Khi sử dụng IDA để phân tích code các file thực thi viết bằng ngôn ngữ C++, chúng ta sẽ thấy rằng hầu hết các hàm IDA phân tích ra đều là các hàm trong những thư viện có sẵn của C++. Thâm chí khi build Chương trình bằng Visual Studio thì chúng ta sẽ phải bơi qua vài hàm rồi mới vào được tới hàm main của mình.
Vậy sẽ ra sao nếu IDA không nhận diện được các hàm thư viện hoặc nhận diện thiếu?
Nếu là chương trình của mình thì có thể chúng ta sẽ tự đi tìm các string rồi sau đó nhảy đến chỗ code của mình. Nhưng đa số những người dùng IDA là đi ngắm chương trình của người khác. Do đó chắc chắc là sẽ phải bơi trong một đống các code thư viện có sẵn đó để tìm cho ra được thứ có giá trị :D
Có thể bạn coi đó là thứ mặc định nên không đánh giá nó là một thứ quan trọng, nhưng với mình nó là một tính năng rất thú vị, ẩn sau nó là một giải pháp rất hay và có thể áp dụng cho nhiều vấn đề khác . IDA đã public cách họ làm tại đây: https://hex-rays.com/products/ida/tech/flirt/in_depth/
Sau đây mình sẽ trình bày lại ý tưởng của họ và có một số nhận xét thêm của riêng mình.

 Việc tổ chức theo dạng cây có 2 ưu điểm:
Việc tổ chức theo dạng cây có 2 ưu điểm:
 Đa số các hàm thư viện chỉ cần tới dấu hiệu này để phân biệt được. Nhưng thỉnh thoảng vẫn có các hàm thư viện giống nhau tiếp, thậm chí chúng có thể giống nhau toàn bộ ở các bytes không biến thể, chỉ khác nhau ở các bytes biến thể
Dấu hiệu tiếp theo được nhận diện là kiểm tra bytes được tham chiếu đầu tiên là hàm thư viện nào?
Đa số các hàm thư viện chỉ cần tới dấu hiệu này để phân biệt được. Nhưng thỉnh thoảng vẫn có các hàm thư viện giống nhau tiếp, thậm chí chúng có thể giống nhau toàn bộ ở các bytes không biến thể, chỉ khác nhau ở các bytes biến thể
Dấu hiệu tiếp theo được nhận diện là kiểm tra bytes được tham chiếu đầu tiên là hàm thư viện nào?
 Cuối cùng thì vẫn có những hàm lọt qua cả 3 đặc điểm trên, IDA đành chấp nhận và bỏ qua việc nhận diện những hàm như vậy.
IDA có đề xuất sử dụng AI để giải quyết vấn đề này, nhưng mình đánh giá vấn đề A được giải quyết thì sẽ phát sinh vấn đề B. AI không thể đạt được độ chính xác 100% được. Sau nhiều năm thì ý tưởng đó vẫn là để “tương lai”.
Cuối cùng thì vẫn có những hàm lọt qua cả 3 đặc điểm trên, IDA đành chấp nhận và bỏ qua việc nhận diện những hàm như vậy.
IDA có đề xuất sử dụng AI để giải quyết vấn đề này, nhưng mình đánh giá vấn đề A được giải quyết thì sẽ phát sinh vấn đề B. AI không thể đạt được độ chính xác 100% được. Sau nhiều năm thì ý tưởng đó vẫn là để “tương lai”.
Đặt vấn đề
Khi người dùng thực hiện dịch ngược và phân tích một file thực thi, họ sẽ mất nhiều thời gian để phân tách các chức năng của hệ thống (các hàm thư viện). Quá trình phân tách này được lặp đi lặp lại mỗi lần phân tích một file, và điều đáng buồn là việc phân tách này hầu như không sinh ra tri thức mới. Chúng ta chỉ dừng lại ở việc xác định đây là thư viện nào? Là API nào? Và thậm chí trong nhiều thư viện phân tích được lại có logic không liên quan tới logic của chương trình. Theo thống kê của IDA, một chương trình thường chứa 50% code thư viện, nhiều chương trình có thể chứa 90 đến 95%. Việc sử dụng các framework, các thư viện chuẩn như OWL, MFC, … cũng làm cho lượng code thư viện nhiều lên. Nhưng mặc khác các chương trình lại được cấu trúc một cách chuẩn mực hơn. Một chương trình chuẩn viết bằng C, C++ có thể chưa khoảng 1000 đến 2500 hàm thư viện. Với các phân tích trên, IDA đã tạo ra một thuật toán để nhận diện các lời gọi đến các hàm thư viện tiêu chuẩn. Để thuật toán có tính thực tiễn (tốc độ thực thi nhanh và độ chính xác cao hoặc chấp nhận được), nhóm phát triển đã chấp nhận một số hạn chế:- Chỉ đề cập tới các chương trình viết bằng C/C++.
- Không cố gắp để đạt được sự hoàn hảo. Kết quả của thuật toán chỉ hướng tới “đủ tốt”, vì nhiều “điều kiện” mà một số hàm thư viện có thể không được nhận diện.
- Chỉ nhận diện các thư viện dựa trên đoạn mã, bỏ qua đoạn dữ liệu.
- Khi một thư viện được xác định, nó sẽ được gán tên, sẽ không có thêm thông tin về tham số và các hoạt động của hàm.
- Tránh hoàn toàn dương tính giả vì nó còn tệ hơn âm tính giả.
- IDA được thiết kế để có thể hỗ trợ nhiều bộ xử lý khác nhau do đó thuật toán cần được xây dựng để xử lý cho chương trình biên dịch cho bất kỳ bộ xử lý nào.
- Phải xác định được hàm Main, việc này quan trọng hơn điểm bắt đầu của chương trình nhiều khi không có nhiều ý nghĩa.
Các thách thức gặp phải khi xử lý vấn đề
1. Vấn đề bộ nhớ mà thư viện sử dụng
Các thư viện bao gồm nhiều version khác nhau (phiên bản cho từng bộ xử lý, các phiên bản update, …), nếu kết hợp giữa số hàm thư viện cần nhận diện với kích thước bộ nhớ chúng sử dụng ở từng phiên bản, kích thước data cần lưu trữ là rất lớn, có thể lên tới hàng trăm MB. Đây chỉ là một chức năng phụ trợ trong IDA, thật khó chấp nhận nếu như nó tiêu tốn dung lượng bộ nhớ lớn đến vậy. Do đó IDA cần có một thuật toán hiệu quả về mặt kết quả, đáp ứng tốt về mặt tài nguyên và hiệu năng. Các thuật toán tìm kiếm được thiết kế đơn giản (so sánh vùng nhớ) không phải là lựa chọn tốt.2. Sự thay đổi về địa chỉ vùng nhớ
Một khó khăn khác đến từ các bytes tham chiếu đến bộ nhớ trong code thư viện. Cấu trúc chương trình thực thi được thiết kế để có thể load lên các vùng nhớ khác nhau mà vẫn hoạt động được. Do đó các bytes vùng nhớ này là không cố định. Chúng được trình loader fix lại dựa trên relocation table khi được load lên các vùng địa chỉ khác nhau. Cách đơn giản là có thể bỏ qua không so sánh các bytes này, nhưng đôi khi 2 hàm thư viện lại giống hệt nhau chỉ khác nhau chúng có gọi 2 hàm khác nhau (liên quan tới giá trị của các bytes biến đổi).Ý tưởng thuật toán
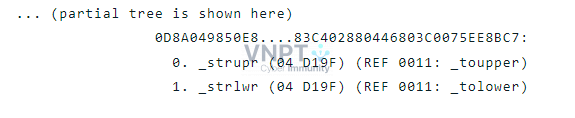
IDA tạo ra một cơ sở dữ liệu từ tất cả các hàm thư viện mà IDA “muốn” nhận diện. Khi chương trình được disassembled, các bytes có thể được kiểm tra xem chúng có thể là điểm bắt đầu của một hàm thư viện hay không? Thông tin nhận diện được được lưu trữ theo cấu trúc mẫu nhận diện sau:- 32 bytes đầu tiên của một hàm trong đó các byte biến thể đều được đánh dấu bằng “..”
- Một số hàm thư viện có các byte đầu giống nhau, do đó có thể tổ chức lại cấu trúc theo dạng cây
Việc tổ chức theo dạng cây có 2 ưu điểm:
- Giảm thiểu bộ nhớ cần lưu trữ
- Tìm kiếm theo cây có chi phí là Log(N)
Đa số các hàm thư viện chỉ cần tới dấu hiệu này để phân biệt được. Nhưng thỉnh thoảng vẫn có các hàm thư viện giống nhau tiếp, thậm chí chúng có thể giống nhau toàn bộ ở các bytes không biến thể, chỉ khác nhau ở các bytes biến thể
Dấu hiệu tiếp theo được nhận diện là kiểm tra bytes được tham chiếu đầu tiên là hàm thư viện nào?
Cuối cùng thì vẫn có những hàm lọt qua cả 3 đặc điểm trên, IDA đành chấp nhận và bỏ qua việc nhận diện những hàm như vậy.
IDA có đề xuất sử dụng AI để giải quyết vấn đề này, nhưng mình đánh giá vấn đề A được giải quyết thì sẽ phát sinh vấn đề B. AI không thể đạt được độ chính xác 100% được. Sau nhiều năm thì ý tưởng đó vẫn là để “tương lai”.
Triển khai thực tế trong IDA
Từ IDA 3.6 thuật toán này đã được sử dụng và đạt kết quả rất tốt.IDA mới dừng lại ở ngôn ngữ C và C++. Để đảm bảo hiệu năng về bộ nhớ và tốc độ tìm kiếm. IDA tổ chức mỗi bộ xử lý hay framework là một file signature. IDA sẽ tìm cách xác định chương trình cần phân tích thuộc loại nào để load đúng file signature tương ứng. IDA cũng cung cấp các tool để người dùng có thể quét và update thêm các hàm thư viện vào database để đạt được khả năng nhận diện cao hơnĐánh giá
Mình đã tự xây dựng và triển khai thuật toán trên của IDA và đánh giá rất cao hiệu quả của thuật toán này. Nó có thể giúp tiết kiệm 70% hoặc hơn nữa thời gian phân tích các chương trình. Để đảm bảo không nhận diện nhầm (dương tính giả) thì về mặt lý thuyết thuật toán chưa đảm bảo. Chỉ khi IDA có thể quét được toàn bộ các thư viện thì mới tránh được sự trùng lặp, chỉ cần các nhà phát triển vẫn update hàng ngày thì tương lai vẫn có thể có nhận diện nhầm. Nhưng có lẽ điều đó cũng sẽ không gây ra vấn đề gì lớn. 516 lượt xem