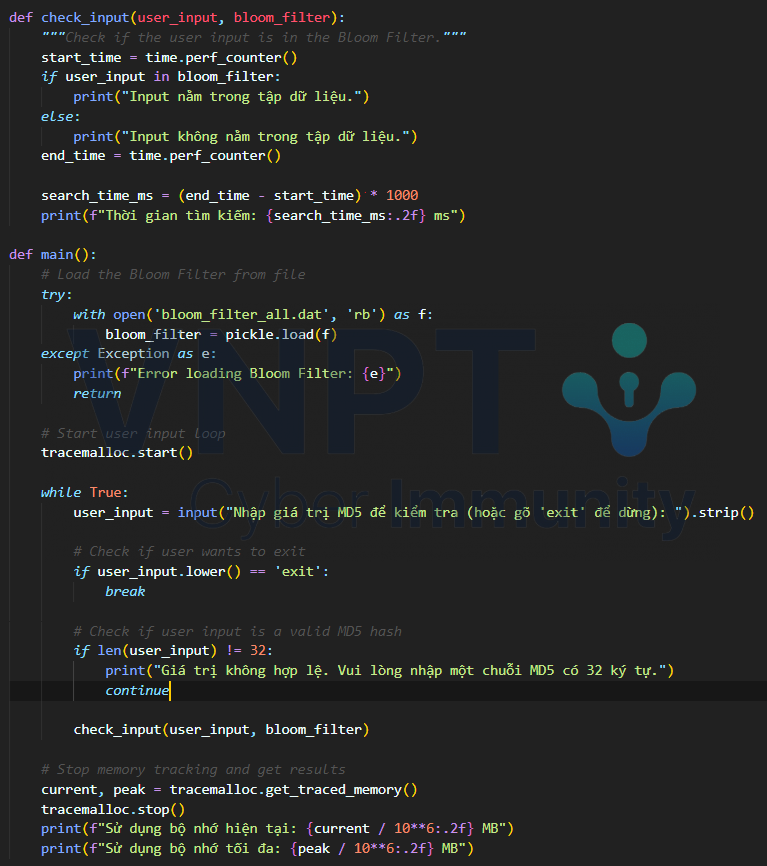
- search.py
Thực hiện việc tìm kiếm dữ liệu cũng như tính toán thời gian và bộ nhớ đã sử dụng
4.3 Đánh giá hiệu năng
Tất cả đều đạt các tiêu chí đề ra, lượng memory sử dụng là dưới 10MB, thời gian tìm kiếm dưới 10ms với tỉ lệ false positive là 0,1%.
Người viết cũng đã thử test với tập dữ liệu lớn hơn: final.md5 (~1,3GB và chứa ~42 triệu dòng). Kết quả thu được cũng ngoài mong đợi:
Với tập dữ liệu lớn, kết quả tìm kiếm vẫn cho rất nhanh, tuy nhiên để giữ được tỉ lệ false positive là 0,1%, ta sẽ phải đánh đổi bằng lượng memory sử dụng khá cao.
5. ỨNG DỤNG THỰC TIỄN
- Google BigTable, Apache HBase, Apache Cassandra, RocksDb (nói chung là rất nhiều DB NoSQL khác nhau) và PostgreSQL sử dụng Bloom Filter để giảm chi phí tìm kiếm dữ liệu.
- Mediumdùng để tránh gợi ý lại những bài viết mà user đã đọc.
- Hạn chế DDoS Attack
- Kiểm tra chính tả bằng cách kiểm tra các từ tồn tại trong từ điển.
- Kiểm tra weak password hoặc username/email đã tồn tại trong hệ thống.
- Google Chrome sử dụng để lọc ra và cảnh báo những trang web gây hại cho người dùng.
ƯU ĐIỂM
- Tiết kiệm bộ nhớ: Bloom Filter sử dụng rất ít bộ nhớ để lưu trữ thông tin về sự tồn tại của phần tử trong tập dữ liệu, đặc biệt là khi so sánh với các cấu trúc dữ liệu khác như bảng băm hay cây nhị phân.
- Tốc độ kiểm tra nhanh: Với khả năng kiểm tra sự tồn tại của một phần tử trong thời gian hằng số O(k) (với k là số hàm băm), Bloom Filter giúp giảm đáng kể chi phí truy vấn so với việc tìm kiếm toàn bộ trong cơ sở dữ liệu.
NHƯỢC ĐIỂM
- Vẫn còn tồn tại False Positive: có thể xác định sai rằng một phần tử tồn tại trong tập dữ liệu khi thực tế không phải vậy (false positive). Điều này có nghĩa là không thể chắc chắn tuyệt đối về kết quả tìm kiếm, đặc biệt quan trọng trong các ứng dụng yêu cầu độ chính xác cao.
- Không hỗ trợ xóa phần tử ra khỏi tập dữ liệu, vì khi xóa 1 phần tử của tập dữ liệu, điều này sẽ làm ảnh hưởng tới bảng băm. Biến thể của Bloom filter là Counting Bloom filter giải quyết vấn đề này nhưng phức tạp và tốn tài nguyên hơn.
- Không lưu trữ chính xác dữ liệu, chỉ lưu trữ sự tồn tại của phần tử theo dạng xác suất. Điều này giới hạn trong việc truy xuất dữ liệu.
REFERENCE
1828 lượt xem