Ở phần trước, chúng ta đang dừng lại ở việc tìm ra tiến chỉnh xử lý chính của công đoạn Extractor, chung quy lại thì phần core của nó vẫn được xử lý bằng java, với main class com.semmle.extractor.java.JavaExtractor.
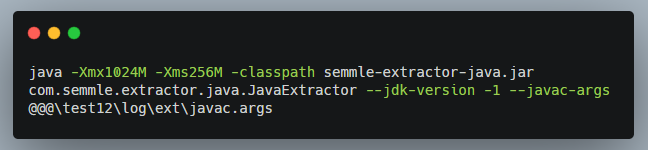
Tiến hành debug tại bước này để tìm hiểu cách hoạt động của nó,
Để dựng lại môi trường, cần phải copy các file yêu cầu trong folder: “/log/ext/*“ (có thể tìm thấy trong folder database sau khi chạy lệnh create xong):
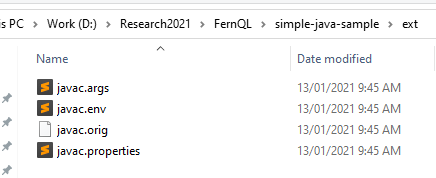
Cũng cần lưu ý dựng lại các biến môi trường, các biến này có prefix “CODEQL_*”, “SEMMLE_*” và “ODASA_*”
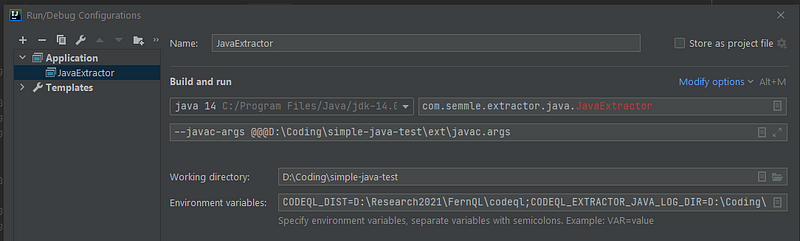
Sau khi xong xuôi, Debug config trong IntellIJ sẽ có dạng như sau:
#DEBUG
Một lưu ý trước khi debug, cần phải xóa các folder log, src, trap trong folder database, vì Extractor sẽ kiểm tra tồn tại và bỏ qua nó.
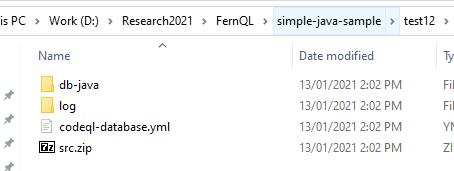
Chạy thử Extractor với config vừa set, tại folder database có các file được tạo mới như sau:
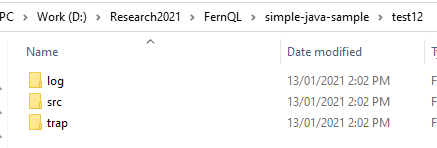
Các bạn cũng có thể thấy rõ điểm khác biệt so với database cuối cùng được tạo, tại phần này đã xuất hiện thêm folder “trap”.
Và các file “trap” như trong document có mô tả được đặt trong folder này.
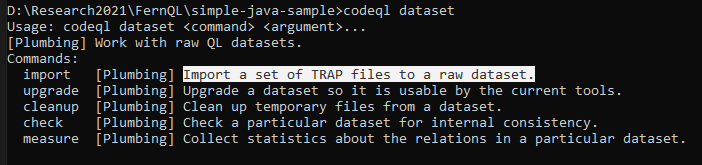
- Với quá trình build db thông thường, các file trap này sẽ được chuyển hóa thành dataset và xóa luôn ngay khi xử lý xong. Có thể thực hiện việc chuyển hóa dataset bằng câu lệnh “codeql dataset”:
Folder trap có cấu trúc như sau:
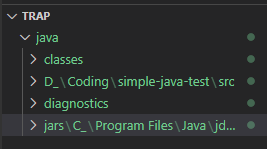
- Folder classes bao gồm các file trap chứa các thông tin về các member của 1 class, ví dụ như “field, methods, modifier …” :
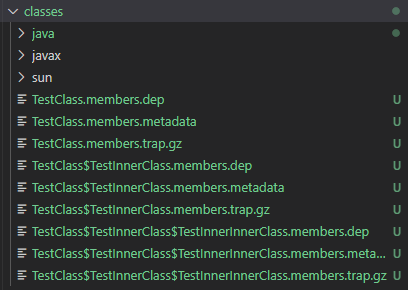
//Cấu trúc của trap file sẽ được mô tả ngay phía dưới
- Folder bắt đầu với tên có dạng như path của mã nguồn (ở đây là D_\Coding\…), bao gồm các file trap chứa thông tin về các thành phần của 1 file mã nguồn, ví dụ như “expression, method call, …”
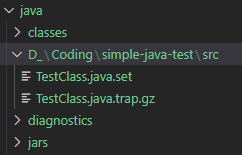
Các trap file này đều đã được nén vào file .gz, hoàn toàn có thể giải nén và sử dụng 1 text editor nào đó để đọc nội dung của trap file,
#Trap file
Nội dung của 1 trap file có dạng như sau:
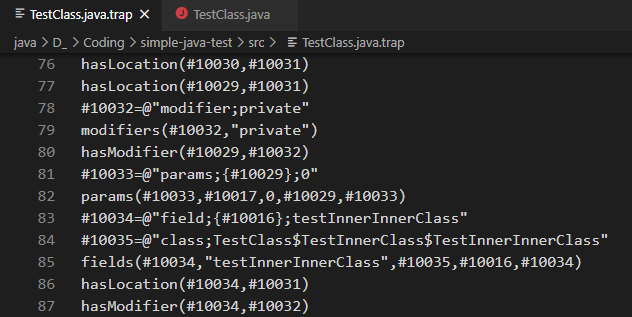
Hoặc xinh đẹp hơn là như vầy:
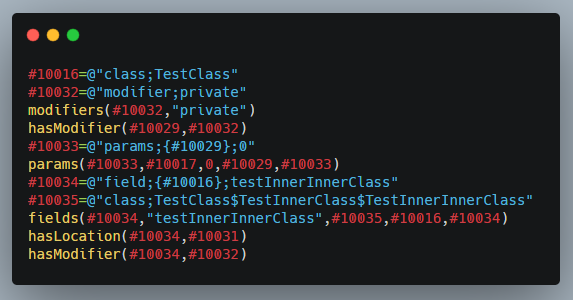
Các khai báo dạng:
#10016=@”class;TestClass”
Được gọi là khai báo nhãn, thường bắt đầu với ký tự “#”, về ngữ nghĩa, có thể coi nhãn như 1 id trong các hệ quản trị cơ sở dữ liệu.
Mỗi trap file có các khai báo nhãn độc lập, không chung với các nhãn được khai báo của trap file khác!
Xét thêm 1 ví dụ sau:
#10034=@”field;{#10016};testInnerInnerClass”
Đây là một khai báo nhãn của field, có link tới nhãn #10016, nhãn này là nhãn đại diện cho class TestClass.
Tiếp sau đó, là dòng khai báo:
fields(#10034, ”testInnerInnerClass”, #10035, #10016, #10034)
Với các nhãn tương ứng được truyền vào: #10034 (field), #10035 (class inner), #10016 (TestClass), #10034 (field).
Thông tin được khai báo theo thứ tự như vậy, đương nhiên là phải tuân theo 1 nguyên tắc nào đó rồi!
Ở đây, các file trap được xây dựng dựa trên 1 cấu trúc scheme định sẵn, với mỗi loại ngôn ngữ sẽ có các scheme riêng biệt. Với java, có thể tìm thấy scheme tại folder “/codeql/java/”:
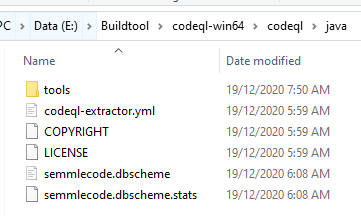
Tương ứng với khai báo “fields” phía trên, trong file dbscheme có định nghĩa khai báo này như sau:
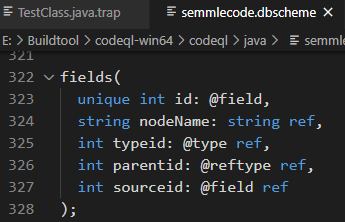
Sắp xếp theo đúng thứ tự của dòng khai báo fields được như sau:
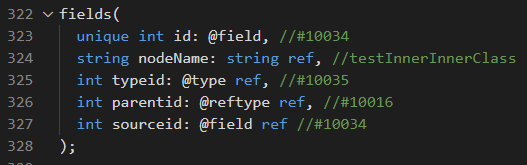
Việc khai báo của các đối tượng khác cũng tương tự, hoạt động theo cùng logic như vậy, ví dụ như hasModifier():
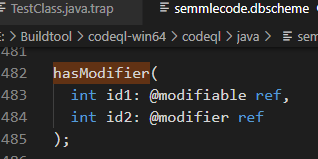
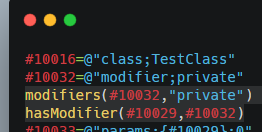
Thực ra trong phần này cũng có được đề cập một số private document, được hé mở bởi 1 ông dev tốt bụng, nhưng để giữ lời, mình chưa thể viết rõ hơn trong bài viết nay, mong bạn đọc thông cảm, nguyên văn:

Và nói thêm 1 chút, kiến trúc DB này khá là dị vì nó không phải như dạng SQL ta thường biết,
DB Engine của Semmle được xây dựng dựa trên Datalog, một ngôn ngữ lập trình khai báo logic, thường được sử dụng làm ngôn ngữ truy vấn cho cơ sở dữ liệu suy diễn.
Trong Datalog, dữ liệu không được gọi là record, mà được gọi là fact, mình đã tìm đủ mọi cách nhưng không tìm thấy từ nào diễn tả đúng và đủ nghĩa trong tiếng Việt, mặc dù nó có nghĩa nào đó tương đồng với bản ghi trong SQL!
Một ví dụ nhỏ về Datalog, có schema như sau:
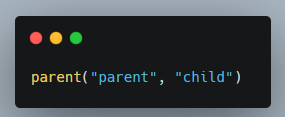
Tương ứng với schema trên, mỗi khai báo sau sẽ tương ứng với một “fact” của schema đó:
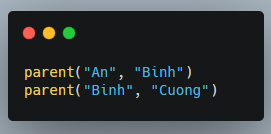
//Lại thêm vấn đề về Datalog, bạn đọc có thể đọc thêm tài liệu về Datalog tại đây: http://bluehawk.monmouth.edu/~rscherl/Classes/KF/ull.pdf
Điều đó giải thích lý do tại sao các trap file và file schema lại có dạng như vậy, vì đơn giản: Semmle sử dụng Datalog, không phải SQL!
Và hệ quả là cách viết câu query cũng không giống như cách viết query trên SQL! (nó khác nhiều lắm đó, chỉ là tại thời điểm viết mình méo nhớ gì nữa nên ko thể đưa ra ví dụ trực quan cho các bạn (ಥ_ಥ), sorry !)
#DEBUG
Quay trở lại với việc debug, lần này là debug thật nè!
Breakpoint dừng tại JavaExtractor#367:
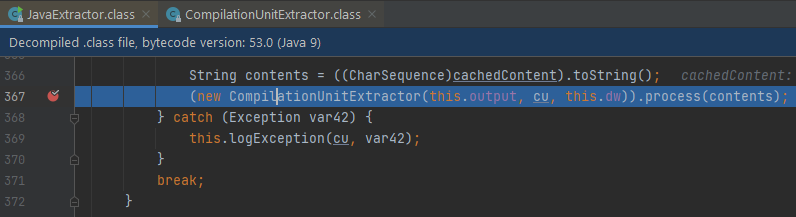
Đối số được truyền vào chính là nội dung của file mã nguồn đang được gọi từ trình biên dịch “javac”.
Giống với tên, this.output là object quyết định vị trí output của các trap file:

Tại CompilationUnitExtractor.process()#47, trap writer cho file mã nguồn hiện tại được set:
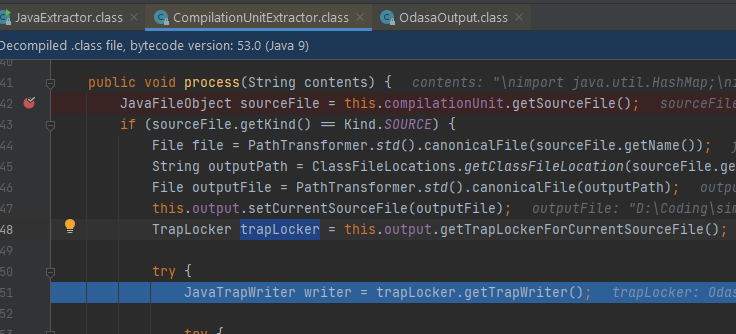
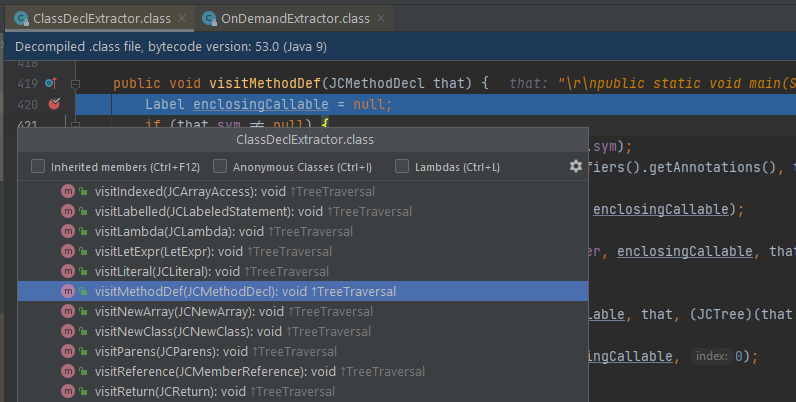
Tiếp tục đi vào ClassDeclExtractor.process() để extract các thông tin của từng class trong file mã nguồn hiện tại:

ClassDeclExtractor override các method “visit” của javac_extend.com.sun.tools.javac.tree.JCTree.Visitor để lấy thông tin (cũng giống như cách hoạt động của MethodVisitor trong ow2 asm (https://asm.ow2.io/asm4-guide.pdf).
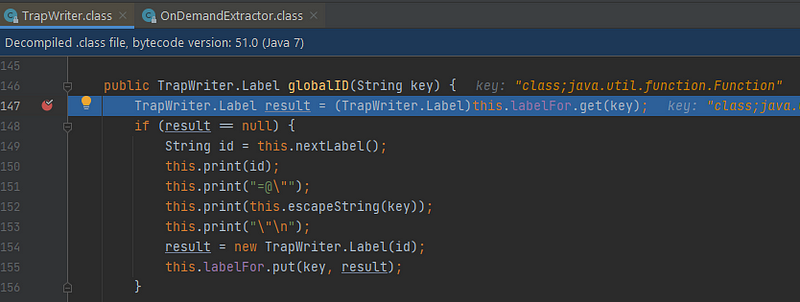
Các label của trap file được quyết định mỗi khi gọi tới các method “get***Key()”. Từ các method “get***Key()” này sẽ gọi tới TrapWriter.globalID(key) để kiểm tra xem label đã được tạo hay chưa, nếu có thì lấy, không thì tạo mới 1 label và push vào cache:
Bạn đọc có thể làm tương tự với các trường hợp khai báo field, method, var … mình xin phép chỉ hướng dẫn tới đây
.
.
Như vậy qua 2 phần của bài viết, mình đã nói sơ qua về cách thức hoạt động cũng như cách để tìm hiểu cách Semmle Core hoạt động.
Để thực thi được các câu truy vấn, cần phải đề cập tới DB Engine
Tuy nhiên do phạm vi nghiên cứu đã quá lan man, nên mình chưa xem về cách hoạt động của DB.
Hy vọng một ngày đẹp trời nào đó sẽ có người tiếp tục topic này!
Cảm ơn các bạn đã theo dõi!
Ref:
- https://help.semmle.com/33t4mskxr3-discontinued/semmle-cli/semmle-core-cli-1.24.pdf
- http://bluehawk.monmouth.edu/~rscherl/Classes/KF/ull.pdf
- https://courses.cs.washington.edu/courses/csep544/17au/lectures/lec3-ra-datalog.pdf
- https://userpages.uni-koblenz.de/~laemmel/gttse/2007/pdfs/52350085.pdf
- https://help.semmle.com/home/Resources/pdfs/scam07.pdf
- ….
__Jang of VNPT ISC__