ML-based IDPS for SDN network
Sau một thời gian nghiên cứu về mạng SDN (Software Defined Networking) cũng như các ứng dụng của chúng, hôm nay mình xin chia sẻ một mô hình sử dụng Machine learning để thiết kế một hệ thống IDPS cho mạng kiểu mới này.
Software Defined Networking
Trước hết, mạng SDN là gì? Khái niệm này xuất hiện vào khoảng giữa năm 2011, theo đó, kiến trúc này cho phép người quản trị viên cấu hình mạng một cách tập trung bằng các ứng dụng hoặc phần mềm, giúp họ có khả năng quản lý và giám sát mạng một cách dễ dàng, làm cho nó giống như điện toán đám mây hơn là quản lý mạng truyền thống.
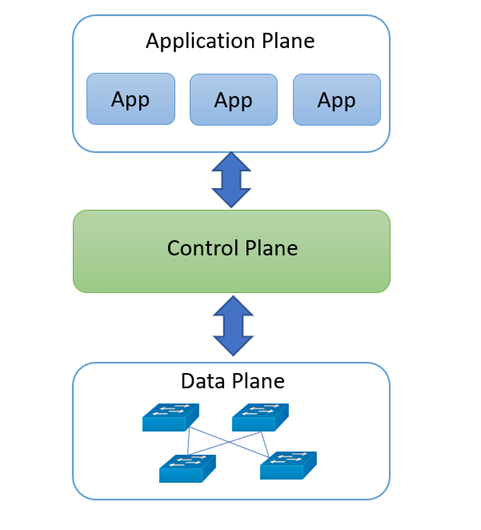
Kiến trúc SDN sẽ bao gồm 3 thành phần chính, đó là
Data plane – Mặt phẳng dữ liệu; Control plane – Mặt phẳng điều khiển; và
Application plane – Mặt phẳng ứng dụng.
- Mặt phẳng dữ liệu bao gồm các thiết bị mạng như Router, Switch, Host, …
- Mặt phẳng điều khiển sẽ chịu trách nhiệm điều khiển hoạt động của các thiết bị mạng ở mặt phẳng dữ liệu thông qua các thuật toán định tuyến, phân luồng, cân bằng tải, …
- Mặt phẳng ứng dụng sẽ bao gồm các ứng dụng được thiết kế với mục đích tương tác với mặt phẳng điều khiển nhằm giúp người quản trị viên dễ dàng quản lý và cấu hình mạng.
Nói một cách dễ hiểu, trong
kiến trúc mạng truyền thống, bản thân các Switch, Hub hoặc Router sẽ chịu trách nhiệm định tuyến, truyền gói tin, DHCP, … Trong khi đó,
kiến trúc SDN sẽ tập trung hóa các chức năng này vào một thực thể phần mềm duy nhất, từ đó người quản trị viên có thể dễ dàng quản lý hoạt động của mạng cũng như cập nhật các cấu hình một cách dễ dàng mà không cần phải thực hiện điều đó trên từng thiết bị mạng.
Bạn có thể tưởng tượng rằng trong trường hợp mà bạn phải đi cấu hình mạng cho một doanh nghiệp, bạn phải cấu hình rất nhiều thứ như IP, DHCP, NAT, … và bạn phải thực hiện điều đó trên tất cả các thiết bị mạng, từ những Switch cho tới các Hub và Router, thậm chí bạn còn phải cấu hình trên từng máy tính trong một số trường hợp. Tuy nhiên, với kiến trúc SDN, bạn chỉ cần làm điều đó trên một máy tính duy nhất. Ngoài ra, với SDN, bạn còn có thể dễ dàng quản lý các luồng dữ liệu của mạng hoặc cân bằng tải giữa các thiết bị, điều mà kiến trúc mạng truyền thống rất khó có thể thực hiện
Tuy nhiên, bất cứ thứ gì cũng đều có những ưu điểm và hạn chế của chúng, mạng SDN cũng không phải là trường hợp ngoại lệ. Vậy kiến trúc này có những hạn chế như thế nào?
- Thứ nhất, việc tập trung hóa chức năng điều khiển của mạng sẽ làm cho kiến trúc của mạng khó mở rộng hơn, khi mà số lượng các thiết bị mạng ngày càng tăng thì khả năng quản lý của máy Controller sẽ ngày càng giảm.
- Thứ hai, đây là một kiến trúc khá là mới, hiện nay vẫn chưa có một tiêu chuẩn cụ thể nào về các giao thức cũng như các phần mềm được sử dụng để quản lý mạng
- Thứ ba, đây là hạn chế quan trọng nhất và cũng là thứ mà mình muốn đề cập tới nhiều nhất trong bài viết này, đó là về khả năng bảo mật. Với một kiến trúc mà tất cả các chức năng điều khiển của mạng đều tập trung vào một máy Controller, thì đây sẽ là mục tiêu lý tưởng cho các Hacker tấn công vào. Cũng dễ hiểu thôi, khi mà máy Controller bị tấn công thành công thì toàn bộ mạng sẽ bị sập theo.
Vậy, giải pháp là gì? Có rất nhiều giải pháp có thể sử dụng, chẳng hạn như Firewall, Anti-Virus, Anti-Malware, IDPS, … Hãy cũng mình phân tích một chút nhé.
Lựa chọn giải pháp
Điều đầu tiên mà bạn có thể thấy ở kiến trúc SDN này, đó là nó khá giống với kiến trúc điện toán đám mây (Cloud computing) hoặc mạng vạn vật (Internet of Things). Đặc điểm đầu tiên của những kiến trúc này đó là lượng dữ liệu trao đổi giữa các thiết bị vô cùng lớn, và cũng rất đa dạng, do đó việc xây dựng một hệ thống tường lửa (Firewall) không phải là ý kiến hay. Lý do là vì bạn sẽ phải thiết kế những bộ luật vô cùng phức tạp và chặt chẽ, cùng với đó là bạn phải luôn cập nhật bộ luật của mình để có thể đáp ứng được với những kiểu tấn công mới.
Tiếp theo, Anti-Virus và Anti-Malware, đây đều là những giải pháp rất tốt để bảo mật mạng SDN. Tuy nhiên, những giải pháp này chỉ có khả năng phát hiện mã độc có trong hệ thống, chứ không thể ngăn chặn được các dạng tấn công mạng như DDoS, Scanning, Spoofing, … Ngày nay các dạng tấn công mạng ngày càng phổ biến và đa dạng, do đó chúng ta cần một giải pháp toàn diện hơn nữa so với giải pháp này.
Và do đó, ứng cử viên hàng đầu của chúng ta, đó là IDPS.
IDPS là gì?
IDPS là sự kết hợp của IDS (Intrusion Detection System – Hệ thống phát hiện xâm nhập) và IPS (Intrusion Prevention System – Hệ thống ngăn chặn xâm nhập). IDS có thể là những thiết bị hoặc phần mềm có nhiệm vụ giám sát traffic mạng, phát hiện các hành vi đáng ngờ và cảnh báo cho quản trị viên hệ thống. IPS sẽ là các thiết bị hoặc phần mềm chịu trách nhiệm ngăn chặn các hành vi đó bằng nhiều cách khác nhau, chẳng hạn như chặn IP nguồn, drop traffic, …
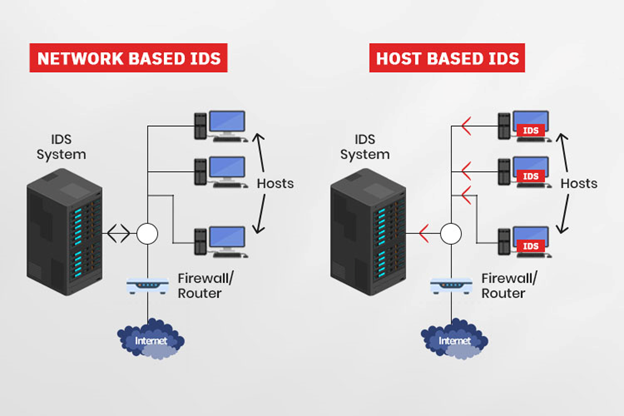
IDPS có thể chia làm 2 loại chính: Network-based IDPS (NIDPS), có khả năng phát hiện và ngăn chặn xâm nhập trong toàn bộ mạng; và Host-based IDPS (HIDPS), có khả năng phát hiện và ngăn chặn xâm nhập trên một máy trạm. Trong bài viết này, mình sẽ sử dụng NIDPS.
Thông thường, một hệ thống IDPS sẽ phát hiện tấn công bằng các luật hoặc các thiết lập ngưỡng. Theo hướng thiết lập luật, khi một gói tin trong mạng có một trường thông tin nào đấy khớp với luật thì sẽ bị ngăn chặn; Còn theo hướng thiết lập ngưỡng, khi một lượng dữ liệu được truyền tới trong một khoảng thời gian mà vượt quá so với ngưỡng quy định thì các kết nối đó sẽ bị ngăn chặn. Tuy nhiên, nhược điểm của các hướng tiếp cận này cũng giống như Firewall, đó là chúng chỉ có thể ngăn chặn được các kiểu tấn công đã biết, do đó chúng ta cần phải thiết kế những bộ luật vô cùng chặt chẽ và phải luôn cập nhật bộ luật của mình để đáp ứng được với sự đa dạng của các kiểu tấn công.
Do đó, trong bài viết này, mình sẽ sử dụng một phương pháp tiếp cận mới đối với hệ thống IDPS, đó là sử dụng Machine Learning. Một hệ thống IDPS sử dụng Machine Learning được hứa hẹn sẽ là một giải pháp tốt hơn so với các hướng tiếp cận thông thường. Lý do là vì chúng ta sẽ không cần phải thiết lập những bộ luật phức tạp, và với Machine Learning chúng ta có thể nhận biết được nhiều kiểu tấn công hơn so với khi thiết lập luật. Nhược điểm duy nhất của hướng tiếp cận này đó là chúng cần một lượng tài nguyên tương đối lớn để có thể Train các mô hình Machine Learning, tuy nhiên trong thời kì công nghệ thông tin phát triển như hiện nay thì mình nghĩ đây không phải là vấn đề quá lớn.
Câu hỏi tiếp theo là: Làm thế nào để thiết kế một hệ thống IDPS bằng cách sử dụng Machine Learning? Dành cho những bạn chưa biết Machine Learning là gì, trước khi bắt đầu, hãy cũng mình tản mạn một chút về lĩnh vực này nhé, những bạn đã biết thì có thể bỏ qua phần dưới.
Machine Learning là gì?
Các bạn sẽ cảm thấy cụm từ “Trí tuệ nhân tạo” rất quen thuộc phải không? Thật vậy, trong thời đại mà công nghệ thông tin phát triển cực kì mạnh mẽ như ngày nay thì trí tuệ nhân tạo cũng đang len lỏi vào từng ngõ ngách trong đời sống của chúng ta. Xe tự hành của Tesla, trợ lý ảo Google hoặc Siri, gợi ý quảng cáo của Youtube hoặc Facebook, nhận diện khuôn mặt, … đều là những ứng dụng rất phổ biến của Trí tuệ nhân tạo.
Vậy còn Machine Learning (ML) là gì? Theo định nghĩa của Wikipedia thì Machine Learning là một lĩnh vực nhỏ của Trí tuệ nhân tạo, nó có khả năng tự học hỏi dựa trên dữ liệu đưa vào mà không cần phải được lập trình cụ thể.
ML có rất nhiều loại, phổ biến nhất có lẽ là
Supervised Learning (Học có giám sát). Trong kiểu học này, thuật toán sẽ đưa ra dự đoán (output) cho một dữ liệu mới (input) dựa vào các cặp dữ liệu (input, output) đã biết trước.
Supervised Learning lại có thể chia ra thành 2 loại chính là Regression (Hồi quy) và Classification (Phân lớp).
Regression là những bài toán mà đầu ra của dữ liệu không phải là một loại hay một lớp nhất định, trong khi đó Classification thì ngược lại. Lấy ví dụ, những bài toán dự đoán giá của sản phẩm, hoặc tính toán thời gian xây dựng, hoặc dự đoán sản lượng, … sẽ là bài toán Regression, vì các thông tin này đều là những thông tin ước chừng chứ không phải là một loại nhất định. Trong khi đó, những bài toán như phân loại sản phẩm, dự đoán bệnh cho bệnh nhân, phân loại hồ sơ, … sẽ là bài toán Classification, vì những thông tin trên đều đã được phân loại rõ ràng.
Bài toán Basic nhất trong các bài toán Regression mà bạn có thể tìm thấy ở bất cứ đâu trên Google, đó là bài toán dự đoán giá nhà. Đầu vào (input) của dữ liệu sẽ bao gồm thông tin của nhiều ngôi nhà khác nhau, kí hiệu là Xi. Mỗi ngôi nhà sẽ có nhiều thuộc tính, ví dụ như diện tích, vị trí, phương hướng, … kí hiệu là xi0, xi1, … Output của dữ liệu sẽ là giá của ngôi nhà đó, kí hiệu là Yi. Mục đích của thuật toán là dựa trên bộ dữ liệu có sẵn trên để đưa ra dự đoán giá của một ngôi nhà mới mà đã biết các thuộc tính của ngôi nhà đó. Bài toán này sử dụng thuật toán Linear Regression, là thuật toán gần như cơ bản nhất cho những ai theo đuổi ngành ML.
Tiếp theo sẽ là những bài toán Classification. Có rất nhiều thuật toán cho loại này, ví dụ như KNN, SVM, Decision Tree, Random Forest, … Chi tiết các thuật toán này các bạn có thể tìm thấy rất nhiều trên Google, và mình sẽ không nhắc lại nữa
Tuy nhiên, bộ dữ liệu mẫu không phải lúc nào cũng đầy đủ và chuẩn form. Dữ liệu sẽ luôn luôn có mất mát, và thậm chí chúng còn không có đầu ra (output). Nhân tiện đang tìm hiểu về mạng SDN, các bạn sẽ thấy rằng dữ liệu mạng luôn luôn có rất nhiều, tuy nhiên chúng không hề thuộc bất kì một loại nào cả. Chúng đơn giản chỉ là những dữ liệu trao đổi giữa các máy tính khác nhau. Vậy chúng ta áp dụng ML vào như thế nào? Đó là lý do mà các thuật toán
Unsupervised Learning (Học không giám sát) ra đời. Mục đích của những thuật toán này là phân cụm các dữ liệu không nhãn, nhằm dự đoán một dữ liệu mới sẽ thuộc vào cụm nào, hoặc phát hiện ra những dữ liệu bất thường mà không thuộc một cụm nào cả.
Các thuật toán phổ biến thuộc loại
Unsupervised Learning có thể kể đến như K-Mean, LSH, …
Để cho dễ hiểu thì mình sẽ lấy một ví dụ về loại thuật toán này. Bây giờ bạn cần xây dựng một trang web xem phim, và bạn cần chức năng gợi ý phim yêu thích cho người dùng. Bạn sẽ có 2 bộ dữ liệu chính là thông tin về User, bao gồm nhiều thuộc tính như tên, tuổi, nơi sinh, sở thích, … và bộ dữ liệu còn lại là về những bộ Film, bao gồm nhiều thuộc tính như tên phim, đạo diễn, thể loại, diễn viên, … Bạn đã có dữ liệu đánh giá của một số User về một số bộ Film, và nhiệm vụ của bạn là gợi ý Film cho những User chưa xem nó sao cho khả năng họ thích là cao nhất. Để làm được điều này, bạn sẽ cần
Unsupervised Learning để phân cụm cả về User lẫn Film. Bạn có thể hiểu nôm na như này, nếu User1 và User2 cùng cụm với nhau, User1 thích phim Film1 thì bạn có thể đưa ra gợi ý cho User2 về bộ phim này, vì khả năng cao là họ sẽ thích nó. Điều tương tự với việc phân cụm Film.
Ngoài ra thì còn một số dạng thuật toán ML khác, ví dụ như
Semi-Supervised Learning (Học bán giám sát), áp dụng cho những bộ dữ liệu vừa có nhãn và vừa không; hoặc
Reinforcement Learning (Học Củng Cố), áp dụng chủ yếu trong các trò chơi như cờ vua, cờ vây, …
ML-Based IDPS
Quay trở lại chủ đề chính, chúng ta sẽ sử dụng ML để thiết kế hệ thống IDPS như thế nào?
Như các bạn đã biết thì dữ liệu mạng sẽ có hai dạng chính:
Uncorrelated data và
Serial data, dịch nôm na ra là “dữ liệu rời rạc” và “dữ liệu theo chuỗi”, tuy nhiên mình nghĩ là nên để nguyên tên tiếng anh của chúng thì hơn.
Uncorrelated data là những dữ liệu không liên quan tới nhau, có thể là những gói tin HTTP, DNS, SSL, … Và được gửi đi một cách rời rạc. Trong khi đó,
Serial data là một chuỗi dữ liệu liên quan tới nhau, hoặc chí ít thì chúng liền mạch với nhau theo một quy luật ổn định nào đó. Và với mỗi loại dữ liệu trên thì chúng ta sẽ lại có những hướng tiếp cận khác nhau.
Đối với
Uncorrelated data, chúng ta cũng sẽ có hai hướng tiếp cận để xây dựng một hệ thống ML-Based IDPS, đó là Classification (phân lớp) hoặc Clustering (phân cụm).
Đối với việc sử dụng Classification trong
Uncorrelated data, chúng ta cần một bộ dữ liệu đã được phân loại chính xác dữ liệu của các kiểu tấn công. Có khá nhiều bộ dữ liệu phục vụ cho việc này, ví dụ như KDD99, hoặc UNSW-NB15. Các bạn cũng có thể sử dụng các bộ dữ liệu mới hơn, được thu dưới dạng những file pcap trong link sau:
https://www.netresec.com/?page=pcapfiles
Tuy nhiên, hầu như dữ liệu mạng đều không có nhãn, và khi đó chúng ta sẽ cần tới Clustering. Việc áp dụng Clustering trong
Uncorrelated data cũng khá giống với việc áp dụng Classification, chỉ khác ở chỗ là lựa chọn thuật toán phân cụm thay vì thuật toán phân lớp mà thôi.
Đối với
Serial data, chúng ta chỉ có thể sử dụng các thuật toán phân cụm để phát hiện những dữ liệu bất thường. Tuy nhiên, kết quả thực nghiệm cho thấy việc áp dụng các thuật toán Clustering vào những dạng dữ liệu như này thực sự không hiệu quả cho lắm, do đó chúng ta cần những thuật toán học sâu (Deep Learning) như LSTM, AutoEncoder, GAN, .... Chi tiết những thuật toán này cũng có rất nhiều trên Google, tuy nhiên hiện nay mình mới chỉ đang nghiên cứu theo hướng này chứ chưa thực hiện, nên mình sẽ trình bày về phương pháp này trong một bài viết gần nhất.
Tiếp theo, làm thế nào để áp dụng ML vào thiết kế hệ thống IDPS cho mạng SDN. Mình xin mô tả lại quy trình hệ thống mà mình đã thiết kế như sau:
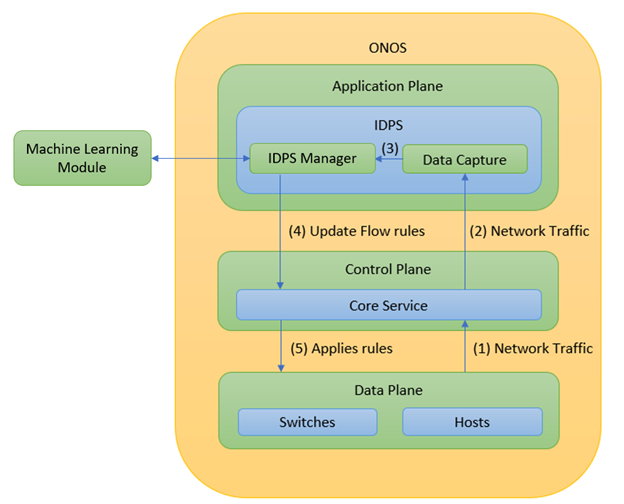
Quy trình hoạt động của hệ thống có thể được tóm tắt như sau:
- Các dữ liệu mạng sẽ được Capture bởi thành phần Core của Control Plane. Dữ liệu mạng trong ONOS sẽ được truyền đi dưới dạng các Flow (khác với các dạng Packet thông thường). Dạng dữ liệu mạng này có ưu điểm là số lượng các gói tin sẽ ít hơn nhiều so với dạng Packet thông thường, do đó sẽ giúp cho hệ thống có thể hoạt động tốt mà không bị quá tải.
- Các dữ liệu được Capture này sẽ được truyền tới ứng dụng IDPS của chúng ta ở trên Application Plane.
- Các dữ liệu này sẽ được truyền cho thành phần IDPS Manager của ứng dụng IDPS để chịu trách nhiệm phân tích gói tin và đưa ra dự đoán là gói tin bình thường hay gói tin tấn công. Thành phần IDPS Manager này sẽ gọi tới Module chạy Machine Learning ở bên ngoài để chạy thuật toán và xử lý dữ liệu (như đã giải thích ở trên, Machine Learning sử dụng Python để lập trình, trong khi đó ONOS lại sử dụng Java, nên mình phải thiết kế Module Machine Learning ở ngoài).
- Từ kết quả của thuật toán, đưa ra các cập nhật cho Flow Rules nếu chưa có luật ngăn chặn kiểu tấn công đó.
- Áp dụng Flow Rules vào Data Plane.
Kịch bản và kết quả thực nghiệm
Tiếp theo mình xin mô tả lại kịch bản hoạt động hệ thống của mình và kết quả thực nghiệm.
Nền tảng SDN mà mình sử dụng là ONOS, các bạn có thể tìm thấy trong link sau:
https://wiki.onosproject.org/
Các bạn có thể triển khai phiên bản dành cho Administrator hoặc phiên bản Developer. Ở đây mình sẽ sử dụng phiên bản Developer.
Đầu tiên, cần phải đảm bảo máy tính có cài các công cụ cần thiết:
$ sudo apt-get install python3 git curl unzip Bzip2 bazel
Sau khi đảm bảo đã cài hết tất cả các công cụ trên, ta sẽ clone project của onos từ trên github:
$ git clone https://gerrit.onosproject.org/onos
Tiếp theo, chạy các lệnh:
$ cd onos
$ bazel build onos
$ bazel run onos-local -- clean debug
Sau đó truy cập vào UI trên giao diện web theo link:
http://localhost:8181/onos/ui, các bạn sẽ thấy như sau:

User và Password mặc định là “onos” và “rocks”.
Nếu không muốn tương tác với SDN qua giao diện, các bạn có thể tương tác qua dòng lệnh bằng cách chạy các lệnh sau:
$ cd onos/tools/test/bin
$ ./onos localhost
Các bạn sẽ thấy giao diện dòng lệnh của ONOS như sau:
Để thêm các thiết bị mạng thực tế vào ONOS, các bạn cần thêm thông tin của chúng vào file config. Sau đó, import file cấu hình đó vào ONOS như sau:
$ cd onos/tools/package/runtime/bin
$ onos-netcfg localhost [đường dẫn đến file json]
Cấu trúc của file config có dạng như sau:

Một Switch ở thực tế, khi import vào ONOS sẽ trở thành một “Device”, một máy trạm sẽ trở thành một “Host”, một liên kết giữa 2 thiết bị bất kì sẽ trở thành “Link”. Một Link sẽ kết nối với một thiết bị mạng qua “Port”. Các thông tin cần khai báo của một thiết bị bao gồm ID (có thể tự chọn, miễn là chưa có thiết bị nào sử dụng), IP address, MAC, type (ví dụ L2 Switch hay L3 Switch), …
Tuy nhiên, nếu các bạn không có một mô hình mạng ở thực tế, các bạn có thể sử dụng một giải pháp đơn giản hơn đó là triển khai một mô hình mạng ảo. Các thông số của mô hình mạng này vẫn y hệt các thông số ở thực tế. Mạng ảo mà mình sử dụng là Mininet:
http://mininet.org/
Để cho các bạn dễ tiếp cận thì mình sẽ đi theo hướng triển khai một mô hình mạng ảo. Các bạn cài đặt mininet theo lệnh sau:
$ sudo apt-get install mininet
Sau đó, các bạn code một file python để định nghĩa mô hình mạng của bạn. Các bạn có thể tham khảo code dưới đây, mình đặt tên nó là “testnet.py”:

Mô hình mạng trên gồm 3 switch, mỗi switch gồm 1 host. Nếu các bạn muốn một mô hình mạng có nhiều thiết bị hơn thì các bạn hãy thêm các Switch, Host và Link vào. Sau đó, các bạn chạy lệnh sau để triển khai mininet lên ONOS:
$ sudo mn --controller=remote,ip=[ip của bạn] --custom testnet.py --topo tp
Khi triển khai thành công, màn hình ONOS sẽ cập nhật bản đồ mạng như sau:
Vậy ONOS quản lý hoạt động mạng như thế nào? Các bạn ấn vào dấu 3 gạch ở góc trái trên cùng màn hình để mở Menu, vào phần Application, các bạn sẽ thấy có rất nhiều các ứng dụng dùng quản lý hoạt động mạng. Các ứng dụng có thể là LLDP, OpenFlow, Access Control, …
Do đó, để triển khai được một hệ thống IDPS trên ONOS thì ta cần phải lập trình một ứng dụng và chạy trên mặt phẳng ứng dụng như trong hình trên. Để làm được điều đó, bạn phải biết lập trình Java. Project này sử dụng Maven hoặc Bazel để build, và nó cần nhận “org.onosproject” làm project cha.
Chẳng hạn như trong bài viết này, mình sẽ sử dụng Maven để build ứng dụng của mình. Mình tạo một project Maven, sau đó thêm vào file “pom.xml” như sau:

Khi bạn tạo một project như trên, ứng dụng của bạn sẽ có ID là “org.onosproject.[tên ứng dụng]”, chẳng hạn nếu tên ứng dụng của bạn là “idps” thì ứng dụng đó sẽ có ID là “org.onosproject.idps”. Một ứng dụng chạy trên ONOS sẽ có 2 Component cơ bản là @Activate và @Deactivate, tương ứng với trạng thái lúc bạn chạy ứng dụng và lúc bạn tắt ứng dụng. Các bạn tạo một class mới, tạo 2 hàm tương ứng với 2 component trên, sau đó đăng kí ID của ứng dụng này với Controller của ONOS trong @Activate như sau:

Trong đó các deviceService, linkService, hostService là các thư viện của ONOS giúp mình có thể tương tác với các dịch vụ quản trị Device (switch), Link và Host. Các Listener như deviceListener, linkListener và hostListener là các trình lắng nghe để giúp mình có thể chụp được các Traffic mạng (việc này tương ứng với bước thứ (2) trong quy trình hoạt động mà mình đã mô tả trong phần trước). Mình sẽ lập trình cho các trình lắng nghe trên để mỗi khi có một Traffic mới được tạo thì ứng dụng của mình sẽ gọi tới Module Machine Learning bên ngoài của mình. Dòng code “coreService.registerApplication…” dùng để đăng kí ứng dụng của mình với Controller.
Về phần code trình lắng nghe, các bạn có thể tham khảo code của mình như sau:

Code này sẽ lắng nghe Flow ở trên switch, mỗi khi có một Flow được thêm, xóa hoặc thay đổi thì mình sẽ gọi hàm tương tác tới module Machine Learning của mình. Hàm sendNotify() mình lập trình để gọi tới API của module ML.
Tiếp theo, mình cần một thứ gì đó để có thể tương tác ngược lại từ module ML của mình tới ứng dụng trong ONOS. Cách đơn giản nhất để thực hiện điều này là mình sẽ thiết lập một dịch vụ API trên ứng dụng của mình, sau đó mình sẽ gọi API đó từ module ML.
ONOS sử dụng nền tảng Swagger để triển khai dịch vụ API, và họ cũng hỗ trợ bạn tạo một API riêng cho ứng dụng của bạn. Để làm được điều này, các bạn chỉ cần tạo 1 class kế thừa lớp BaseResource như sau:
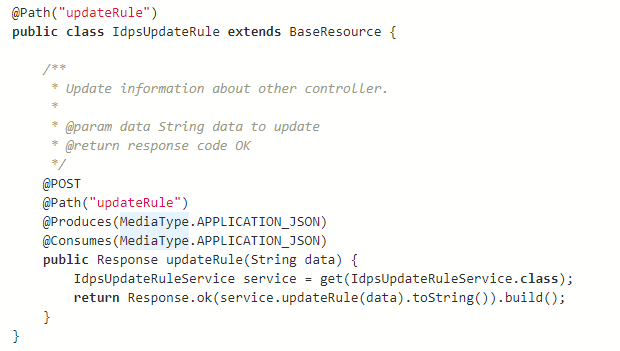
Trong hình trên mình đã tạo một API để cập nhật luật cho Flow. Hành động này cũng chính là việc các bạn ngăn chặn các kiểu tấn công mới khi phát hiện ra chúng. Bạn có thể tìm thấy cấu trúc của một Flow rule trong link sau:
https://wiki.onosproject.org/display/ONOS/Flow+Rules#:~:text=Flow%20Rule%20Criteria,-JSON%20Format&text=During%20a%20flow%20POST%20request,work%20in%20a%20POST%20request
Sau khi các bạn lập trình xong ứng dụng, để triển khai một ứng dụng của mình lên nền tảng ONOS, các bạn chạy lệnh sau:
$ cd [link tới project của bạn]
$ maven clean compile install
$ ./onos-app localhost install! [link tới file .jar trong project của bạn]
Sau khi đã chạy được ứng dụng của mình trên ONOS, việc tiếp theo là xây dựng mô hình Machine Learning. Việc đầu tiên là lựa chọn bộ dữ liệu. Về dữ liệu trong mạng (cả về dữ liệu bình thường lẫn dữ liệu tấn công), có rất nhiều các bộ dữ liệu phổ biến như KDD99, UNSW-NB15, CSE-CIC-IDS2018, … Tuy nhiên, để thực tế hơn thì mình sẽ tự thực hiện thu và gán nhãn một bộ dữ liệu riêng. Lý do là vì các bộ dữ liệu trên đều quá lớn, hoặc quá cũ (đối với bộ KDD99). Trong thời gian nghiên cứu đề tài này thì mình đang tham gia lab ở trường, nên mình có khá là đủ điều kiện để có thể thực hiện một bộ dữ liệu như thế.
Hệ thống lab mà mình thực hiện có tất cả 12 máy, trong đó có 2 máy sẽ phụ trách việc tấn công và 9 máy còn lại sẽ thực hiện các hành động thông thường. Mình sẽ thu 7 bộ dữ liệu riêng biệt, trong đó 1 bộ dữ liệu là hoạt động thông thường và 6 bộ dữ liệu còn lại là 6 kiểu tấn công khác nhau. Mục đích mình thu như vậy là để dễ dàng cho việc gán nhãn. 6 kiểu tấn công lần lượt là:
- DOS UDP
- DOS TCP Synflood
- Ping of Death
- Reset TCP
- Scan nmap
- TCP port scan
Trong bộ dữ liệu hoạt động bình thường, các máy sẽ thực hiện nhiều hành động khác nhau như duyệt web, xem youtube, lướt facebook, chơi game, … Mình sử dụng Wireshark để bắt gói tin, sau đó sử dụng Tshark để convert từ file pcap sang csv.
Trong bộ dữ liệu tấn công, để cho dữ liệu chính xác nhất có thể thì mình sẽ không thực hiện bất cứ hành động nào khác ngoài việc tấn công. Tất nhiên sẽ có rất nhiều các dịch vụ chạy ngầm hoạt động trong quá trình đó, nên mình đã cố gắng tắt tất cả các dịch vụ không cần thiết cho quá trình này. Mình sử dụng 3 công cụ chính để triển khai các dạng tấn công là Metasploit, Nmap và Ettercap.
Tất cả 7 bộ dữ liệu trên mình sẽ trộn với nhau một cách ngẫu nhiên, sau đó tiền xử lý.
Về việc tiền xử lý dữ liệu, mình sẽ sử dụng 41 features giống hệt với bộ dữ liệu KDD99. Chi tiết các Features là gì thì các bạn có thể tham khảo ở đây:
http://kdd.ics.uci.edu/databases/kddcup99/kddcup.names
Nhãn của bộ dữ liệu sẽ gồm 7 lớp, bao gồm 1 lớp thông thường và 6 lớp tấn công.
Trong thực tế triển khai thì có một số dữ liệu bị trùng lặp, và trong quá trình tiền xử lý thì mình cũng đã loại bỏ chúng. Thống kê về số lượng dữ liệu và số lượng trùng lặp như sau:
| Lớp |
Số lượng |
Lượng dữ liệu trùng lặp |
Số lượng sau khi loại bỏ trùng lặp |
Tỉ lệ dữ liệu sau khi loại bỏ trùng lặp |
| Normal |
5280 |
4% |
5072 |
34% |
| DOS UDP |
2600 |
8.7% |
2376 |
16% |
| DOS TCP Synflood |
2456 |
2.2% |
2400 |
16% |
| Ping of Death |
1392 |
0% |
1392 |
9% |
| Reset TCP |
1428 |
3.8% |
1368 |
9% |
| Scan nmap |
1228 |
0% |
1228 |
8% |
| TCP port scan |
1040 |
0% |
1040 |
7% |
| Tổng |
15424 |
|
14876 |
|
Mình đã xây dựng mô hình và thử nghiệm trên 5 mô hình Machine Learning phổ biến, lần lượt là SVM, Random Forest, Naïve Bayes, Decision Tree và KNN. Mình phân chia bộ dữ liệu theo tỉ lệ (train:test) = (7:3). Chi tiết độ hiệu quả của các thuật toán như sau:
| Thuật toán |
Accuracy |
Cross Entropy |
MAE |
MSE |
Time (second) |
| SVM |
0.931 |
2.86e-12 |
0.168 |
0.459 |
8.15 |
| Random Forest |
0.963 |
2.87e-12 |
0.113 |
0.34 |
5.42 |
| Naïve Bayes |
0.91 |
2.8e-12 |
0.207 |
0.528 |
4.82 |
| Decision Tree |
0.962 |
2.85e-12 |
0.114 |
0.338 |
2.64 |
| K-NN |
0.955 |
2.82e-12 |
0.126 |
0.377 |
3.12 |
Qua bảng trên, các bạn có thể thấy 2 thuật toán Random Forest và Decision Tree cho ra độ chính xác tốt nhất, cùng với đó Decision Tree cho thời gian training nhanh nhất. Do đó mình quyết định sẽ chạy theo cả 2 loại thuật toán và đưa ra đánh giá.
Dưới đây là bảng Confusion Matrix của 2 thuật toán trên (bảng này là kết quả của việc phân loại tập dữ liệu Test), trong đó các hàng là dữ liệu chính xác (True label), còn các cột là dữ liệu dự đoán của thuật toán (Predict label):
| Decision Tree |
DOS UDP |
DOS TCP Synflood |
Normal |
Ping of Death |
Reset TCP |
Scan nmap |
TCP port scan |
| DOS UDP |
672 |
|
|
34 |
|
|
|
| DOS TCP Synflood |
|
716 |
|
|
|
|
|
| Normal |
|
|
1486 |
|
|
|
|
| Ping of Death |
|
69 |
|
357 |
|
|
|
| Reset TCP |
|
|
|
|
409 |
|
3 |
| Scan nmap |
|
|
|
|
|
371 |
|
| TCP port scan |
|
|
|
|
|
|
331 |
| Random Forest |
DOS UDP |
DOS TCP Synflood |
Normal |
Ping of Death |
Reset TCP |
Scan nmap |
TCP port scan |
| DOS UDP |
666 |
|
|
40 |
|
|
|
| DOS TCP Synflood |
|
716 |
|
|
|
|
|
| Normal |
|
|
1486 |
|
|
|
|
| Ping of Death |
67 |
|
|
359 |
|
|
|
| Reset TCP |
|
|
|
|
412 |
|
|
| Scan nmap |
|
|
|
|
|
371 |
|
| TCP port scan |
|
|
|
|
|
|
331 |
Qua các bảng trên thì ta có thể thấy kiểu tấn công “Ping of Death” có vẻ dễ bị nhận nhầm, trong khi các kiểu tấn công còn lại thì phân biệt khá tốt. Code của các module ML thì mình sẽ không đề cập ở đây nữa, vì nó có khá nhiều trên mạng.
Tiếp theo, như đã nói ở trên thì mình cần mở một dịch vụ API ở phía module ML của mình để ứng dụng trong ONOS có thể gọi tới. Để tiện luôn cho việc lập trình ML bằng python thì mình sẽ sử dụng một nền tảng API cũng lập trình cho python, đó là Flask.
Mình sẽ lập trình một API đơn giản như sau:
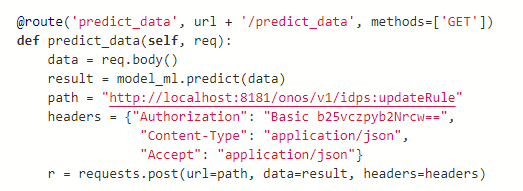
API trên có chức năng nhận data là FLow thu được từ SDN, sử dụng ML để dự đoán và trả về luật cho Flow. Luật đó sẽ được gọi tới API updateRule mà mình đã viết ở bên ứng dụng trong ONOS.
Một số nhận xét
- Mạng SDN sẽ có cái nhìn toàn cục hơn so với mạng thông thường, khi mà máy Controller sẽ quản lý và điều khiển một cách tập trung hầu như toàn bộ các hoạt động của mạng. Điều này dẫn tới việc áp dụng IDPS trong mạng SDN sẽ hiệu quả và dễ triển khai hơn nhiều so với mạng thông thường, tuy nhiên sẽ lại có thêm một số vấn đề mới phát sinh, chẳng hạn như nếu máy Controller bị tấn công thành công thì IDPS đó sẽ không còn đáng tin cậy nữa, hoặc vấn đề về việc khó mở rộng hệ thống mạng.
- Thay vì sử dụng các Packet thông thường thì mạng SDN sử dụng các Flow để truyền dữ liệu (trong một đơn vị thời gian thì số lượng Flow sẽ ít hơn rất nhiều so với số lượng Packet), do đó việc áp dụng Machine Learning trong SDN sẽ không phải lo về vấn đề quá tải dữ liệu giống như trong mạng IoT
Kết luận
Trên đây mình đã giới thiệu cho các bạn một mô hình sử dụng Machine Learning để thiết kế một hệ thống IDPS cho mạng SDN. Trong bài viết sau mình sẽ chia sẻ mô hình sử dụng Deep Learning để phát hiện dữ liệu bất thường trong mạng.
Cảm ơn các bạn đã theo dõi.
Tài liệu tham khảo
[1] Kreutz, D., Ramos, F. M. V., Esteves Verissimo, P., Esteve Rothenberg, C., Azodolmolky, S., & Uhlig, S. (2015). “Software-Defined Networking: A Comprehensive Survey”, Proceedings of the IEEE, 103(1), 14–76.
[2] Aziz, N. A., Mantoro, T., Khairudin, M. A., & Murshid, A. F. b A. (2018). “Software Defined Networking (SDN) and its Security Issues”, 2018 International Conference on Computing, Engineering, and Design (ICCED).
[3] Jason Brownlee, “Deep Learning with python”, 2019
[4] Jason Brownlee, “Machine Learning mastery with python”, 2016
[5]
https://wiki.onosproject.org/display/ONOS/ONOS
[6]
https://github.com/mininet/mininet/wiki/Documentation