Tản mạn về Machine Learning trong Malware analysis
Người ta thường nói “không có điều gì dễ chịu và thoải mái hơn tiết trời của mùa thu Hà Nội”, nhưng so với những gì mà mình đang được trải nghiệm nó không đúng một chút nào cả (-_-). Ban ngày thì mặt trời như xối từng dòng lửa xuống mặt đất. Bầu trời thì trong xanh thật đấy, nhưng cảm giác ngắm nhìn bầu trời ấy trước một cái đèn đỏ khoảng 120 giây vào giữa buổi trưa thì nó cũng hơi sai sai thì phải :))) Đấy là những hôm trời nắng, còn với những hôm trời mưa thì coi như ông trời tự nhiên nổi hứng tổ chức giải bơi mở rộng dành riêng cho những bạn đi làm xa như mình đi (-_-).
Nhưng giáo sư Cù Trọng Xoay cũng đã nói rồi: “Nhiều người nghĩ vì vũ trụ xung quanh không cân bằng khiến cho bạn đau khổ, thực ra không phải. Khi vũ trụ nhỏ bên trong chúng ta cân bằng thì tất cả mọi thứ xung quanh sẽ cân bằng”.
Vậy nên, sau khi kết thúc một ngày làm việc vất vả, hãy mở một bản nhạc nhẹ, nhâm nhi tách cà phê, thả cho cơ thể thật thoải mái và cùng mình tản mạn về “Machine Learning trong Malware analysis” nhé.
Machine Learning
Ngày nay trên báo đài cũng đã nói rất nhiều về những công nghệ mới như Machine Learning, Deep Learning hay Artificial intelligence rồi, nên mình cũng sẽ không bàn thêm về lý thuyết nữa. Những bạn nào muốn tìm hiểu thêm về các khái niệm trên thì các bạn có thể search Google nhé.
Mặc dù vậy, mình cũng sẽ giải thích cho các bạn về Machine Learning theo một phong cách dân dã hơn nhé. Hãy cùng mình theo dõi ví dụ sau:
- Anh A là một nhân viên phân tích thị trường bất động sản. Công việc hằng ngày của anh là đi thu thập dữ liệu nhà đất như diện tích nhà, vị trí địa lý, hướng cửa ra vào, … Sau đó định giá cho những căn nhà đó.
- Mặc dù với một người có nhiều kinh nghiệm như anh thì mọi việc không có gì là khó khăn cho lắm, tuy nhiên lượng dữ liệu nhà đất thì càng ngày càng nhiều mà khả năng con người thì có hạn, do đó anh quyết định sẽ viết một phần mềm tự động để có thể giúp anh trong công việc.
- Phần mềm này cần phải xác định được một phương trình nào đó mà có thể tính toán giá trị của căn nhà dựa trên một loạt các giá trị đầu vào như diện tích, vị trí, hướng, … Các bạn có thể hiểu phương trình này nó sẽ có dạng nguyên thủy là y = a*x1 + b*x2 + c*x3 + … với (a, b, c) là các hệ số, (x1, x2, x3) là các biến đại diện cho các giá trị đầu vào như diện tích, vị trí, hướng … và y là giá trị của căn nhà (nhìn rất quen thuộc phải không nào).
- Để giải được phương trình này thì chúng ta sẽ cần rất nhiều các bộ giá trị (x1, x2, …, y) (giống với việc khi các bạn giải hệ phương trình thì các bạn cần nhiều cặp số (x, y) khác nhau vậy).
- Và phần mềm nêu trên có thể được coi là một dạng cơ bản nhất của Machine Learning. Quá trình sử dụng các bộ giá trị để giải phương trình sẽ được gọi là quá trình train model, còn quá trình sử dụng phương trình đó để tính toán trong thực tế sẽ được gọi là predict.
Okay, ngắn gọn lại thì Machine Learning là một giải pháp giúp chúng ta thực hiện các công việc tính toán phức tạp dựa trên một bộ dữ liệu đầu vào cho trước. Thế nhé, chuyển sang phần tiếp theo nào.
Machine Learning trong Malware analysis

Chắc cũng không cần phải nói nhiều về Malware analysis (phân tích mã độc) nữa, thực sự thì ngày nay nó đã trở thành một bộ phận không thể thiếu trong các công ty chuyên làm về Security rồi. Điều mà mình muốn nói ở đây là chúng ta sẽ áp dụng Machine Learning vào lĩnh vực này như thế nào cơ.
Được rồi, sau một quá trình khoảng 2 ngày dùi mài kinh sử, tìm hiểu đủ các loại tài liệu về phân tích mã độc trên thế giới thì mình cũng có đưa ra một số các hướng tiếp cận đáng được quan tâm nhất hiện nay như sau:
- Phân tích tĩnh (Static analysis): Đây là một quá trình sử dụng Machine Learning để phân loại mã độc dựa trên những dữ liệu thô của file (chẳng hạn như dung lượng file, số section, vị trí header, các hàm DLL được import, …). Ưu điểm của phương pháp này đó là nhanh; không cần thực thi file nên tránh được việc máy tính bị nhiễm virus. Tuy nhiên nhược điểm của phương pháp này là độ chính xác không được cao cho lắm, bởi càng ngày thì Malware sẽ càng được thiết kế sao cho giống với một file thực thi thông thường.
- Trái ngược với phân tích tĩnh đó là Phân tích động (Dynamic analysis): Đây là một quá trình phân tích mã độc dựa trên chuỗi lệnh API Call mà file đó thực hiện. Ưu điểm của phương pháp này đó là độ chính xác cao hơn nhiều so với phương pháp phân tích tĩnh, tuy nhiên phương pháp này đòi hỏi chúng ta phải thực thi file, do đó cần có một môi trường sandbox để tránh trường hợp mã độc đó gây tổn hại tới hệ thống thật. Việc cấu hình hệ thống với một môi trường sandbox đi kèm chắc chắn sẽ phức tạp hơn, và độ trễ cũng sẽ cao hơn nhiều so với quá trình phân tích tĩnh.
Hãy thử cả 2 phương pháp trên xem thế nào nhé.
Static analysis
Hãy cùng mình ngó qua mô hình mà mình tự thiết kế đã nhé, cũng đơn giản thôi:
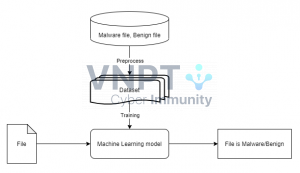
Đây là mô hình cơ bản của phương pháp phân tích tĩnh. Trong mô hình này thì chúng ta sẽ phải làm 3 công viêc chính: Tiền xử lý dữ liệu (Preprocess), Xây dựng model (Training) và áp dụng nó để phân tích file thực thi.
Trước khi bắt đầu tìm hiểu về phân tích tĩnh thì chúng ta cần phải hiểu cấu trúc của một file thực thi nó trông như thế nào đã. Cho đến thời điểm hiện tại thì trên thế giới đã có tới hàng chục, thậm chí là hàng trăm định dạng file thực thi khác nhau, tuy nhiên vì phạm vi của bài viết này có hạn nên chúng ta sẽ chỉ đi sâu vào 1 trong những định dạng phổ biến nhất, đó là PE file (Portable Executable). Ngoài ra các bạn cũng có thể tìm hiểu thêm về một định dạng file cũng phổ biến không kém, đó là ELF (Executable and Linkable Format).
Giới thiệu sơ qua một chút, PE là một định dạng file thực thi phổ biến được sử dụng trong các phiên bản 32-bit và 64-bit của hệ điều hành Windows. Hầu hết các file có đuôi phổ biến như “.dll”, “.drv”, “.efi”, “.exe”, “.mui”, … đều là một trong những định dạng của PE file.
Song song với PE thì ELF cũng là một định dạng file thực thi phổ biến bậc nhất hiện nay, nhưng là dành cho các phiên bản của hệ điều hành Linux chứ không phải Windows.
Được rồi, đi sâu thêm về PE nhé. Các bạn có thể tham khảo hình sau (hình này mình lượm lặt được trên google thôi, nhưng mà nó khá đúng :)))
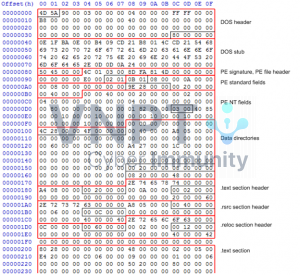
Đây là cấu trúc của một file PE khi chúng ta nhìn file dưới dạng Hexa. Chúng ta có thể thấy một file PE sẽ được cấu thành từ rất nhiều các thành phần khác nhau như DOS header, PE file header, PE NT header, …
Lý do mà chúng ta có thể nhận biết được Malware dựa trên những dữ liệu này là bởi thông thường thì kẻ tấn công sẽ chèn một đoạn mã độc vào một trong những section hiện có, hoặc thực hiện một lệnh jump đến một section mà kẻ tấn công chèn thêm vào. Điều này sẽ dẫn đến việc làm sai lệch các thông số như độ lớn của section, số lượng section, địa chỉ bắt đầu và kết thúc của section, … Và từ đó thuật toán Machine Learning có thể nhận biết được các sai lệch đó.
Tuy nhiên nhìn dưới dạng Hexa thì hơi khó hình dung phải không, vậy nên hãy cùng mình dạo qua một vài dòng code cho nó thay đổi không khí nhé ^^. Thông tin về ngôn ngữ lập trình thì mình sử dụng phiên bản Python 3.10, cùng với thư viện “pefile”.
Được rồi, bắt đầu đơn giản thôi nhé, mình sẽ thử phân tích file “Zalo.exe”:
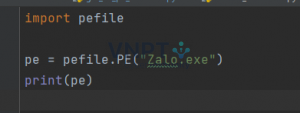
Khi chạy đoạn code này lên, bạn sẽ thấy đầu ra của nó cực kỳ dài luôn:

Nhưng đừng lo lắng, thư viện pefile có đầy đủ những phương thức hỗ trợ chúng ta bóc tách file thực thi ra thành từng thành phần riêng rẽ. Cùng mình thử lại nhé, nhưng lần này hãy thêm “DOS_HEADER” vào sau biến “pe”.
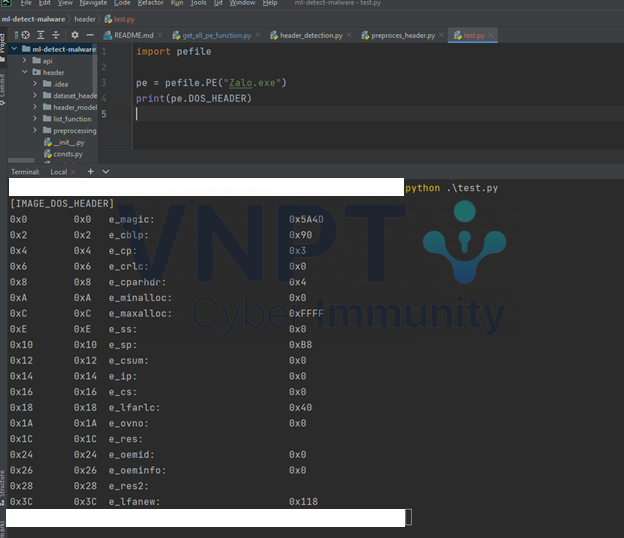
Đầu ra dễ nhìn hơn rồi phải không nào 😊)) chi tiết ý nghĩa của các thuộc tính như e_magic, e_cblp, … thì các bạn hãy tìm hiểu google nhé, không thiếu cái gì đâu.
Hãy thử chạy thêm nhiều lần tương tự như trên, nhưng thay “DOS_HEADER” bằng “NT_HEADERS”, “FILE_HEADER” và “OPTIONAL_HEADER” nhé.
Được rồi, hãy tạm bỏ qua phần tìm hiểu ở đây nhé. Tiếp theo chúng ta cần phải lập trình ra một đoạn script nhằm phục vụ mục đích thu thập dữ liệu cho quá trình training Machine Learning model.
Một bộ dữ liệu đầu vào cho Machine Learning model sẽ bao gồm rất nhiều các file PE, và một dữ liệu file PE sẽ bao gồm thông tin về tất cả các trường trong đó (chẳng hạn như e_magix, e_cblp, …).
Hãy lập trình một hàm thu thập thông tin về tất cả các trường trong 1 file PE như sau:
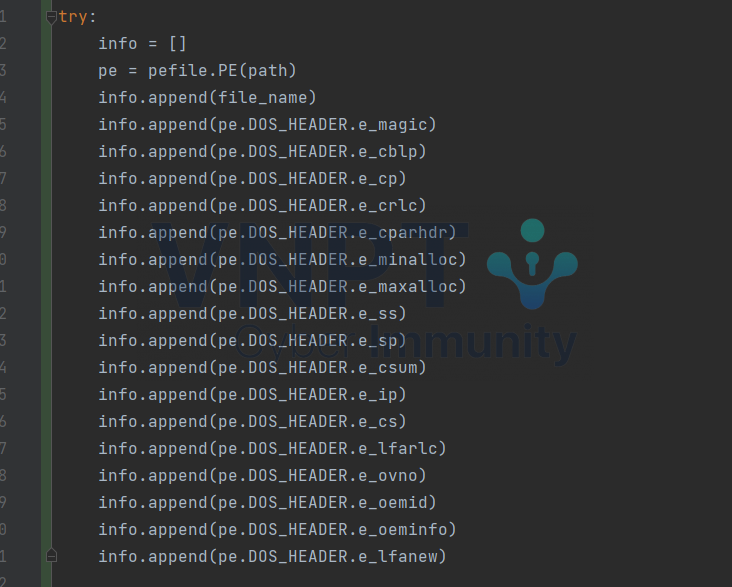
Có những thông tin nào hữu ích, các bạn cứ append hết vào ^^ cái này là mình chỉ chụp 1 đoạn thôi, chứ còn code phần dưới sẽ còn rất dài nữa vì còn rất nhiều thông tin của file cần được khai thác như “NT_HEADERS”, “FILE_HEADER” và “OPTIONAL_HEADER”. Như mình đã code, các bạn nên ném hết nó vào một cấu trúc “try-except”, vì có nhiều file sai cấu trúc nên code sẽ rất dễ xảy ra lỗi.
Các bạn hãy append thêm một trường nữa đó là “type” của file, tức file đó là Malware hay Benign ấy. Cái này để cho đơn giản thì các bạn hãy chia các file vào 2 folder riêng biệt là Malware và Benign, sau đó đánh nhãn một loại cho tất cả các file có trong folder tương ứng.
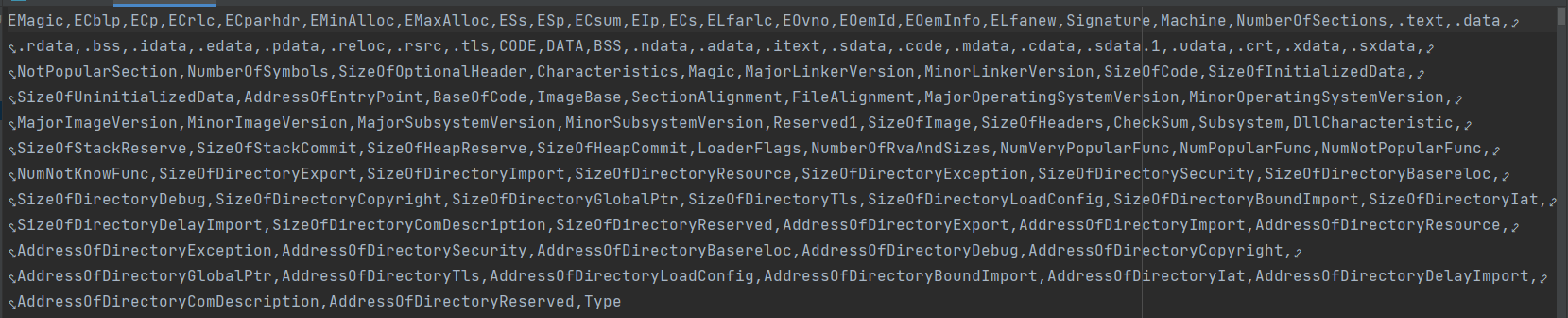
Tổng kết lại, 1 dữ liệu của mình sẽ có các trường như sau (hơi rối, nhìn tạm nhé):
Sau khi đã có 1 hàm phân tích dữ liệu, viêc tiếp theo là chúng ta cần 1 hàm scan để đọc tất cả các file có trong một folder. Hàm này thì đơn giản, các bạn có thể tham khảo code của mình:
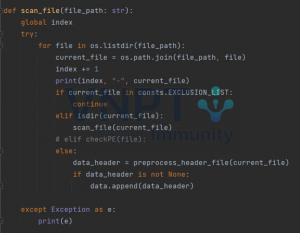
Trong đó hàm “preprocess_header_file” là hàm mà chúng ta đã viết phía trên.
Xong phần tiền xử lý dữ liệu, các bạn hãy kiếm càng nhiều file PE càng tốt và thực hiện thu thập dữ liệu nhé.
Tiếp theo là phần training, các bạn có thể tham khảo code của mình. Ở đây mình sử dụng thuật toán Random Forest, còn tùy theo nhu cầu của các bạn mà hãy tự thay đổi thuật toán cho phù hợp nhé.
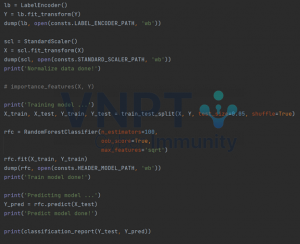
Okay, theo như mình thực nghiệm thì độ chính xác của phương pháp này chỉ đạt con số khoảng 72-73%, gọi là tạm chấp nhận được với một phương pháp phân tích tĩnh.
Dynamic analysis
Tại sao chúng ta lại có thể nhận biết được Malware dựa trên chuỗi lệnh API Call nhỉ? Hãy cùng mình suy ngẫm về một ví dụ sau nhé:
- Đầu tiên hãy giả sử chúng ta có một chuỗi gọi là “…. ntcreatefile, getfilesize, ntcreatesection, …”, đây sẽ là một chuỗi gọi rất thông thường, và chúng ta có thể dự đoán hành động của file thực thi này là “tạo file -> lấy thông tin dung lượng -> tạo section trong file”.
- Tuy nhiên hãy xem xét chuỗi gọi sau: “… ntfreevirtualmemory, ntclose, ntterminateprocess, ntcreatefile, getfilesize, ntcreatesection”, các bạn đã thấy sự khác biệt chưa? Chuỗi 3 lệnh đầu “ntfreevirtualmemory, ntclose, ntterminateprocess” thường sẽ là chuỗi lệnh để kết thúc hành động của một file, cụ thể các lệnh đó lần lượt là “giải phóng bộ nhớ -> đóng các thư viện -> dừng tiến trình”. Tuy nhiên sau đó các bạn lại thấy 3 lệnh giống y hệt với ví dụ trước, điều này chứng tỏ nó đã được kẻ tấn công thêm vào phần sau của file thực thi, và file này có khả năng cao là một Malware.
Ở phương pháp này thì chúng ta sẽ cần một bộ dữ liệu về danh sách các lệnh API Call được gọi bởi file thực thi trong suốt quá trình runtime. Để làm được điều đó thì chúng ta cần phải triển khai một môi trường Sandbox để tránh việc Malware có thể gây hại cho hệ thống thật. Có 2 thứ mà mình khuyến nghị triển khai trong phần này:
- Cuckoo Sandbox: Nếu các bạn là một dân chuyên trong lĩnh vực bảo mật thì hẳn các bạn sẽ không còn lạ gì với Cuckoo Sandbox nữa. Đây là một môi trường ảo có tích hợp rất nhiều các công cụ khác nhau hỗ trợ cho việc phân tích Malware, và một trong số đó là công cụ giúp chúng ta có thể lấy được chuỗi API Call Sequence.
- NtTrace: Đối với một số file có định dạng không chính xác, thì Cuckoo Sandbox sẽ không thể trích xuất chuỗi API Call được. Khi đó NtTrace sẽ là giải pháp thay thế, khi mà NtTrace sẽ chỉ trích xuất các lệnh gọi liên quan tới thư viện ntdll.dll.
Được rồi, hãy lại cùng mình ngó qua một chút về mô hình mà mình đã thiết kế cho phương pháp phân tích động nhé:
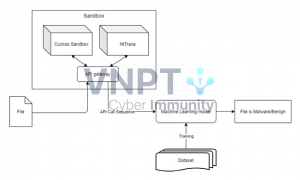
Phần thu thập dữ liệu này thì chúng ta dùng sẵn 1 trong 2 công cụ trên, do đó không có code cho phần này. Nhìn chung thì 1 dữ liệu API Call sẽ có dạng như sau:
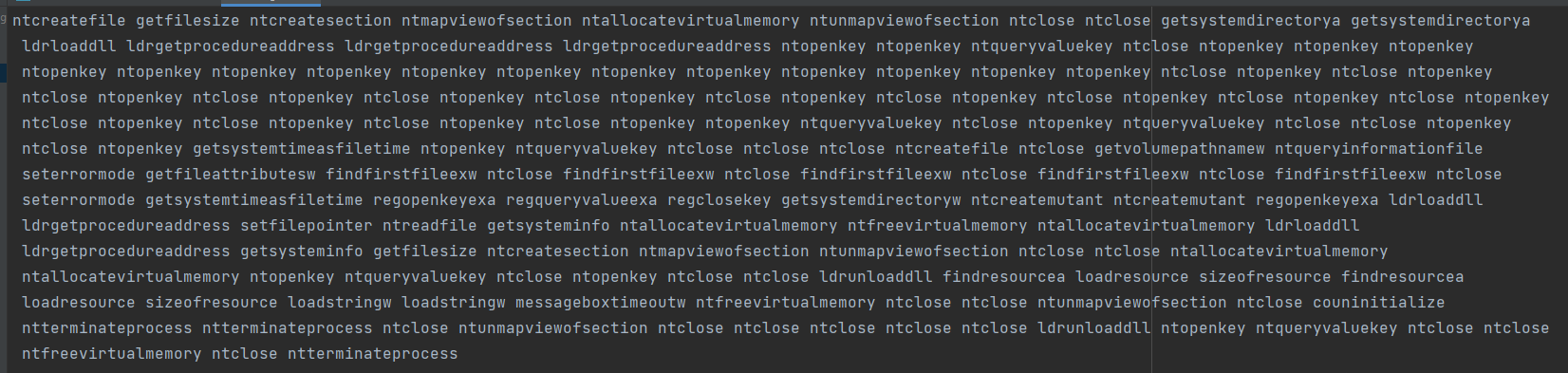
Đối với những mô hình phân loại dựa trên dữ liệu chuỗi (ví dụ mô hình dự đoán giá cổ phiếu tăng giảm :v hoặc mô hình dự đoán giá nhà lên hay xuống, …) thì chúng ta thường sẽ sử dụng các thuật toán Deep Learning như LSTM. Phần này thì thay vì code mẫu, mình sẽ giới thiệu các bạn một project có sẵn được public trên github luôn. Hãy sử dụng nó với mục đích tìm hiểu thôi nhé, và hãy ghi rõ nguồn nếu bạn muốn trích dẫn nó ở bất kỳ đâu trong bài viết của bạn.
Tất nhiên rồi, phương pháp này đạt độ chính xác cao hơn hẳn so với phương pháp phân tích tĩnh (86-87%). Tuy nhiên thời gian để phân tích 1 file mất đâu đó khoảng 40s cho đến 1 phút tùy theo dung lượng của file, trong khi đó phương pháp phân tích tĩnh chỉ mất khoảng 2s cho 1 file.
Kết luận
Việc áp dụng công nghệ Machine Learning vào Malware Analysis có thể coi là một bước tiến khá lớn trong lĩnh vực này. Mặc dù đối với ngành an ninh mạng ở Việt Nam thì điều này vẫn chưa phổ biến cho lắm, nhưng trên thế giới thì người ta đã làm từ rất lâu rồi. Do đó mình mong là bài viết này sẽ phần nào giúp các bạn hiểu sâu hơn về Machine Learning cũng như Malware Analysis.
Bản nhạc bạn đang nghe có lẽ cũng đã dừng phát rồi, ly cà phê trên tay bạn có lẽ cũng đã nguội, nên mình xin phép dừng ở đây nhé. Hẹn gặp lại các bạn trong các bài viết lần sau.