Mình được biết đến Semmle/CodeQL từ một người anh trong làng bảo mật, theo như quảng cáo của ông anh này thì đây sẽ là “tương lai của việc tìm lỗ hổng bảo mật”.
Vào khoảng thời gian đó, mình đang trong trạng thái betak khi nghiên cứu về 1 công cụ tự động tìm kiếm lỗ hổng — GadgetInspector.
Không lâu sau đó, vào tháng 9–2019, Github mua lại Semmle và đổi tên thành CodeQL như hiện tại. (https://techcrunch.com/2019/09/18/github-acquires-code-analysis-tool-semmle/).
Cũng vừa đúng lúc vào mùa đồ án tốt nghiệp, mình đề xuất luôn đề tài nghiên cứu về CodeQL và được accept luôn. Chỉ tiếc là kết quả đồ án ko đc như mong đợi lắm 😶.
.
.
CodeQL — Semmle — Odasa, … đem đến luồng gió mới cho lĩnh vực code review, thay vì phải trace các call graph, CodeQL chuyển thể tất cả các dữ liệu về source code thành một dạng cơ sở dữ liệu, và việc tìm kiếm lỗ hổng bây giờ sẽ thực hiện bằng cách truy vấn trên đám Db này.
(Theo thông tin biết được từ một người bạn, có 1 enterprise product khác tương tự, cũng hoạt động bằng cách chuyển tất cả mã nguồn sang dạng Normalized Syntax Tree và phân tích trên đó. Tuy nhiên do tính thương mại của sản phẩm này nên mình không đề cập quá sâu tại bài viết này).
Giải pháp này đã được chứng nhận và thương mại hóa với sản phẩm LGTM, dĩ nhiên là bộ core của nó cũng là closed-source luôn.
Điều này gây ra khá nhiều khó khăn trong quá trình tìm hiểu về kiến trúc cũng như cách hoạt động của Semmle,
Trong suốt thời gian 1 năm trở lại đây, mình đã rất nhiều lần mặt dày hỏi nhà phát triển về vấn đề public source code của bộ Semmle Core Java, nhưng đều nhận được câu trả lời là “chưa biết”.
Sở dĩ mình mặt dày vậy là vì một phần của bộ core dành cho C#, python, golang đều đã được public, nhưng Java thì không ¯\_(ツ)_/¯.
Thôi thì đành nghiên cứu = cách Reverse Engineering vậy, dù sao bộ core này cũng được xây dựng bằng Java nên việc dịch ngược không khó lắm.
- Lưu ý: Bài viết được dựa trên phương diện khách quan, do đó có thể có nhiều sai sót so với tài liệu chính.
À quên, xin đính chính lại mục đích của bài viết này là về cách hoạt động của CodeQL chứ không phải cách sử dụng CodeQL nhé! Có lẽ sự tò mò đã ngấm vào máu của mình từ khi còn bé, mình thích nghiên cứu về cách hoạt động của 1 thứ gì đó hơn là về cách sử dụng thứ đó.
Tại thời điểm 2019, khi mình bắt đầu nghiên cứu về Semmle thì có 1 số ít tài liệu về cách hoạt động của bộ core, đa số là lấy từ trang chủ help.semmle.com.
Vào thời điểm viết bài thì số tài liệu liên quan tới cách hoạt động của Semmle Core đã không cánh mà bay, được thay thế bằng 1 số tài liệu khác. Bạn đọc có thể tham khảo mô tả về cách hoạt động của bộ core tại đây: https://web.archive.org/web/20190918221214/https://help.semmle.com/wiki/display/SD/What+does+Semmle+Core+do (link web cũ đã bị thay thế) hoặc (https://help.semmle.com/33t4mskxr3-discontinued/semmle-cli/semmle-core-cli-1.24.pdf #page 7).
Ngoài ra trong quá trình làm đồ án mình cũng sưu tầm được gần chục paper về Datalog cũng như paper về .QL đời đầu, được publish bởi chính nhà phát triển, bạn đọc có nhu cầu nghiên cứu về vấn đề này có thể liên hệ mình để lấy các tài liệu này!
#Các thành phần chính của Semmle
Về cơ bản, có thể nhận thấy Semmle bao gồm các thành phần chính như sau:
- Extractor: đóng vai trò thu thập & phân tích mã nguồn để tạo thành một bộ cơ sở dữ liệu hoàn chỉnh về các statement, call graph, variable …
- DB Engine: xử lý các câu truy vấn về bộ mã nguồn được gửi lên, kiến trúc được dựa trên Datalog
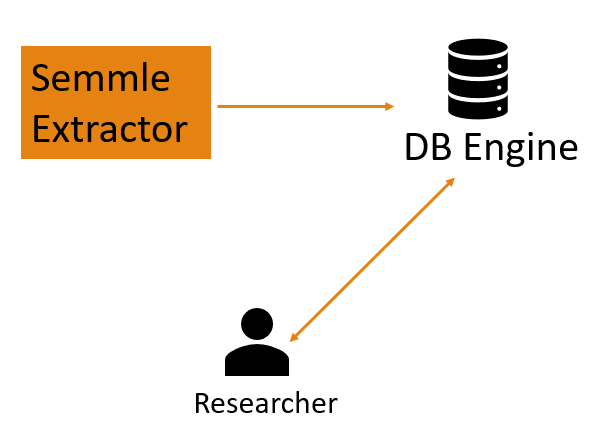
Trên thực tế còn có một số thành phần khác, bài viết này chỉ tập trung vào nghiên cứu về 2 thành phần này là chủ yếu. Bên cạnh đó, bài viết này chỉ là cái nhìn phiến diện của tác giả về cách hoạt động của chúng, mình không dám chắc 100% đây là cách hoạt động chính thống của Semmle!
#Extractor
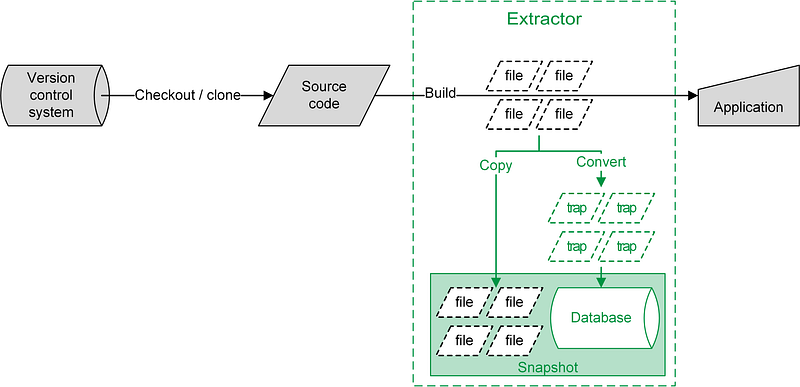
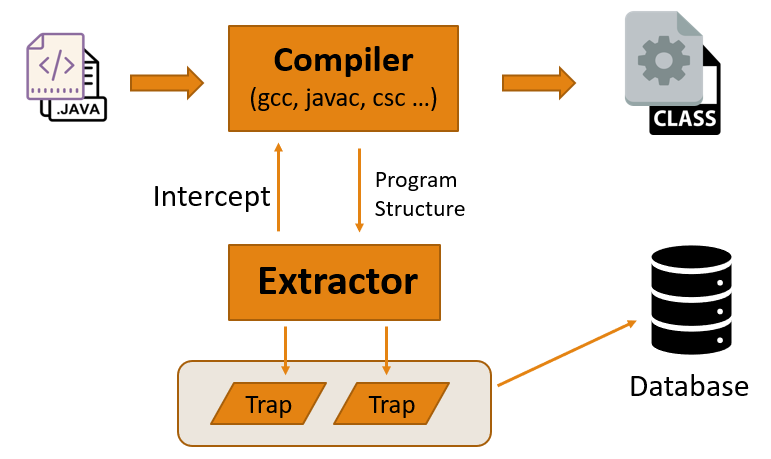
Theo mô tả từ official document, với các ngôn ngữ biên dịch, ví dụ như Java, quá trình tạo cơ sở dữ liệu sẽ thực hiện bằng cách “intercept” và lắng nghe các lệnh gọi tới trình biên dịch:

Việc intercept này diễn ra hoàn toàn trong suốt, không cần phải tác động gì thêm vào các build script của chương trình (ví dụ như: pom.xml, build.gradle …). Bằng việc intercept này, “Extractor” sẽ nhận được các thông tin của bộ mã nguồn, các call graph, variable …, từ chính trình biên dịch. Sau đó các dữ liệu này sẽ được chuyển thể sang một dạng biểu diễn quan hệ, gọi là “trap” file (cách biểu diễn về file này sẽ được cung cấp thêm phía dưới). Quá trình trên có thể mô phỏng bằng sơ đồ sau:
Với mỗi file mã nguồn (ví dụ: Foo.java) sẽ được chuyển sang 1 file trap tương ứng (Foo.trap).
File trap này có thể coi như là 1 file SQL trong các hệ quản trị cơ sở dữ liệu thông thường, dùng để lưu thông tin và có thể import vào CSDL sau đó.
Và cũng giống như file SQL, file trap cũng có dạng database schema riêng, mỗi file đều phải tuân theo schema này.

Một ví dụ về biểu diễn thành phần của chương trình sau khi được chuyển thể sang trap file:
Đoạn code mẫu đơn giản như sau:
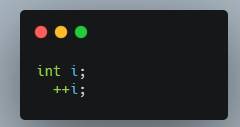
Và sau khi được chuyển sang trap file:
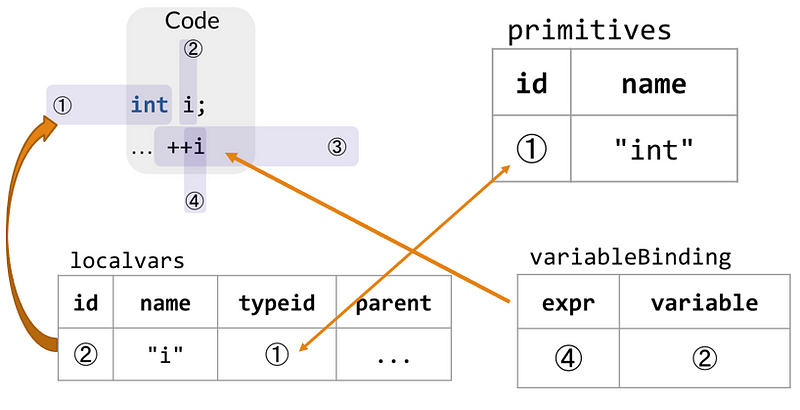
Trong đó có kiểu “int”, được lưu tại table “primitives”, có id là “1”,
Biến local tên là “i”, được lưu tại table “localvars”, có id là “2”. (không phải 1, lý do sẽ được trình bày sau). Biến local này có “typeid” là “1”, tương ứng với kiểu “int” tại table “primitives”.
Tiếp theo là table “variableBinding”, có expr: “4”, variable: “2”, tương ứng với biểu thức “4” có tác động tới biến “2”.
Phía trên là những gì mình tổng hợp được từ các nguồn tài liệu nói về cách hoạt động của Semmle Core,
Tuy nhiên, đó mới chỉ là phần lý thuyết, mà với mình thì nó chưa đủ thuyết phục để có thể nói là “hiểu” được.
#Let’s get your hand dirty!
Để thực nghiệm về quá trình hoạt động của Extractor, mình tạo 1 project đơn giản và cho build db với project này, sau đó quan sát các tiến trình được sinh ra từ đó (sample được upload tại đây: https://github.com/testanull/simple-java-sample).
Command được dùng để build như sau:
codeql database create test12 --language=java --command=".\build.cmd"
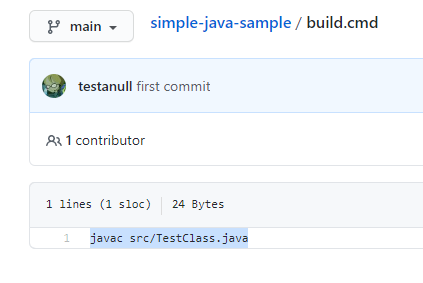
Content của file “build.cmd”:
Các tiến trình được sinh ra sau khi chạy lệnh build DB:
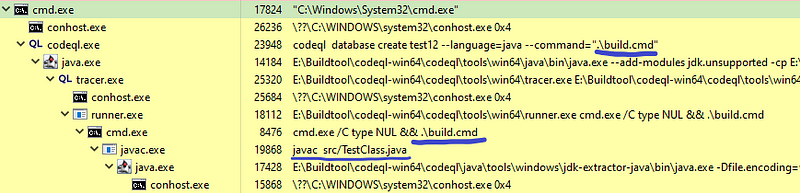
Sau khi chạy command build “.\build.cmd”, chương trình gọi tới trình biên dịch “javac”, và 1 tiến trình con “java” mới được sinh ra từ đó. Đây chính là công đoạn intercept trình biên dịch để lấy các thông tin của mã nguồn.
Tiến trình con sinh ra từ “javac” là tiến trình chính xử lý việc lấy thông tin của mã nguồn và tạo thành trap file:
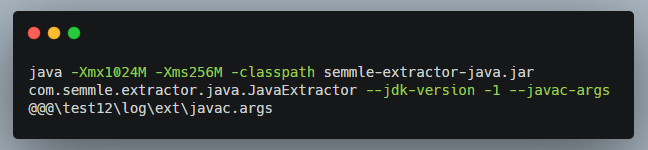
Sau bao nhiêu bước loằn ngoằn, cuối cùng vẫn kết thúc với “java”,
Ở phase này, file jar library được sử dụng là “semmle-extractor-java.jar” với main class: com.semmle.extractor.java.JavaExtractor
Hiện tại chúng ta sẽ tạm dừng tại đây, hẹn gặp lại trong phần 2.
.
.
*** to be continued ***