Với sự phát triển của dữ liệu lớn (big data), sự cải thiện đáng kể trong khả năng tính toán, và các đổi mới liên tục trong các phương pháp Học máy (Machine Learning), các công nghệ Trí tuệ nhân tạo (AI) như nhận diện hình ảnh, nhận diện giọng nói, và xử lý ngôn ngữ tự nhiên đang trở nên ngày càng phổ biến. Ngoài ra, AI cũng đóng vai trò đáng kể trong bảo mật máy tính: một mặt, AI có thể được sử dụng để xây dựng các hệ thống phòng thủ như phát hiện mã độc và tấn công mạng; mặt khác, AI có thể được khai thác để thực thi các cuộc tấn công hiệu quả hơn. Trong một số trường hợp, việc bảo mật các hệ thống AI là vấn đề sống còn. Vì vậy, việc xây dựng các hệ thống AI mạnh mẽ, miễn nhiễm với sự can thiệp từ bên ngoài là điều cần thiết. AI có thể có lợi cho an toàn bảo mật hoặc ngược lại.
 Mục tiêu chính của bài báo này là tìm hiểu về bảo mật trong AI, về mặt bảo vệ tính toàn vẹn và bí mật của các mô hình và dữ liệu của AI, và từ đó ngăn chặn kẻ tấn công thay đổi kết quả dự đoán hoặc đánh cắp dữ liệu.
Mục tiêu chính của bài báo này là tìm hiểu về bảo mật trong AI, về mặt bảo vệ tính toàn vẹn và bí mật của các mô hình và dữ liệu của AI, và từ đó ngăn chặn kẻ tấn công thay đổi kết quả dự đoán hoặc đánh cắp dữ liệu.
 Các rủi ro bảo mật AI không chỉ tồn tại trong phân tích lý thuyết mà cả trong các sản phẩm AI đã triển khai. Ví dụ, kẻ tấn công có thể tạo ra các file có khả năng vượt qua các công cụ phát hiện dựa trên AI hoặc chèn các đoạn nhiễu vào hệ thống điều khiển giọng nói nhà thông minh để thực thi các ứng dụng độc hại. Kẻ tấn công cũng có thể giả mạo dữ liệu trả về từ thiết bị đầu cuối hoặc các cuộc trò chuyện với chatbot nhằm gây ra sai sót trong việc dự đoán của hệ thống AI. Thậm chí có thể dán các nhãn dán lên trên biển báo giao thông hoặc phương tiện giao thông khiến cho suy đoán của các phương tiện tự động không chính xác.
Để giảm thiểu các rủi ro này, hệ thống AI phải vượt qua năm thách thức sau:
Các rủi ro bảo mật AI không chỉ tồn tại trong phân tích lý thuyết mà cả trong các sản phẩm AI đã triển khai. Ví dụ, kẻ tấn công có thể tạo ra các file có khả năng vượt qua các công cụ phát hiện dựa trên AI hoặc chèn các đoạn nhiễu vào hệ thống điều khiển giọng nói nhà thông minh để thực thi các ứng dụng độc hại. Kẻ tấn công cũng có thể giả mạo dữ liệu trả về từ thiết bị đầu cuối hoặc các cuộc trò chuyện với chatbot nhằm gây ra sai sót trong việc dự đoán của hệ thống AI. Thậm chí có thể dán các nhãn dán lên trên biển báo giao thông hoặc phương tiện giao thông khiến cho suy đoán của các phương tiện tự động không chính xác.
Để giảm thiểu các rủi ro này, hệ thống AI phải vượt qua năm thách thức sau:

 Khả năng phát hiện mô hình: Tương tự với việc phân tích các chương trình truyền thống trong công nghệ phần mềm, các mô hình AI cũng có thể được kiểm tra bằng một số kỹ thuật đối nghịch như phương pháp kiểm tra black-box và white-box. Tuy nhiên, các công cụ kiểm thử hiện nay thường dựa trên các tập dữ liệu mở có số lượng mẫu hạn chế và không thể bao phủ hết các trường hợp khi triển khai thực tế. Hơn nữa, các kỹ thuật huấn luyện đối nghịch có thể tiêu tốn rất nhiều tài nguyên trong quá trình huấn luyện lại. Do đó, trước khi các mô hình AI được triển khai trên bất kỳ hệ thống nào, cần phải thực hiện kiểm tra an toàn bảo mật trên các mô hình DNN. Ví dụ, một đơn vị tiền xử lý có thể được dùng để lọc các mẫu độc hại trước khi đưa vào huấn luyện, hoặc một đơn vị hậu xử lý có thể được thêm vào để kiểm tra tính toàn vẹn của đầu ra nhằm giảm kết quả dương tính sai. Với các phương pháp này, chúng ta có thể tăng cường sự mạnh mẽ của các hệ thống AI trước khi triển khai.
Khả năng xác thực mô hình: Các mô hình DNN hoạt động tốt hơn nhiều so với các kỹ thuật ML truyền thống (ví dụ, tỉ lệ phân loại chính xác cao hơn và tỉ lệ dương tính sai thấp hơn). Vì thế, các mô hình DNN thường được sử dụng rộng rãi trong các ứng dụng nhận diện giọng nói và hình ảnh. Tuy nhiên, cần phải cẩn trọng khi áp dụng mô hình AI vào các ứng dụng bảo mật và an toàn như lái xe tự động hoặc tự động chuẩn đoán y tế. Xác thực các mô hình DNN có thể đảm bảo an toàn ở một mức độ nào đó. Xác thực mô hình thường yêu cầu hạn chế ánh xạ giữa không gian đầu vào và không gian đầu ra để xác định xem đầu ra có nằm trong một phạm vi nhất định hay không. Tuy nhiên, vì các phương pháp xác thực và học dựa trên tối ưu hóa thống kê thường không thể bao phủ tất cả các phân phối dữ liệu, các trường hợp như các mẫu đối nghịch vẫn tồn tại. Trong tình huống này, việc thực hiện các biện pháp bảo vệ cụ thể trong triển khai thực tế là tương đối khó khăn. Việc phòng chỉ có thể được thực hiện khi nguyên tắc làm việc cơ bản của các mô hình DNN được hiểu đầy đủ.
Khả năng giải thích mô hình: Hiện tại, hầu hết các mô hình AI đều được xem như là các hệ thống black-box phức tạp, trong đó các quá trình ra quyết định, logic biện chứng và cơ sở suy đoán đều khó có thể diễn giải đầy đủ. Trong một số ứng dụng, như chơi cờ vua và dịch thuật, chúng ta cần hiểu tại sao máy lại đưa ra lựa chọn này hoặc lựa chọn kia nhằm đảm bảo sự tương tác tốt hơn giữa con người và máy móc. Tuy nhiên, việc không thể giải thích được hệ thống AI không đem lại vấn đề gì lớn cho các ứng dụng này. Một máy dịch thuật có thể tiếp tục là một hệ thống black-box phức tạp chừng nào nó vẫn đưa ra kết quả dịch tốt, không cần biết tại sao nó lại dịch như vậy. Mặc dù vậy, trong một số trường hợp, việc không giải thích được các hệ thống AI có thể đem lại rủi ro về mặt pháp lý hoặc kinh doanh. Ví dụ, trong các hệ thống phân tích bảo hiểm và cho vay, nếu hệ thống AI không đưa ra được cơ sở cho các kết quả phân tích đó, nó có thể bị cáo buộc là không công bằng; trong các hệ thống y tế, để thực hiện chính xác các tiến trình dựa trên kết quả phân tích của AI, cơ sở để đưa ra kết quả phân tích cũng cần được đưa ra. Chẳng hạn, chúng ta hy vọng rằng một hệ thống AI có thể phân tích xem liệu bệnh nhân có mắc bệnh ung thư hay không, và hệ thống cũng phải cho chúng ta biết tại sao nó lại đưa ra kết luận như vậy. Hơn nữa, việc thiết kế một mô hình an toàn mà không hiểu về nguyên lý hoạt động của nó gần như là bất khả thi. Tăng cường khả năng giải thích của các hệ thống AI giúp phân tích các lỗ hổng logic hoặc điểm mù dữ liệu của chúng, từ đó cải thiện tính bảo mật của các hệ thống AI.
Khả năng giải thích mô hình cũng có thể được thực hiện trong ba giai đoạn:
Khả năng phát hiện mô hình: Tương tự với việc phân tích các chương trình truyền thống trong công nghệ phần mềm, các mô hình AI cũng có thể được kiểm tra bằng một số kỹ thuật đối nghịch như phương pháp kiểm tra black-box và white-box. Tuy nhiên, các công cụ kiểm thử hiện nay thường dựa trên các tập dữ liệu mở có số lượng mẫu hạn chế và không thể bao phủ hết các trường hợp khi triển khai thực tế. Hơn nữa, các kỹ thuật huấn luyện đối nghịch có thể tiêu tốn rất nhiều tài nguyên trong quá trình huấn luyện lại. Do đó, trước khi các mô hình AI được triển khai trên bất kỳ hệ thống nào, cần phải thực hiện kiểm tra an toàn bảo mật trên các mô hình DNN. Ví dụ, một đơn vị tiền xử lý có thể được dùng để lọc các mẫu độc hại trước khi đưa vào huấn luyện, hoặc một đơn vị hậu xử lý có thể được thêm vào để kiểm tra tính toàn vẹn của đầu ra nhằm giảm kết quả dương tính sai. Với các phương pháp này, chúng ta có thể tăng cường sự mạnh mẽ của các hệ thống AI trước khi triển khai.
Khả năng xác thực mô hình: Các mô hình DNN hoạt động tốt hơn nhiều so với các kỹ thuật ML truyền thống (ví dụ, tỉ lệ phân loại chính xác cao hơn và tỉ lệ dương tính sai thấp hơn). Vì thế, các mô hình DNN thường được sử dụng rộng rãi trong các ứng dụng nhận diện giọng nói và hình ảnh. Tuy nhiên, cần phải cẩn trọng khi áp dụng mô hình AI vào các ứng dụng bảo mật và an toàn như lái xe tự động hoặc tự động chuẩn đoán y tế. Xác thực các mô hình DNN có thể đảm bảo an toàn ở một mức độ nào đó. Xác thực mô hình thường yêu cầu hạn chế ánh xạ giữa không gian đầu vào và không gian đầu ra để xác định xem đầu ra có nằm trong một phạm vi nhất định hay không. Tuy nhiên, vì các phương pháp xác thực và học dựa trên tối ưu hóa thống kê thường không thể bao phủ tất cả các phân phối dữ liệu, các trường hợp như các mẫu đối nghịch vẫn tồn tại. Trong tình huống này, việc thực hiện các biện pháp bảo vệ cụ thể trong triển khai thực tế là tương đối khó khăn. Việc phòng chỉ có thể được thực hiện khi nguyên tắc làm việc cơ bản của các mô hình DNN được hiểu đầy đủ.
Khả năng giải thích mô hình: Hiện tại, hầu hết các mô hình AI đều được xem như là các hệ thống black-box phức tạp, trong đó các quá trình ra quyết định, logic biện chứng và cơ sở suy đoán đều khó có thể diễn giải đầy đủ. Trong một số ứng dụng, như chơi cờ vua và dịch thuật, chúng ta cần hiểu tại sao máy lại đưa ra lựa chọn này hoặc lựa chọn kia nhằm đảm bảo sự tương tác tốt hơn giữa con người và máy móc. Tuy nhiên, việc không thể giải thích được hệ thống AI không đem lại vấn đề gì lớn cho các ứng dụng này. Một máy dịch thuật có thể tiếp tục là một hệ thống black-box phức tạp chừng nào nó vẫn đưa ra kết quả dịch tốt, không cần biết tại sao nó lại dịch như vậy. Mặc dù vậy, trong một số trường hợp, việc không giải thích được các hệ thống AI có thể đem lại rủi ro về mặt pháp lý hoặc kinh doanh. Ví dụ, trong các hệ thống phân tích bảo hiểm và cho vay, nếu hệ thống AI không đưa ra được cơ sở cho các kết quả phân tích đó, nó có thể bị cáo buộc là không công bằng; trong các hệ thống y tế, để thực hiện chính xác các tiến trình dựa trên kết quả phân tích của AI, cơ sở để đưa ra kết quả phân tích cũng cần được đưa ra. Chẳng hạn, chúng ta hy vọng rằng một hệ thống AI có thể phân tích xem liệu bệnh nhân có mắc bệnh ung thư hay không, và hệ thống cũng phải cho chúng ta biết tại sao nó lại đưa ra kết luận như vậy. Hơn nữa, việc thiết kế một mô hình an toàn mà không hiểu về nguyên lý hoạt động của nó gần như là bất khả thi. Tăng cường khả năng giải thích của các hệ thống AI giúp phân tích các lỗ hổng logic hoặc điểm mù dữ liệu của chúng, từ đó cải thiện tính bảo mật của các hệ thống AI.
Khả năng giải thích mô hình cũng có thể được thực hiện trong ba giai đoạn:
 Các ngành học AI khác nhau, bao gồm thị giác máy tính, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên, nhận thức và lý luận, lý thuyết trò chơi, vẫn đang trong giai đoạn phát triển ban đầu. Các hệ thống học sâu tận dụng dữ liệu lớn để phân tích thống kê đã mở rộng ranh giới của AI, nhưng chúng cũng thường được coi là "thiếu nhận thức thông thường", đó là trở ngại lớn nhất đối với nghiên cứu AI hiện tại. AI có thể vừa bị điều khiển bởi dữ liệu, vừa bị điều khiển bởi tri thức. Sự đột phá của AI thế hệ tiếp theo nằm ở dự đoán tri thức.
Dù bước tiếp theo là gì, sự phổ biến và nâng cao của AI đòi hỏi phải đảm bảo an toàn bảo mật. Tài liệu này tập trung vào hai loại tấn công và phòng thủ đối với AI. Đầu tiên, ảnh hưởng đến tính đúng đắn của các quyết định AI: Kẻ tấn công có thể phá hoại hoặc kiểm soát hệ thống AI hoặc cố ý thay đổi đầu vào để hệ thống đưa ra quyết định mà kẻ tấn công mong muốn. Thứ hai, những kẻ tấn công có thể đánh cắp dữ liệu bí mật được sử dụng để huấn luyện một hệ thống AI hoặc trích xuất mô hình AI. Với những vấn đề này, bảo mật hệ thống AI cần được xử lý từ ba khía cạnh: giảm thiểu tấn công AI, bảo mật mô hình AI và bảo mật kiến trúc AI. Ngoài ra, tính minh bạch và khả năng giải thích của AI là nền tảng của bảo mật. Một hệ thống AI không minh bạch hoặc không thể giải thích được không thể thực hiện các nhiệm vụ quan trọng liên quan đến an toàn cá nhân và an toàn cộng đồng.
AI cũng yêu cầu xem xét bảo mật trong các lĩnh vực, chẳng hạn như luật pháp và quy định, đạo đức và giám sát xã hội. Trong những năm tới, do AI sẽ được triển khai trong các lĩnh vực giao thông và chăm sóc y tế, công nghệ "phải được giới thiệu theo cách xây dựng niềm tin và sự hiểu biết, và tôn trọng quyền con người và quyền công dân". Ngoài ra, "các chính sách và quy trình nên giải quyết các ý nghĩa về đạo đức, quyền riêng tư và bảo mật". Để kết thúc vấn đề này, các cộng đồng quốc tế nên hợp tác để thúc đẩy AI phát triển theo hướng có lợi cho nhân loại.
Các ngành học AI khác nhau, bao gồm thị giác máy tính, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên, nhận thức và lý luận, lý thuyết trò chơi, vẫn đang trong giai đoạn phát triển ban đầu. Các hệ thống học sâu tận dụng dữ liệu lớn để phân tích thống kê đã mở rộng ranh giới của AI, nhưng chúng cũng thường được coi là "thiếu nhận thức thông thường", đó là trở ngại lớn nhất đối với nghiên cứu AI hiện tại. AI có thể vừa bị điều khiển bởi dữ liệu, vừa bị điều khiển bởi tri thức. Sự đột phá của AI thế hệ tiếp theo nằm ở dự đoán tri thức.
Dù bước tiếp theo là gì, sự phổ biến và nâng cao của AI đòi hỏi phải đảm bảo an toàn bảo mật. Tài liệu này tập trung vào hai loại tấn công và phòng thủ đối với AI. Đầu tiên, ảnh hưởng đến tính đúng đắn của các quyết định AI: Kẻ tấn công có thể phá hoại hoặc kiểm soát hệ thống AI hoặc cố ý thay đổi đầu vào để hệ thống đưa ra quyết định mà kẻ tấn công mong muốn. Thứ hai, những kẻ tấn công có thể đánh cắp dữ liệu bí mật được sử dụng để huấn luyện một hệ thống AI hoặc trích xuất mô hình AI. Với những vấn đề này, bảo mật hệ thống AI cần được xử lý từ ba khía cạnh: giảm thiểu tấn công AI, bảo mật mô hình AI và bảo mật kiến trúc AI. Ngoài ra, tính minh bạch và khả năng giải thích của AI là nền tảng của bảo mật. Một hệ thống AI không minh bạch hoặc không thể giải thích được không thể thực hiện các nhiệm vụ quan trọng liên quan đến an toàn cá nhân và an toàn cộng đồng.
AI cũng yêu cầu xem xét bảo mật trong các lĩnh vực, chẳng hạn như luật pháp và quy định, đạo đức và giám sát xã hội. Trong những năm tới, do AI sẽ được triển khai trong các lĩnh vực giao thông và chăm sóc y tế, công nghệ "phải được giới thiệu theo cách xây dựng niềm tin và sự hiểu biết, và tôn trọng quyền con người và quyền công dân". Ngoài ra, "các chính sách và quy trình nên giải quyết các ý nghĩa về đạo đức, quyền riêng tư và bảo mật". Để kết thúc vấn đề này, các cộng đồng quốc tế nên hợp tác để thúc đẩy AI phát triển theo hướng có lợi cho nhân loại.
Mục tiêu chính của bài báo này là tìm hiểu về bảo mật trong AI, về mặt bảo vệ tính toàn vẹn và bí mật của các mô hình và dữ liệu của AI, và từ đó ngăn chặn kẻ tấn công thay đổi kết quả dự đoán hoặc đánh cắp dữ liệu.
Các thách thức đối với bảo mật trong AI
Với sự phát triển của dữ liệu lớn, sự cải thiện đáng kể trong khả năng tính toán, và các đổi mới liên tục trong các phương pháp Học Máy (ML), các công nghệ Trí Tuệ Nhân Tạo (AI) như nhận diện hình ảnh, nhận diện giọng nói và xử lý ngôn ngữ tự nhiên đang trở nên ngày càng phổ biến. Ngày càng nhiều công ty đầu tư vào nghiên cứu AI và triển khai AI cho sản phẩm của họ. Theo Tầm nhìn công nghiệp toàn cầu của Huawei (GIV), đến năm 2025, toàn thế giới sẽ đạt được hơn 100 tỷ kết nối, chiếm tới 77% dân số; 85% ứng dụng doanh nghiệp sẽ được triển khai trên đám mây; khoảng 12% số gia đình sẽ sử dụng smart home robots, hình thành nên một thị trường hàng tỷ dollar. Sự phát triển và sử dụng rộng rãi các công nghệ AI đã báo trước sự xuất hiện của một thế giới thông minh. McCarthy, Minsky, Shannon và cộng sự, đã đề xuất khái niệm "Trí tuệ nhân tạo" vào năm 1956. 60 năm sau đó, công nghệ AI đã nở rộ, bắt đầu bằng việc AlphaGo, được phát triển bởi Google DeepMind, đã chiến thắng nhà vô địch thế giới bộ môn cờ vây. Ngày nay, với sự phát triển của chip và cảm biến, ý tưởng "Kích hoạt trí thông minh" đang ảnh hưởng đến một loạt các lĩnh vực, bao gồm:- Giao thông thông minh – chọn tuyến đường tốt nhất
- Chăm sóc sức khỏe thông minh – hiểu về sức khỏe của bạn
- Sản xuất thông minh – thích ứng với nhu cầu người dùng
- Khối lượng dữ liệu khổng lồ: với sự phát triển của Internet, dữ liệu gia tăng nhanh chóng dưới dạng giọng nói, video và văn bản. Dữ liệu này được cung cấp thành đầu vào cho các thuật toán ML, thúc đẩy sự phát triển nhanh chóng của các công nghệ AI.
- Hệ thống phần mềm và máy tính có thể mở rộng: Sự thành công của deep learning trong các năm gần đây chủ yếu được hỗ trợ bởi phần cứng chuyên dụng, như các cụm CPU, GPU, và các Tensor Processing Units (TPU), cũng như các nền tảng phần mềm.
- Khả năng tiếp cận rộng rãi của các công nghệ: Một lượng lớn các phần mềm mã nguồn mở hiện nay hỗ trợ xử lý dữ liệu và các công việc liên quan đến AI, giảm thời gian và chi phí phát triển. Ngoài ra, rất nhiều dịch vụ đám mây cung cấp tài nguyên lưu trữ và tính toán có sẵn cho các nhà phát triển.
Các rủi ro bảo mật AI không chỉ tồn tại trong phân tích lý thuyết mà cả trong các sản phẩm AI đã triển khai. Ví dụ, kẻ tấn công có thể tạo ra các file có khả năng vượt qua các công cụ phát hiện dựa trên AI hoặc chèn các đoạn nhiễu vào hệ thống điều khiển giọng nói nhà thông minh để thực thi các ứng dụng độc hại. Kẻ tấn công cũng có thể giả mạo dữ liệu trả về từ thiết bị đầu cuối hoặc các cuộc trò chuyện với chatbot nhằm gây ra sai sót trong việc dự đoán của hệ thống AI. Thậm chí có thể dán các nhãn dán lên trên biển báo giao thông hoặc phương tiện giao thông khiến cho suy đoán của các phương tiện tự động không chính xác.
Để giảm thiểu các rủi ro này, hệ thống AI phải vượt qua năm thách thức sau:
- Bảo mật phần cứng và phần mềm: Mã của ứng dụng, mô hình, nền tảng và chip có thể có lỗ hổng hoặc backdoors cho phép kẻ tấn công khai thác. Hơn nữa, kẻ tấn công có thể cài backdoors trong mô hình để thực thi các cuộc tấn công nâng cao hơn. Do thiếu sự hiểu biết sâu về mô hình AI, backdoors rất khó bị phát hiện.
- Toàn vẹn dữ liệu: Kẻ tấn công có thể chèn dữ liệu độc hại trong pha huấn luyện để làm ảnh hưởng đến khả năng suy luận của mô hình AI hoặc thêm các dữ liệu mẫu gây nhiễu trong quá trình dự đoán để thay đổi kết quả.
- Tính bí mật của mô hình: Các nhà cung cấp dịch vụ chỉ cung cấp dịch vụ truy vấn mà không tiết lộ mô hình được sử dụng. Tuy nhiên kẻ tấn công có thể tạo ra một mô hình nhân bản thông qua một số lượng truy vấn.
- Tính mạnh mẽ của mô hình: Các mẫu huấn luyện thường không bao phủ hết các trường hợp, dẫn đến việc mô hình có thể không cung cấp dự đoán chính xác về các mẫu đối nghịch.
- Quyền riêng tư dữ liệu: Trong các kịch bản mà người dùng cung cấp dữ liệu huấn luyện, kẻ tấn công có thể lặp lại các truy vấn tới một mô hình huấn luyện nhằm thu thập thông tin cá nhân của người dùng.
Các tấn công bảo mật AI điển hình
Không giống như các lỗ hổng bảo mật trong các hệ thống truyền thống, nguyên nhân sâu xa dẫn đến các điểm yếu trong các hệ thống ML nằm ở việc thiếu khả năng hiểu sâu về các hệ thống AI. Việc này dẫn đến nảy sinh các lỗ hổng có thể bị khai thác bằng các phương pháp học máy đối nghịch như né tránh, phá hoại và tấn công cửa sau. Các dạng tấn công này rất hiệu quả và có khả năng chuyển đổi mạnh mẽ giữa các mô hình ML khác nhau và do đó gây ra các mối đe dọa bảo mật nghiêm trọng tới các ứng dụng AI dựa trên Mạng nơ-ron sâu (Deep Neural Network - DNN). Ví dụ, kẻ tấn công có thể chèn dữ liệu độc hại trong quá trình huấn luyện, làm ảnh hưởng đến kết quả dự đoán của mô hình AI hoặc thêm các dữ liệu mẫu gây nhiễu trong quá trình dự đoán để thay thế kết quả chính xác. Kẻ tấn công cũng có thể cài backdoors trong mô hình và thực thi tấn công có chủ đích hoặc trích xuất các tham số và dữ liệu huấn luyện của mô hình từ kết quả truy vấn.Né tránh (Evasion)
Trong một cuộc tấn công né tránh, kẻ tấn công sẽ chỉnh sửa dữ liệu đầu vào khiến cho mô hình AI không thể nhận diện được đầu vào. Tấn công né tránh là các cuộc tấn công được nghiên cứu rộng rãi nhất trong giới nghiên cứu học thuật. Ba dạng cơ bản của kỹ thuật tấn công này là:- Mẫu đối nghịch: Nghiên cứu cho thấy các hệ thống deep learning có thể dễ dàng bị ảnh hưởng bởi các mẫu được chế tạo ra, được gọi là các mẫu đối nghịch. Chúng thường được tạo ra bằng cách thêm nhiễu vào các đầu vào hợp lệ. Các thay đổi này sẽ khó bị con người phát hiện, nhưng lại gây ảnh hưởng lớn đến đầu ra của mô hình học sâu. Szegedy và cộng sự, trong bài viết "Intriguing properties of neural networks" năm 2013, đã đề xuất các mẫu đối nghịch lần đầu vào năm 2013. Sau đó, các học giả đã đề xuất một số phương pháp khác để tạo ra các mẫu đối nghịch. Ví dụ, tấn công CW được đề xuất bởi Carlini có thể đạt tới tỉ lệ thành công 100% bằng cách sử dụng các nhiễu loạn nhỏ và thành công vượt qua hầu hết các cơ chế phòng thủ.
- Tấn công vật lý: Ngoài các tập tin hình ảnh kỹ thuật số gây nhiễu, Eykholt và cộng sự, trong bài trình bày "Robust physicalworld attacks on deep learning models" tại Hội thảo Computer Vision and Pattern Recognition (CVPR) năm 2018, đã mô tả việc sửa đổi các biển báo giao thông để đánh lừa thuật toán AI nhận dạng biển báo giao thông, khiến cho biển báo "Cấm đi" được nhận diện thành "Giới hạn tốc độ 45 km". Ngược với các mẫu đối nghịch trong thế giới kỹ thuật số, các mẫu trong thế giới vật lý phải được thu phóng, cắt, xoay và chống nhiễu.
- Khả năng dịch chuyển và tấn công black-box: Để tạo ra các mẫu đối nghịch, kẻ tấn công cần thu thập các tham số của mô hình AI, tuy nhiên trong một số trường hợp việc này là rất khó. Papernot và cộng sự, trong bài viết "Transferability in machine learning: from phenomena to black-box attacks using adversarial samples" năm 2016, thấy rằng một mẫu đối nghịch được tạo ra cho một mô hình có thể được dùng để đánh lừa một mô hình khác, miễn là dữ liệu huấn luyện của hai mô hình giống nhau. Kẻ tấn công có thể khai thác khả năng dịch chuyển này để thực thi các cuộc tấn công black-box mà không cần biết các tham số của mô hình AI. Để làm điều đó, kẻ tấn công truy vấn một mô hình nhiều lần, sử dụng kết quả truy vấn để huấn luyện một "mô hình thay thế" và cuối cùng sử dụng mô hình thay thế để tạo ra các mẫu đối nghịch, có thể được sử dụng để đánh lừa mô hình ban đầu.
Phá hoại (Poisoning)
Các hệ thống AI thường được huấn luyện lại bằng dữ liệu mới thu thập được sau khi triển khai để thích ứng với các thay đổi trong phân phối đầu vào. Ví dụ, một Hệ thống phát hiện xâm nhập (IDS) liên tục thu thập mẫu trên mạng và huấn luyện lại mô hình để phát hiện các cuộc tấn công mới. Trong cuộc tấn công phá hoại, kẻ tấn công có thể chèn các mẫu được tạo ra để làm nhiễm bẩn dữ liệu huấn luyện khiến cho hệ thống AI không hoạt động bình thường nữa – ví dụ, không thể phát hiện các cuộc tấn công. Deep learning yêu cầu số lượng lớn mẫu huấn luyện, vì thế không thể đảm bảo chất lượng của các mẫu. Jagielski và cộng sự, trong bài trình bày "Manipulating machine learning: Poisoning attacks and countermeasures for regression learning" tại hội thảo chuyên đề Bảo mật và Quyền riêng tư do IEEE tổ chức năm 2018, nhận thấy rằng việc trộn một số lượng nhỏ các mẫu đối nghịch với các mẫu huấn luyện có thể ảnh hưởng đáng kể đến độ chính xác của các mô hình AI. Các tác giả đưa ra ba loại tấn công phá hoại: tấn công gradient tối ưu, tấn công tối ưu toàn cầu và tấn công tối ưu hóa thống kê. Các cuộc tấn công này nhắm vào các bộ dữ liệu chăm sóc sức khỏe, cho vay và bất động sản để ảnh hưởng đến suy đoán của các mô hình AI trên các mẫu mới - ảnh hưởng đến liều lượng, quy mô cho vay/lãi suất, và dự đoán giá nhà đất. Bằng cách thêm 8% dữ liệu huấn luyện độc hại, kẻ tấn công có thể gây ra thay đổi tới 75% liều lượng thuốc được đề xuất cho một nửa số bệnh nhân.Cửa hậu (Backdoor)
Giống như các phần mềm truyền thống, backdoors có thể được nhúng vào các mô hình AI. Chỉ có người tạo ra mới biết cách kích hoạt chúng; những người khác sẽ không biết đến sự tồn tại của chúng và cũng không thể kích hoạt chúng. Không giống như phần mềm truyền thống, một mô hình mạng nơ-ron chỉ bao gồm một tập các tham số, không có mã nguồn. Do đó, backdoors trong các mô hình AI khó phát hiện hơn. Các backdoors này thường được cấy vào bằng cách thêm một số nơ-ron cụ thể vào mô hình mạng nơ-ron. Một mô hình có backdoors phản hồi giống như mô hình ban đầu đối với đầu vào bình thường, nhưng trên một số đầu vào đặc biệt, các phản hồi được điều khiển bởi backdoor. Gu và cộng sự, trong bài trình bày "Badnets: Identifying vulnerabilities in the machine learning model supply chain" tại NIPS MLSec Workshop năm 2017, đã đề xuất một phương pháp nhúng backdoors trong các mô hình AI. Các backdoors chỉ có thể được kích hoạt khi một hình ảnh đầu vào có chứa một hình mẫu cụ thể và, từ mô hình, rất khó để tìm thấy mẫu hoặc thậm chí phát hiện xem một backdoor có tồn tại hay không. Hầu hết các cuộc tấn công này xảy ra trong quá trình tạo hoặc truyền các mô hình.Trích xuất mô hình (Model Extraction)
Trong một cuộc tấn công trích xuất mô hình hoặc dữ liệu huấn luyện, kẻ tấn công sẽ phân tích đầu vào, đầu ra và thông tin bên ngoài của hệ thống để suy đoán các tham số hoặc dữ liệu huấn luyện của mô hình. Tương tự như khái niệm "Phần mềm như một dịch vụ (SaaS)" do các nhà cung cấp dịch vụ đám mây đề xuất, "AI như một dịch vụ (AIaaS)" được các nhà cung cấp dịch vụ AI đề xuất để cung cấp các dịch vụ huấn luyện mô hình, dự đoán, v.v... Các dịch vụ này hoàn toàn mở và người dùng có thể sử dụng API để thực hiện nhận dạng hình ảnh và giọng nói. Tramèr và nhóm của ông, trong bày trình bày "Stealing Machine Learning Models via Prediction APIs" tại hội thảo chuyên đề về bảo mật của USENIX năm 2016, đã phát triển một cuộc tấn công trong đó kẻ tấn công đã gọi API AIaaS nhiều lần để đánh cắp các mô hình AI. Các cuộc tấn công này đã gây ra hai vấn đề. Đầu tiên là hành vi trộm cắp tài sản trí tuệ. Thu thập mẫu và huấn luyện mô hình đòi hỏi nhiều nguồn lực, vì vậy các mô hình đã được huấn luyện là tài sản trí tuệ quan trọng. Vấn đề thứ hai là cuộc tấn công né tránh black-box đã đề cập ở trên. Kẻ tấn công có thể tạo ra các mẫu đối nghịch bằng cách sử dụng các mô hình được trích xuất.Phòng thủ bảo mật AI phân tầng
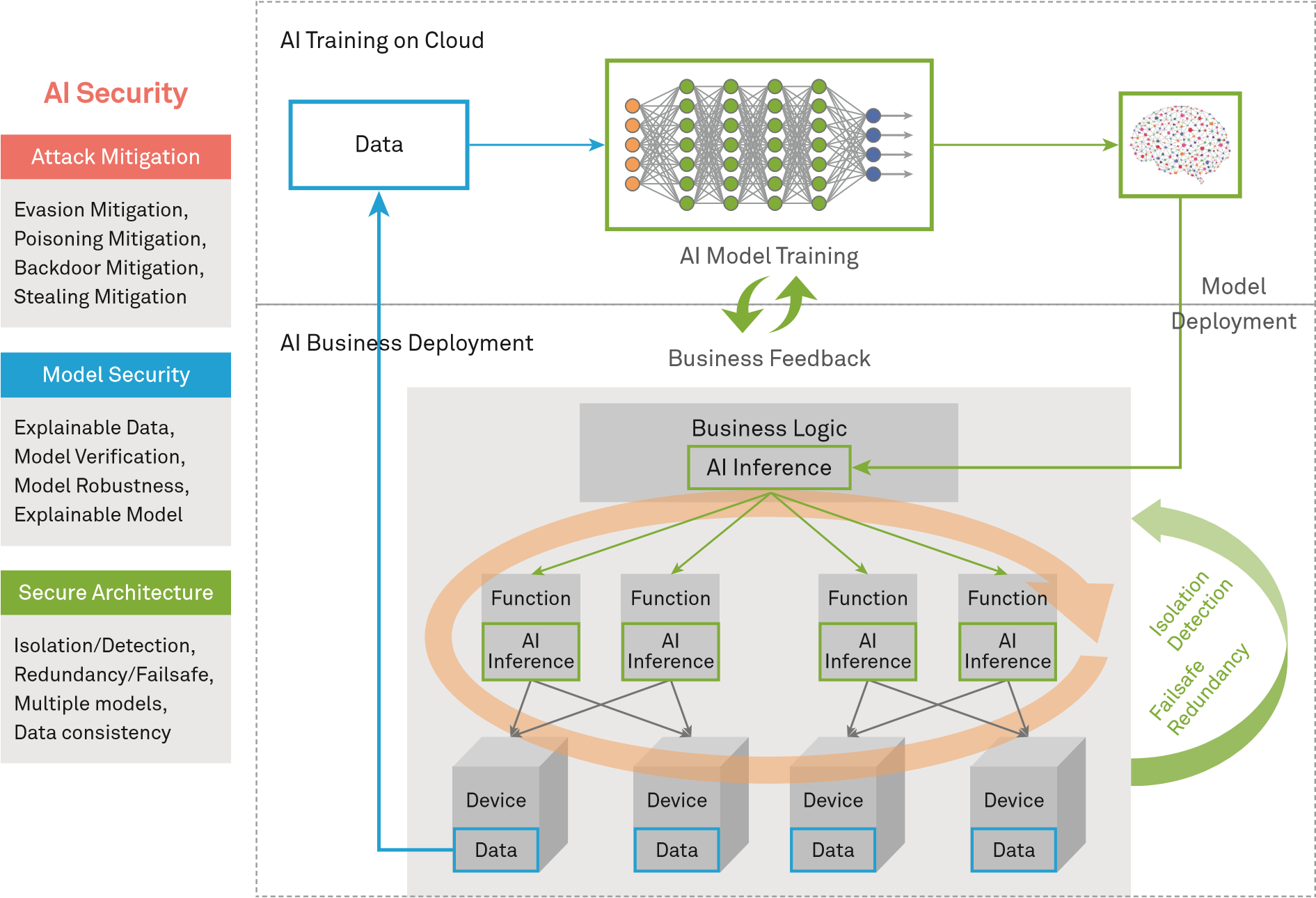
Để giải quyết các thách thức bảo mật AI, chúng tôi đề xuất ba lớp phòng thủ, được mình họa ở hình dưới đây, để triển khai các hệ thống AI như sau:- Giảm thiểu tấn công: Thiết kế cơ chế phòng thủ đối với các cuộc tấn công đã biết.
- Bảo mật mô hình: Nâng cao tính mạnh mẽ của mô hình bằng các cơ chế như xác thực mô hình.
- Bảo mật cấu trúc: Xây dựng một cấu trúc an toàn với nhiều cơ chế bảo mật để đảm bảo an toàn bảo mật.
Phòng thủ chống lại tấn công bảo mật AI
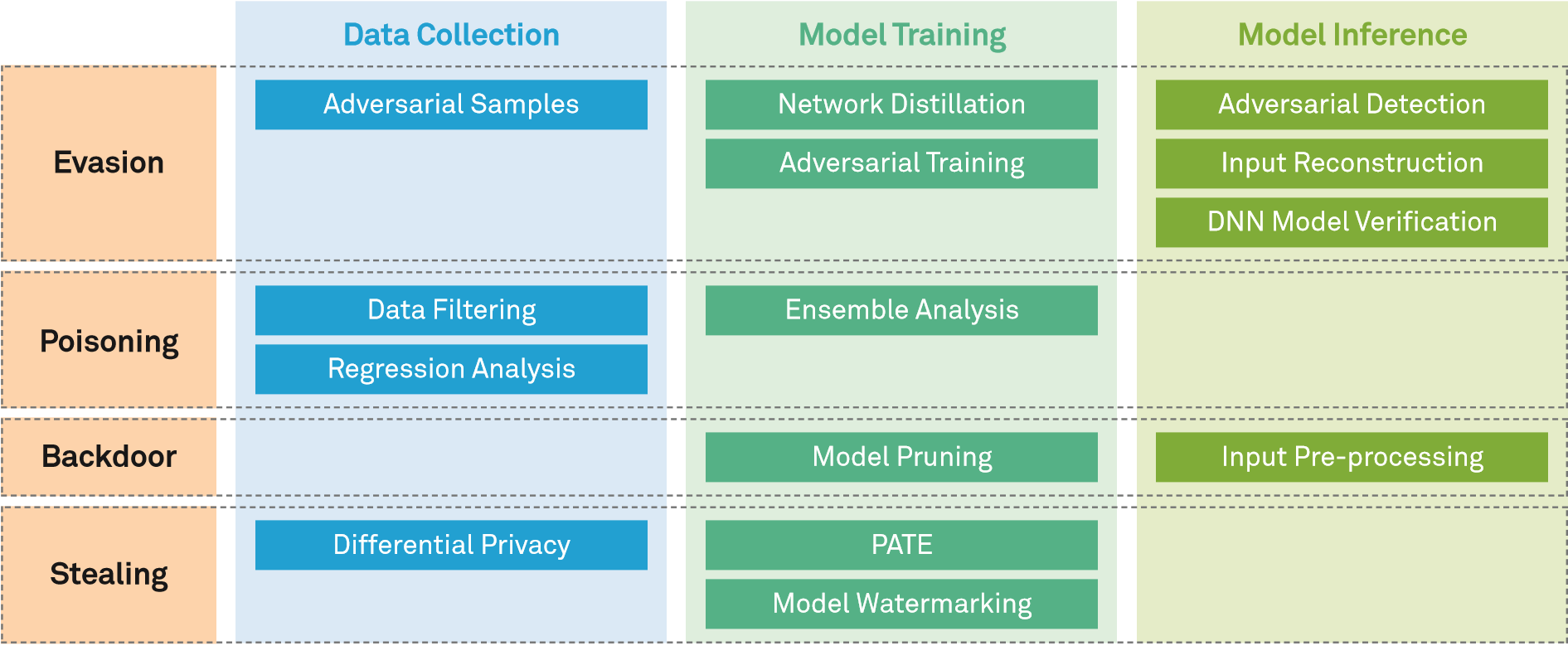
Nhiều biện pháp đối phó đã được đưa ra để giảm thiểu các cuộc tấn công tiềm ẩn. Hình dưới đây cho thấy các công nghệ phòng thủ khác nhau được sử dụng bởi các hệ thống AI trong quá trình thu thập dữ liệu, huấn luyện mô hình và dự đoán mô hình.
Kỹ thuật phòng thủ đối với tấn công evasion
- Chắt lọc mạng: Các kỹ thuật này hoạt động bằng cách ghép nhiều DNNs trong pha huấn luyện mô hình, từ đó kết quả phân loại sinh ra bởi một DNN được sử dụng để huấn luyện DNN tiếp theo. Bài trình bày "Distillation as a defense to adversarial perturbations against deep neural networks", tại hội thảo chuyên đề IEEE Symposium on Security and Privacy (S&P) năm 2016, nhận thấy rằng việc chuyển giao kiến thức có thể làm giảm độ nhạy của mô hình AI đối với các nhiễu loạn nhỏ và cải thiện độ mạnh mẽ của mô hình. Vì thế, họ đề xuất sử dụng kỹ thuật chắt lọc mạng để chống lại các cuộc tấn công evasion. Thông qua các thử nghiệm trên bộ dữ liệu của MNIST và CIFAR-10, họ thấy rằng các kỹ thuật này có thể làm giảm tỷ lệ thành công của một số cuộc tấn công (như Jacobian-based Saliency Map Attacks).
- Huấn luyện đối nghịch: Kỹ thuật này hoạt động bằng cách sinh các mẫu đối nghịch sử dụng các phương pháp tấn công đã biết trong pha huấn luyện mô hình, sau đó thêm các mẫu này vào bộ dữ liệu huấn luyện, và thực hiện huấn luyện lại để tạo ra một mô hình mới có khả năng chống lại tấn công gây nhiễu. Kỹ thuật này không chỉ tăng cường độ mạnh mẽ mà còn tăng độ chính xác và khả năng chuẩn hóa của mô hình mới.
- Phát hiện mẫu đối nghịch: Kỹ thuật này nhận diện các mẫu đối nghịch bằng cách thêm một mô hình phát hiện bên ngoài hoặc một thành phần phát hiện của mô hình gốc trong giai đoạn suy đoán. Trước khi một mẫu được đưa vào mô hình gốc, mô hình phát hiện sẽ xác định xem mẫu đó có phải là mẫu đối nghịch không. Ngoài ra, mô hình phát hiện có thể trích xuất thông tin liên quan ở mỗi lớp của mô hình ban đầu để thực hiện phát hiện dựa trên thông tin đã được trích xuất. Các mô hình phát hiện có thể xác định các mẫu đối nghịch dựa trên các tiêu chí khác nhau. Ví dụ, sự khác biệt giữa các mẫu đầu vào và dữ liệu thông thường có thể được sử dụng làm tiêu chí; và các đặc điểm phân phối của các mẫu đối nghịch và lịch sử các mẫu đầu vào có thể được sử dụng làm cơ sở để xác định các mẫu đối nghịch.
- Tái cấu trúc đầu vào: Kỹ thuật này hoạt động bằng việc biến đổi các mẫu đầu vào trong giai đoạn suy đoán của mô hình để chống lại tấn công evasion. Các mẫu bị biến đổi không gây ảnh hưởng đến tính năng phân loại của mô hình. Tái cấu trúc đầu vào có thể được thực thi bằng cách thêm nhiễu, loại bỏ nhiễu, hoặc sử dụng bộ mã hóa tự động để thay đổi mẫu đầu vào.
- Xác thực DNN: Tương tự với các kỹ thuật phân tích xác thực phần mềm, kỹ thuật xác thực DNN sử dụng một trình xử lý để xác thực các thuộc tính của một mô hình DNN. Ví dụ, một trình xử lý có thể xác minh rằng không có mẫu đối nghịch nào tồn tại trong một khoảng nhiễu nhất định. Tuy nhiên, xác thực DNN là bài toán có độ phức tạp NP, và hiệu quả của việc xác thực cũng khá thấp. Có thể tăng hiệu năng của kỹ thuật này bằng cách thỏa hiệp và tối ưu hóa như: ưu tiên các nút mô hình, chia sẻ thông tin xác thực và thực hiện xác thực dựa trên phân vùng.
Các kỹ thuật phòng thủ đối với tấn công poisoning
- Lọc dữ liệu huấn luyện: Kỹ thuật này tập trung vào việc kiểm soát các tập dữ liệu huấn luyện, sau đó thực hiện phát hiện và tinh lọc để ngăn chặn các cuộc tấn công poisoning gây ảnh hưởng đến các mô hình. Kỹ thuật này có thể được thực hiện bằng cách xác định các điểm dữ liệu có khả năng bị poison dựa trên các đặc điểm của nhãn và lọc các điểm đó trong quá trình huấn luyện lại, hoặc so sánh các mô hình để giảm tối thiểu các dữ liệu mẫu có thể bị khai thác và loại bỏ các dữ liệu đó.
- Phân tích hồi quy: Dựa trên các phương pháp thống kê, kỹ thuật này phát hiện các giá trị nhiễu và bất thường trong tập dữ liệu. Phương pháp này có thể được thực thi bằng nhiều cách. Ví dụ, có thể định nghĩa các hàm mất mát khác nhau để kiểm tra các giá trị bất thường, hoặc sử dụng các đặc điểm phân phối của dữ liệu.
- Phân tích tập hợp: Công nghệ này nhấn mạnh vào việc sử dụng nhiều mô hình con nhằm cải thiện hệ thống ML để chống lại các cuộc tấn công poisoning. Khi hệ thống chứa nhiều mô hình độc lập sử dụng các bộ dữ liệu huấn luyện khác nhau, xác suất hệ thống bị ảnh hưởng bởi các cuộc tấn công poisoning sẽ giảm.
Các kỹ thuật phòng thủ đối với tấn công backdoors
- Tiền xử lý đầu vào: Kỹ thuật này nhằm mục đích lọc bỏ các đầu vào có thể kích hoạt backdoors dẫn tới thay đổi kết quả suy đoán của mô hình.
- Cắt tỉa mô hình: Kỹ thuật này cắt bỏ các nơ-ron của mô hình ban đầu trong khi vẫn giữ các chức năng bình thường để giảm khả năng các nơ-ron backdoor hoạt động. Các nơ-ron tạo thành một backdoor có thể được loại bỏ bằng cách cắt tỉa để ngăn chặn các cuộc tấn công backdoor.
Các kỹ thuật phòng thủ đối với trích xuất mô hình/dữ liệu
- Private Aggregation of Teacher Ensembles (PATE): Kỹ thuật này hoạt động bằng cách phân cụm dữ liệu huấn luyện thành nhiều tập con trong pha huấn luyện mô hình, mỗi tập sẽ được dùng để huấn luyện một mô hình DNN độc lập. Các mô hình DNN độc lập sau đó sẽ được gộp lại để cùng huấn luyện một mô hình “học sinh” bằng cách bầu chọn. Kỹ thuật này đảm bảo rằng suy đoán của mô hình “học sinh” sẽ không làm lộ thông tin của dữ liệu huấn luyện, từ đó đảm bảo tính bí mật của dữ liệu huấn luyện.
- Differentially private protection: Kỹ thuật này sẽ làm nhiễu dữ liệu hoặc mô hình bằng các phương pháp bảo mật khác nhau trong giai đoạn huấn luyện mô hình. Ví dụ, bài trình bày "Deep learning with differential privacy" tại hội thảo ACM SIGSAC Conference on Computer and Communications Security năm 2016, đã đề xuất một phương pháp tạo gradients bằng các phương pháp khác nhau để bảo vệ tính bí mật của dữ liệu.
- Model watermarking: Kỹ thuật này nhúng các nơ-ron nhận dạng đặc biệt vào mô hình ban đầu trong giai đoạn huấn luyện mô hình. Các nơ-ron này cho phép một mẫu đầu vào đặc biệt kiểm tra xem các mô hình khác có phải bị đánh cắp từ mô hình ban đầu.
Bảo mật mô hình AI
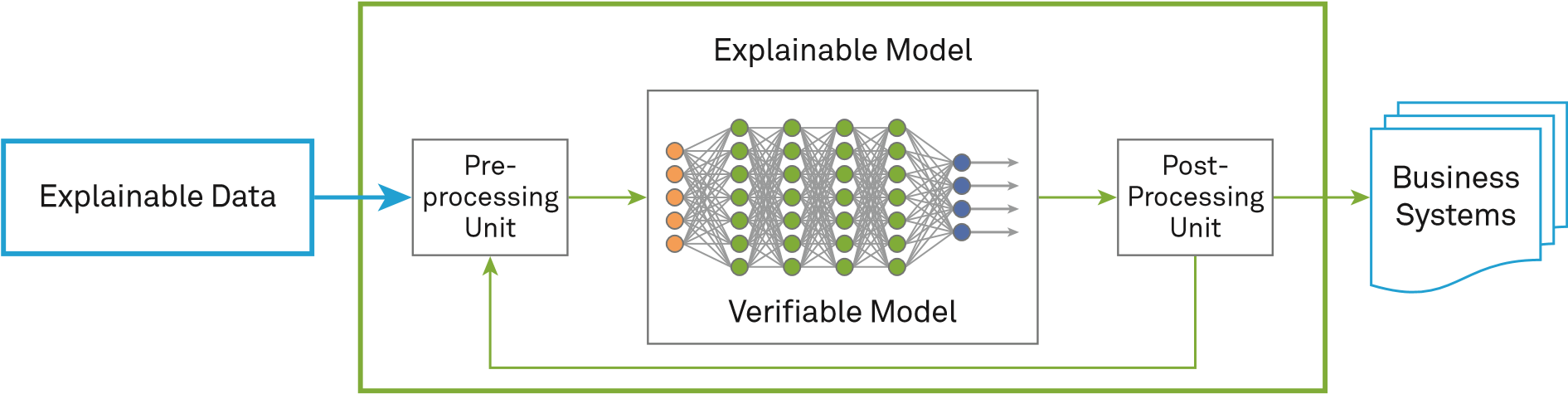
Như đã mô tả ở trên, ML đối nghịch tồn tại khá phổ biến. Tấn công evasion, poisoning, và tất cả các phương pháp lợi dụng lỗ hổng hoặc backdoors không chỉ chính xác, mà còn có khả năng chuyển đổi mạnh mẽ, dẫn đến nguy cơ cao các mô hình AI đưa ra các đánh giá sai lệch. Vì vậy, ngoài việc phòng thủ trước các dạng tấn công đã biết, độ bảo mật của chính các mô hình AI cũng cần được tăng cường để tránh thiệt hại gây ra bởi các cuộc tấn công tiềm tàng khác. Hình dưới đây minh họa một số đề xuất về việc cải tiến mô hình:
Khả năng phát hiện mô hình: Tương tự với việc phân tích các chương trình truyền thống trong công nghệ phần mềm, các mô hình AI cũng có thể được kiểm tra bằng một số kỹ thuật đối nghịch như phương pháp kiểm tra black-box và white-box. Tuy nhiên, các công cụ kiểm thử hiện nay thường dựa trên các tập dữ liệu mở có số lượng mẫu hạn chế và không thể bao phủ hết các trường hợp khi triển khai thực tế. Hơn nữa, các kỹ thuật huấn luyện đối nghịch có thể tiêu tốn rất nhiều tài nguyên trong quá trình huấn luyện lại. Do đó, trước khi các mô hình AI được triển khai trên bất kỳ hệ thống nào, cần phải thực hiện kiểm tra an toàn bảo mật trên các mô hình DNN. Ví dụ, một đơn vị tiền xử lý có thể được dùng để lọc các mẫu độc hại trước khi đưa vào huấn luyện, hoặc một đơn vị hậu xử lý có thể được thêm vào để kiểm tra tính toàn vẹn của đầu ra nhằm giảm kết quả dương tính sai. Với các phương pháp này, chúng ta có thể tăng cường sự mạnh mẽ của các hệ thống AI trước khi triển khai.
Khả năng xác thực mô hình: Các mô hình DNN hoạt động tốt hơn nhiều so với các kỹ thuật ML truyền thống (ví dụ, tỉ lệ phân loại chính xác cao hơn và tỉ lệ dương tính sai thấp hơn). Vì thế, các mô hình DNN thường được sử dụng rộng rãi trong các ứng dụng nhận diện giọng nói và hình ảnh. Tuy nhiên, cần phải cẩn trọng khi áp dụng mô hình AI vào các ứng dụng bảo mật và an toàn như lái xe tự động hoặc tự động chuẩn đoán y tế. Xác thực các mô hình DNN có thể đảm bảo an toàn ở một mức độ nào đó. Xác thực mô hình thường yêu cầu hạn chế ánh xạ giữa không gian đầu vào và không gian đầu ra để xác định xem đầu ra có nằm trong một phạm vi nhất định hay không. Tuy nhiên, vì các phương pháp xác thực và học dựa trên tối ưu hóa thống kê thường không thể bao phủ tất cả các phân phối dữ liệu, các trường hợp như các mẫu đối nghịch vẫn tồn tại. Trong tình huống này, việc thực hiện các biện pháp bảo vệ cụ thể trong triển khai thực tế là tương đối khó khăn. Việc phòng chỉ có thể được thực hiện khi nguyên tắc làm việc cơ bản của các mô hình DNN được hiểu đầy đủ.
Khả năng giải thích mô hình: Hiện tại, hầu hết các mô hình AI đều được xem như là các hệ thống black-box phức tạp, trong đó các quá trình ra quyết định, logic biện chứng và cơ sở suy đoán đều khó có thể diễn giải đầy đủ. Trong một số ứng dụng, như chơi cờ vua và dịch thuật, chúng ta cần hiểu tại sao máy lại đưa ra lựa chọn này hoặc lựa chọn kia nhằm đảm bảo sự tương tác tốt hơn giữa con người và máy móc. Tuy nhiên, việc không thể giải thích được hệ thống AI không đem lại vấn đề gì lớn cho các ứng dụng này. Một máy dịch thuật có thể tiếp tục là một hệ thống black-box phức tạp chừng nào nó vẫn đưa ra kết quả dịch tốt, không cần biết tại sao nó lại dịch như vậy. Mặc dù vậy, trong một số trường hợp, việc không giải thích được các hệ thống AI có thể đem lại rủi ro về mặt pháp lý hoặc kinh doanh. Ví dụ, trong các hệ thống phân tích bảo hiểm và cho vay, nếu hệ thống AI không đưa ra được cơ sở cho các kết quả phân tích đó, nó có thể bị cáo buộc là không công bằng; trong các hệ thống y tế, để thực hiện chính xác các tiến trình dựa trên kết quả phân tích của AI, cơ sở để đưa ra kết quả phân tích cũng cần được đưa ra. Chẳng hạn, chúng ta hy vọng rằng một hệ thống AI có thể phân tích xem liệu bệnh nhân có mắc bệnh ung thư hay không, và hệ thống cũng phải cho chúng ta biết tại sao nó lại đưa ra kết luận như vậy. Hơn nữa, việc thiết kế một mô hình an toàn mà không hiểu về nguyên lý hoạt động của nó gần như là bất khả thi. Tăng cường khả năng giải thích của các hệ thống AI giúp phân tích các lỗ hổng logic hoặc điểm mù dữ liệu của chúng, từ đó cải thiện tính bảo mật của các hệ thống AI.
Khả năng giải thích mô hình cũng có thể được thực hiện trong ba giai đoạn:
- "Dữ liệu có thể giải thích được" trước khi lập mô hình: Do các mô hình được huấn luyện bằng dữ liệu, việc giải thích hành vi của một mô hình có thể bắt đầu từ việc phân tích dữ liệu được sử dụng để huấn luyện mô hình. Nếu có thể tìm ra một số đặc điểm đại diện từ tập dữ liệu huấn luyện, một số đặc điểm cần thiết có thể được lựa chọn để xây dựng mô hình trong quá trình huấn luyện. Thông qua các đặc điểm này, có thể giải thích được đầu vào và đầu ra của mô hình.
- Xây dựng một "mô hình có thể giải thích được": Một phương pháp là bổ sung cấu trúc AI bằng cách kết hợp nó với ML truyền thống. Sự kết hợp này có thể cân bằng hiệu quả của kết quả học với khả năng giải thích của mô hình học và cung cấp một khuôn mẫu cho việc học có thể giải thích được. Một cơ sở lý thuyết quan trọng của các phương pháp ML truyền thống là thống kê. Hướng tiếp cận đã được sử dụng rộng rãi và cung cấp khả năng giải thích cho rất nhiều lĩnh vực máy tính, như xử lý ngôn ngữ tự nhiên, nhận diện giọng nói, nhận diện hình ảnh, truy xuất thông tin và nhận diện thông tin sinh trắc học.
- Phân tích các mô hình đã được thành lập: Hướng tiếp cận này tìm cách phân tích sự phụ thuộc giữa đầu vào, đầu ra và thông tin trung gian của các mô hình AI để phân tích và xác thực logic của mô hình. Theo tài liệu, có cả phương pháp phân tích mô hình chung có thể áp dụng cho nhiều loại mô hình, như phương pháp Giải thích mô hình bất khả tri cục bộ (LIME) trong bài trình bày "Why should I trust you?: Explaining the predictions of any classifier" tại hội thảo ACM international conference on knowledge discovery and data mining (KDD) năm 2016, và các phương pháp phân tích mô hình cụ thể có thể phân tích xây dựng một mô hình cụ thể theo chiều sâu.
Kiến trúc bảo mật của các dịch vụ AI
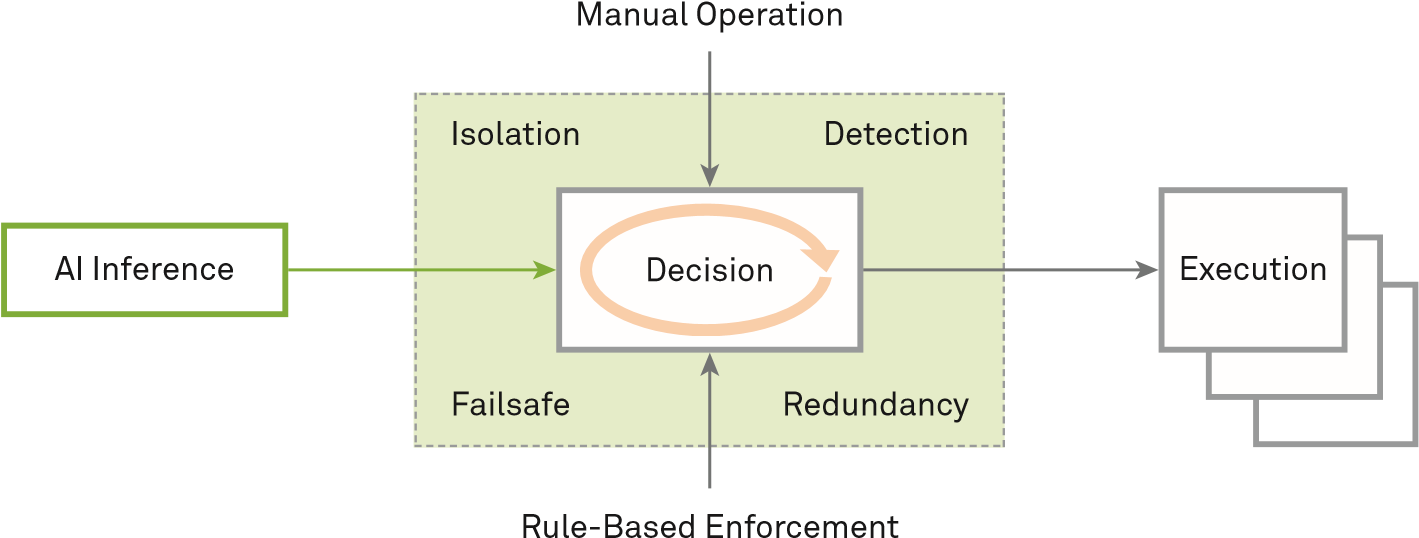
Khi phát triển các hệ thống AI, chúng ta cần phải chú ý đến các rủi ro an toàn bảo mật tiềm ẩn của chúng; tăng cường cơ chế phòng ngừa và các điều kiện ràng buộc; giảm thiểu rủi ro; và đảm bảo sự phát triển an toàn, đáng tin cậy và có thể kiểm soát của AI. Khi áp dụng các mô hình AI, chúng ta cần phân tích và xác định các rủi ro khi sử dụng các mô hình AI dựa trên các đặc điểm và kiến trúc của các dịch vụ cụ thể, và thiết kế một kiến trúc bảo mật AI mạnh mẽ và giải pháp triển khai sử dụng các cơ chế bảo mật liên quan tới Cô lập (Isolation), Phát hiện (Detection), Dự phòng (Failsafe) và Dư thừa (Redundancy). Trong lái xe tự động, nếu một hệ thống AI đưa ra quyết định không chính xác đối với các hoạt động quan trọng như phanh, rẽ và tăng tốc, hệ thống có thể gây thiệt hại nghiêm trọng tới con người và tài sản. Vì thế, chúng ta cần phải đảm bảo tính an toàn của hệ thống AI đối với các thao tác quan trọng. Việc kiểm thử bằng cách phương pháp bảo mật khác nhau là rất quan trọng, nhưng việc mô phỏng không thể đảm bảo rằng các hệ thống AI sẽ không gặp trục trặc trong các tình huống thực tế. Trong rất nhiều ứng dụng, rất khó để tìm được một hệ thống AI luôn đưa ra kết quả chính xác 100%. Sự sai lệch này khiến cho việc thiết kế một kiến trúc bảo mật trở nên quan trọng hơn. Hệ thống cần cho phép các hệ thống dự phòng hoặc các trạng thái bảo mật khác hoạt động thủ công trong khi không thể đưa ra quyết định chính xác. Ví dụ, nếu một hệ thống trợ lý y tế mà AI không thể cung cấp được câu trả lời về đơn thuốc và liều lượng, hoặc phát hiện một cuộc tấn công, hệ thống nên đưa ra câu trả lời là “Tham khảo ý kiến bác sĩ” hơn là đưa ra các dự đoán không chính xác, dẫn đến nguy hiểm tới sức khỏe của bệnh nhân. Để đảm bảo an toàn, việc sử dụng đúng các cơ chế bảo mật sau dựa trên các yêu cầu kinh doanh là rất cần thiết để đảm bảo an toàn trong lĩnh vực kinh doanh AI:
- Cô lập (Isolation): Để đảm bảo tiến trình thực thi ổn định, một hệ thống AI sẽ phân tích và xác định giải pháp tối ưu và gửi nó tới hệ thống điều khiển để xác thực và thực thi. Nói chung, kiến trúc bảo mật phải cô lập các mô-đun chức năng và thiết lập các cơ chế điều khiển truy cập giữa các mô-đun. Việc cô lập các mô hình AI có thể giảm thiểu nguy cơ tấn công tới quá trình suy đoán của AI, trong khi đó việc cô lập mô-đun quyết định được tích hợp có thể làm giảm các cuộc tấn công vào mô-đun quyết định. Đầu ra của quá trình dự đoán có thể trở thành đầu vào cho mô-đun quyết định dưới dạng một đề xuất ra quyết định phụ trợ và chỉ những đề xuất được ủy quyền mới có thể đưa vào mô đun quyết định.
- Phát hiện (Detection): Thông qua việc giám sát liên tục và với một mô hình phát hiện tấn công trong kiến trúc hệ thống chính, hoàn toàn có thể phân tích trạng thái mạng và đánh giá mức độ rủi ro của hệ thống hiện tại. Khi độ rủi ro cao, hệ thống quyết định được tích hợp có thể từ chối gợi ý đến từ hệ thống tự động và chuyển quyền điều khiền lại cho con người để đảm bảo an toàn trước các cuộc tấn công.
- Dự phòng (Failsafe): Khi một hệ thống cần thực hiện các hoạt động quan trọng như lái xe tự động có AI hỗ trợ hoặc phẫu thuật y tế, cần phải có kiến trúc bảo mật đa cấp để đảm bảo an ninh cho toàn bộ hệ thống. Sự chính xác của các kết quả dự đoán bởi hệ thống AI phải được phân tích. Khi độ chính xác của kết quả thấp hơn một ngưỡng nhất định, hệ thống sẽ quay trở lại các công nghệ dựa trên quy tắc thông thường hoặc xử lý thủ công.
- Dư thừa (Redundancy): Có nhiều quyết định kinh doanh và dữ liệu được liên kết với nhau. Một phương pháp khả thi để đảm bảo tính bảo mật của các mô hình AI là phân tích xem liệu liên kết có bị phá hủy hay không. Một kiến trúc đa mô hình có thể được thiết lập cho các ứng dụng quan trọng, do đó, một lỗi trong một mô hình sẽ không làm cho cả hệ thống đưa ra quyết định không hợp lệ. Ngoài ra, kiến trúc đa mô hình phần lớn có thể làm giảm khả năng hệ thống bị xâm phạm hoàn toàn bởi một cuộc tấn công, do đó cải thiện sự mạnh mẽ của toàn bộ hệ thống.
Hợp tác vì một tương lai an toàn và thông minh
Các ngành học AI khác nhau, bao gồm thị giác máy tính, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên, nhận thức và lý luận, lý thuyết trò chơi, vẫn đang trong giai đoạn phát triển ban đầu. Các hệ thống học sâu tận dụng dữ liệu lớn để phân tích thống kê đã mở rộng ranh giới của AI, nhưng chúng cũng thường được coi là "thiếu nhận thức thông thường", đó là trở ngại lớn nhất đối với nghiên cứu AI hiện tại. AI có thể vừa bị điều khiển bởi dữ liệu, vừa bị điều khiển bởi tri thức. Sự đột phá của AI thế hệ tiếp theo nằm ở dự đoán tri thức.
Dù bước tiếp theo là gì, sự phổ biến và nâng cao của AI đòi hỏi phải đảm bảo an toàn bảo mật. Tài liệu này tập trung vào hai loại tấn công và phòng thủ đối với AI. Đầu tiên, ảnh hưởng đến tính đúng đắn của các quyết định AI: Kẻ tấn công có thể phá hoại hoặc kiểm soát hệ thống AI hoặc cố ý thay đổi đầu vào để hệ thống đưa ra quyết định mà kẻ tấn công mong muốn. Thứ hai, những kẻ tấn công có thể đánh cắp dữ liệu bí mật được sử dụng để huấn luyện một hệ thống AI hoặc trích xuất mô hình AI. Với những vấn đề này, bảo mật hệ thống AI cần được xử lý từ ba khía cạnh: giảm thiểu tấn công AI, bảo mật mô hình AI và bảo mật kiến trúc AI. Ngoài ra, tính minh bạch và khả năng giải thích của AI là nền tảng của bảo mật. Một hệ thống AI không minh bạch hoặc không thể giải thích được không thể thực hiện các nhiệm vụ quan trọng liên quan đến an toàn cá nhân và an toàn cộng đồng.
AI cũng yêu cầu xem xét bảo mật trong các lĩnh vực, chẳng hạn như luật pháp và quy định, đạo đức và giám sát xã hội. Trong những năm tới, do AI sẽ được triển khai trong các lĩnh vực giao thông và chăm sóc y tế, công nghệ "phải được giới thiệu theo cách xây dựng niềm tin và sự hiểu biết, và tôn trọng quyền con người và quyền công dân". Ngoài ra, "các chính sách và quy trình nên giải quyết các ý nghĩa về đạo đức, quyền riêng tư và bảo mật". Để kết thúc vấn đề này, các cộng đồng quốc tế nên hợp tác để thúc đẩy AI phát triển theo hướng có lợi cho nhân loại.
Trung tâm An toàn thông tin
3579 lượt xem