Xin chào các anh em,
Lâu rồi mình chưa viết gì trên VCI blog, đợt này team mình quyết tâm rèn bút để mang đến cho anh em đồng nghiệp những bài blog thật chất lượng và có tính ứng dụng cao. Hy vọng đem những gì chúng mình tìm hiểu được chia sẻ để lan tỏa tới cộng đồng và nhận lại được những góp ý chân thành và thiện chí để cùng nhau phát triển, tiến bộ và hoàn thiện các sản phẩm của mình hơn.
Lần này chúng mình chọn chủ để Elasticsearch với một góc tiếp cận thú vị: tăng hiệu năng Elasticsearch với Apache Kafka và bulk Insert.
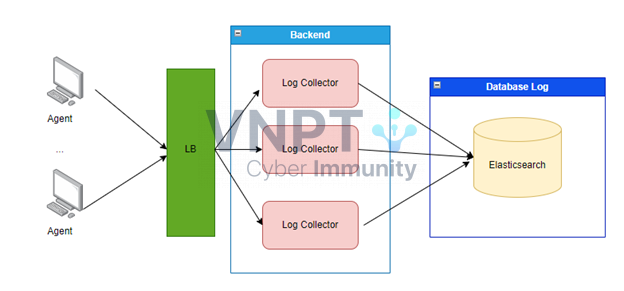 Hệ thống ban đầu được thiết kế như sau:
Log Collector là thành phần sẽ nhận và xử lý log từ Agent gửi về. Do lượng Log từ Agent gửi về lớn trước các con Log Collector sẽ đặt thêm LB để có thể chịu tải tốt hơn.
Trong thiết kế này thì nút thắt về hiệu năng và tính mở rộng của hệ thống sẽ nằm ở Database Log, tức là Elasticsearch. Elasticsearch trong hệ thống của bọn mình thường xuyên bị đỏ và thỉnh thoảng có hiện tượng chết node mà không có nguyên nhân. Để đảm bảo cho hệ thống không bị chết thì chúng mình phải cắt bớt một số dữ liệu log không cần thiết và tiến hành tối ưu log trước khi nó đổ về ES.
Về lý thuyết thì bản thân ES có tính mở rộng rất tốt. ES được thiết kế theo mô hình phân tán và nếu đến giới hạn thì cắm thêm node, mở rộng thêm tài nguyên thì sẽ nâng được tải cho hệ thống.
Tuy nhiên việc mở rộng ES như vậy khá là tốn kém và tốn chi phí về mặt tài nguyên. Chúng ta sẽ tìm cách tăng hiệu năng tính toán của ES bằng các biện pháp tối ưu về mặt công nghệ trước khi quyết định mở rộng về mặt phần cứng.
Bản thân chúng mình cũng không chắc chắn việc cắm thêm node sẽ giúp hệ thống bớt lăn ra chết nếu chạy hết công suất theo thiết kế ban đầu. Do đó tiếp cận về công nghệ là biện pháp cần thực hiện trước với chi phí bỏ ra ít hơn.
Phân tích ES hiện tại:
Kiến trúc hiện tại thì dữ liệu sẽ được đẩy trực tiếp từ Log Collector vào ES theo từng bản ghi nhỏ lẻ. Phần lớn hiệu năng của ES là để insert dữ liệu. Việc insert trực tiếp cũng khiến ban ngày ES hoạt động rất nhiều mà ban đêm có khi lại chơi, làm việc như nhân viên văn phòng.
Đề xuất hướng tối ưu:
Để phân tải cho ES đều hơn thì chúng mình sẽ đưa Queue vào hệ thống, cụ thể ở đây là Apache Kafka (https://kafka.apache.org/).
Để tránh cho ES phải xử lý từng bản ghi nhỏ lẻ trong khi bản thân ES có thể xử lý theo lô thì chúng mình sẽ sử dụng bulk Insert (https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html).
Thiết kế hệ thống mới:
Hệ thống ban đầu được thiết kế như sau:
Log Collector là thành phần sẽ nhận và xử lý log từ Agent gửi về. Do lượng Log từ Agent gửi về lớn trước các con Log Collector sẽ đặt thêm LB để có thể chịu tải tốt hơn.
Trong thiết kế này thì nút thắt về hiệu năng và tính mở rộng của hệ thống sẽ nằm ở Database Log, tức là Elasticsearch. Elasticsearch trong hệ thống của bọn mình thường xuyên bị đỏ và thỉnh thoảng có hiện tượng chết node mà không có nguyên nhân. Để đảm bảo cho hệ thống không bị chết thì chúng mình phải cắt bớt một số dữ liệu log không cần thiết và tiến hành tối ưu log trước khi nó đổ về ES.
Về lý thuyết thì bản thân ES có tính mở rộng rất tốt. ES được thiết kế theo mô hình phân tán và nếu đến giới hạn thì cắm thêm node, mở rộng thêm tài nguyên thì sẽ nâng được tải cho hệ thống.
Tuy nhiên việc mở rộng ES như vậy khá là tốn kém và tốn chi phí về mặt tài nguyên. Chúng ta sẽ tìm cách tăng hiệu năng tính toán của ES bằng các biện pháp tối ưu về mặt công nghệ trước khi quyết định mở rộng về mặt phần cứng.
Bản thân chúng mình cũng không chắc chắn việc cắm thêm node sẽ giúp hệ thống bớt lăn ra chết nếu chạy hết công suất theo thiết kế ban đầu. Do đó tiếp cận về công nghệ là biện pháp cần thực hiện trước với chi phí bỏ ra ít hơn.
Phân tích ES hiện tại:
Kiến trúc hiện tại thì dữ liệu sẽ được đẩy trực tiếp từ Log Collector vào ES theo từng bản ghi nhỏ lẻ. Phần lớn hiệu năng của ES là để insert dữ liệu. Việc insert trực tiếp cũng khiến ban ngày ES hoạt động rất nhiều mà ban đêm có khi lại chơi, làm việc như nhân viên văn phòng.
Đề xuất hướng tối ưu:
Để phân tải cho ES đều hơn thì chúng mình sẽ đưa Queue vào hệ thống, cụ thể ở đây là Apache Kafka (https://kafka.apache.org/).
Để tránh cho ES phải xử lý từng bản ghi nhỏ lẻ trong khi bản thân ES có thể xử lý theo lô thì chúng mình sẽ sử dụng bulk Insert (https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html).
Thiết kế hệ thống mới:
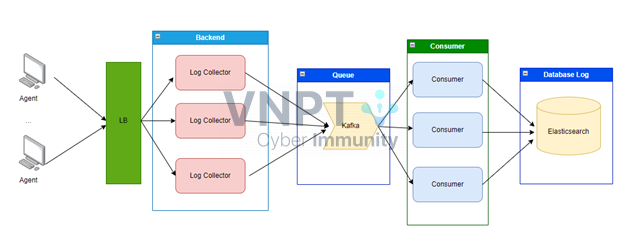 Trong thiết kế mới thì Log Collector sẽ đóng vai trò kafka Producer để đẩy dữ liệu vào kafka.
Mỗi Consumer sẽ phụ trách một loại log khác nhau. Các log có nhiều dữ liệu thì sẽ do một nhóm nhiều consumer phụ trách.
Bây giờ chúng ta sẽ thực hiện việc tối ưu đẩy log vào ES trên các Consumer, nhóm chúng mình sẽ đề ra 3 tham số sau:
Trong thiết kế mới thì Log Collector sẽ đóng vai trò kafka Producer để đẩy dữ liệu vào kafka.
Mỗi Consumer sẽ phụ trách một loại log khác nhau. Các log có nhiều dữ liệu thì sẽ do một nhóm nhiều consumer phụ trách.
Bây giờ chúng ta sẽ thực hiện việc tối ưu đẩy log vào ES trên các Consumer, nhóm chúng mình sẽ đề ra 3 tham số sau:
 Việc sử dụng Tool monitor giúp chúng mình tính toán được lượng dữ liệu log của từng loại từ đó quyết định được số lượng consumer cần thiết để xử lý chúng.
Cứ tăng số lượng bản ghi insert đồng thời vào ES cho tới khi bạn thấy ES vẫn ổn và lượng log của bạn được xử lý hết.
Chỗ này bọn mình chỉ nêu ý tưởng chính còn không định nghĩa ra một công thức chuẩn nào cả. Nó phụ thuộc vào tài nguyên và dữ liệu log của các bạn. Miễn là hệ thống chạy tốt là được.
Việc sử dụng Tool monitor giúp chúng mình tính toán được lượng dữ liệu log của từng loại từ đó quyết định được số lượng consumer cần thiết để xử lý chúng.
Cứ tăng số lượng bản ghi insert đồng thời vào ES cho tới khi bạn thấy ES vẫn ổn và lượng log của bạn được xử lý hết.
Chỗ này bọn mình chỉ nêu ý tưởng chính còn không định nghĩa ra một công thức chuẩn nào cả. Nó phụ thuộc vào tài nguyên và dữ liệu log của các bạn. Miễn là hệ thống chạy tốt là được.
Vấn đề chúng mình gặp phải với hệ thống cũ
Hệ thống ban đầu được thiết kế như sau:
Log Collector là thành phần sẽ nhận và xử lý log từ Agent gửi về. Do lượng Log từ Agent gửi về lớn trước các con Log Collector sẽ đặt thêm LB để có thể chịu tải tốt hơn.
Trong thiết kế này thì nút thắt về hiệu năng và tính mở rộng của hệ thống sẽ nằm ở Database Log, tức là Elasticsearch. Elasticsearch trong hệ thống của bọn mình thường xuyên bị đỏ và thỉnh thoảng có hiện tượng chết node mà không có nguyên nhân. Để đảm bảo cho hệ thống không bị chết thì chúng mình phải cắt bớt một số dữ liệu log không cần thiết và tiến hành tối ưu log trước khi nó đổ về ES.
Về lý thuyết thì bản thân ES có tính mở rộng rất tốt. ES được thiết kế theo mô hình phân tán và nếu đến giới hạn thì cắm thêm node, mở rộng thêm tài nguyên thì sẽ nâng được tải cho hệ thống.
Tuy nhiên việc mở rộng ES như vậy khá là tốn kém và tốn chi phí về mặt tài nguyên. Chúng ta sẽ tìm cách tăng hiệu năng tính toán của ES bằng các biện pháp tối ưu về mặt công nghệ trước khi quyết định mở rộng về mặt phần cứng.
Bản thân chúng mình cũng không chắc chắn việc cắm thêm node sẽ giúp hệ thống bớt lăn ra chết nếu chạy hết công suất theo thiết kế ban đầu. Do đó tiếp cận về công nghệ là biện pháp cần thực hiện trước với chi phí bỏ ra ít hơn.
Phân tích ES hiện tại:
Kiến trúc hiện tại thì dữ liệu sẽ được đẩy trực tiếp từ Log Collector vào ES theo từng bản ghi nhỏ lẻ. Phần lớn hiệu năng của ES là để insert dữ liệu. Việc insert trực tiếp cũng khiến ban ngày ES hoạt động rất nhiều mà ban đêm có khi lại chơi, làm việc như nhân viên văn phòng.
Đề xuất hướng tối ưu:
Để phân tải cho ES đều hơn thì chúng mình sẽ đưa Queue vào hệ thống, cụ thể ở đây là Apache Kafka (https://kafka.apache.org/).
Để tránh cho ES phải xử lý từng bản ghi nhỏ lẻ trong khi bản thân ES có thể xử lý theo lô thì chúng mình sẽ sử dụng bulk Insert (https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html).
Thiết kế hệ thống mới:
Trong thiết kế mới thì Log Collector sẽ đóng vai trò kafka Producer để đẩy dữ liệu vào kafka.
Mỗi Consumer sẽ phụ trách một loại log khác nhau. Các log có nhiều dữ liệu thì sẽ do một nhóm nhiều consumer phụ trách.
Bây giờ chúng ta sẽ thực hiện việc tối ưu đẩy log vào ES trên các Consumer, nhóm chúng mình sẽ đề ra 3 tham số sau:
- Số lượng Consumer cho loại log đó.
- Số bản ghi thực hiện bulk Insert.
- Thời gian tối đa bản ghi cần được insert vào ES.
Việc sử dụng Tool monitor giúp chúng mình tính toán được lượng dữ liệu log của từng loại từ đó quyết định được số lượng consumer cần thiết để xử lý chúng.
Cứ tăng số lượng bản ghi insert đồng thời vào ES cho tới khi bạn thấy ES vẫn ổn và lượng log của bạn được xử lý hết.
Chỗ này bọn mình chỉ nêu ý tưởng chính còn không định nghĩa ra một công thức chuẩn nào cả. Nó phụ thuộc vào tài nguyên và dữ liệu log của các bạn. Miễn là hệ thống chạy tốt là được.
Một số vấn đề khác cần quan tâm
Khi triển khai mô hình này thì có một số vấn đề cần mình nghĩ các bạn sẽ cần quan tâm. Mình nêu trước ra đây mà chưa bàn tới cách bọn mình sẽ xử lý chúng thế nào. Hy vọng các bạn cũng sẽ suy nghĩ và trong bài viết kế tiếp chúng ra sẽ bàn qua về chúng :D- Chúng ta sẽ báo cho kafka là đã xử lý xong bản ghi (kafka commit) khi vừa lấy bản ghi ra hay khi đã insert xong nó vào ES?
- Nếu bulk Insert báo lỗi thì chúng ta làm gì với dữ liệu vừa được đẩy vào không thành công? Liệu chấp nhận dữ liệu sẽ bị mất hay cần thiết kế để đẩy lại dữ liệu?
- Kafka hoạt động sẽ chiếm một lượng dữ liệu ổ cứng tương đối lớn, làm cách nào để tối ưu chúng phù hợp với điều kiện tài nguyên của chúng ta?
- Nếu Kafka hoặc ES bị chết thì server của chúng ta có bị ùn ứ dữ liệu không? Làm thế nào bây giờ?
Kết quả chúng mình đạt được
Hiện tại chúng mình đã chạy thiết kế mới được một thời gian và ES cũng không gặp phải vấn đề gì. Các dữ liệu log đã được đẩy lên đầy đủ, tài nguyên cũng không cần cấp phát thêm mới. Nhìn chung là hài lòng với kết quả đạt được. Hệ thống này của chúng mình vẫn còn rất nhiều điểm thắt khác cần tối ưu, do đó chúng mình sẽ tiếp tục bàn về chủ đề này trong thời gian tới. Hy vọng nhận được sự quan tâm của anh em bạn bè. From R&D team with love <3. 856 lượt xem